李沐《动手学深度学习》注意力机制
系列文章
李沐《动手学深度学习》预备知识 张量操作及数据处理
李沐《动手学深度学习》预备知识 线性代数及微积分
李沐《动手学深度学习》线性神经网络 线性回归
李沐《动手学深度学习》线性神经网络 softmax回归
李沐《动手学深度学习》多层感知机 模型概念和代码实现
李沐《动手学深度学习》多层感知机 深度学习相关概念
李沐《动手学深度学习》深度学习计算
李沐《动手学深度学习》卷积神经网络 相关基础概念
李沐《动手学深度学习》卷积神经网络 经典网络模型
李沐《动手学深度学习》循环神经网络 相关基础概念
李沐《动手学深度学习》循环神经网络 经典网络模型
目录
- 系列文章
- 一、注意力提示
-
- (一)生物学中的注意力提示
- (二)查询、键和值
- (三)注意力的可视化
- 二、注意力汇聚:Nadaraya-Waston核回归
-
- (一)生成数据集
- (二)平均汇聚
- (三)非参数注意力汇聚
- (四)带参数注意力汇聚
- 三、注意力评分函数
-
- (一)掩蔽softmax操作
- (二)评分函数一:加性注意力
- (三)评分函数二:缩放点积注意力
- 四、Bahdanau注意力
-
- (一)Bahdanau注意力模型
- (二)定义注意力解码器
- (三)训练
- 五、多头注意力
- 六、自注意力和位置编码
-
- (一)自注意力
- (二)比较卷积神经网络、循环神经网络和自注意力
- (三)位置编码
- 七、Transformer
-
- (一)模型
- (二)基于位置的前馈网络
- (三)残差连接和层规范化
- (四)编码器
- (五)解码器
- (六)训练
教材:李沐《动手学深度学习》
一、注意力提示
(一)生物学中的注意力提示
按照威廉·詹姆斯提出的双组件框架,生物学中的注意力提示可以分为非自主性提示和自主性提示,前者基于突出性,后者则依赖于意识。
-
非自主性提示是基于环境中物体的突出性和易见性

-
自主性提示是基于认知和意识的控制

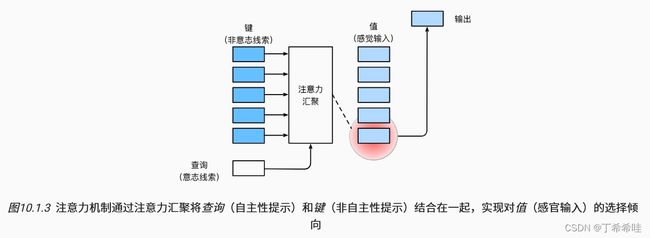
(二)查询、键和值
注意力机制:(注意力机制与全连接层或者汇聚层的区别源于增加的自主提示)
- 查询: 类比于自主性提示
- 键: 类比于非自主性提示
- 值: 类比于感官输入
- 注意力机制采用注意力汇聚的方式对给定的查询与键进行匹配,从而得到最匹配的值
(三)注意力的可视化
注意力汇聚得到的是加权平均的总和值, 其中权重是在给定的查询和不同的键之间计算得出的。
import torch
from d2l import torch as d2l
定义show_heatmaps函数可视化注意力权重:
#@save
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),
cmap='Reds'):
"""显示矩阵热图"""
d2l.use_svg_display()
num_rows, num_cols = matrices.shape[0], matrices.shape[1]
fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,
sharex=True, sharey=True, squeeze=False)
for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)
if i == num_rows - 1:
ax.set_xlabel(xlabel)
if j == 0:
ax.set_ylabel(ylabel)
if titles:
ax.set_title(titles[j])
fig.colorbar(pcm, ax=axes, shrink=0.6);
二、注意力汇聚:Nadaraya-Waston核回归
(一)生成数据集
利用非线性函数 y i = 2 s i n ( x i ) + x i 0.8 + ϵ y_i=2sin(x_i)+x_i^{0.8}+\epsilon yi=2sin(xi)+xi0.8+ϵ 生成一个人工数据集:
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本
def f(x):
return 2 * torch.sin(x) + x**0.8
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出
x_test = torch.arange(0, 5, 0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出
n_test = len(x_test) # 测试样本数
n_test
(二)平均汇聚
基于平均汇聚计算所有训练样本输出值的平均值(没有考虑输入):
f ( x ) = 1 n ∑ i = 1 n y i f(x)=\frac{1}{n}\sum_{i=1}^ny_i f(x)=n1i=1∑nyi
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)
(三)非参数注意力汇聚
Nadaraya-Watson核回归:
- K K K是核,根据输入的位置对输出 y i y_i yi进行加权
f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i f(x)=\sum_{i=1}^n\frac{K(x-x_i)}{\sum_{j=1}^nK(x-x_j)}y_i f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi
基于 Nadaraya-Watson核回归的注意力汇聚公式:
- x x x是查询, ( x i , y i ) (x_i,y_i) (xi,yi)是键值对
- α ( x , x i ) \alpha (x,x_i) α(x,xi)是查询 x x x和键 x i x_i xi 之间的关系,即注意力权重
- 注意力权重分配给每一个对应值 y i y_i yi
f ( x ) = ∑ i = 1 n α ( x , x i ) y i f(x)=\sum_{i=1}^n\alpha (x,x_i)y_i f(x)=i=1∑nα(x,xi)yi
高斯核:
K ( u ) = 1 2 π e x p ( − u 2 2 ) K(u)=\frac{1}{\sqrt{2\pi}}exp(-\frac{u^2}{2}) K(u)=2π1exp(−2u2)
将高斯核代入注意力汇聚公式:
- 键 x i x_i xi越是接近给定的查询 x x x, 分配给这个键 x i x_i xi对应值的注意力权重就会越大, 也就“获得了更多的注意力”。

# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
# x_train包含着键。attention_weights的形状:(n_test,n_train),
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力权重
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)
(四)带参数注意力汇聚
在查询 x x x和键 x i x_i xi之间的距离乘以可学习参数 w w w:
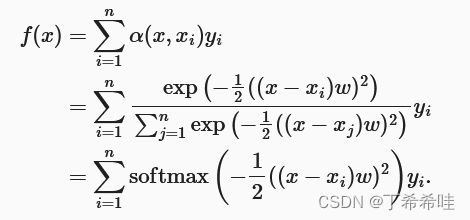
定义Nadaraya-Watson核回归的带参数注意力模型:
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries和attention_weights的形状为(查询个数,“键-值”对个数)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
将训练数据集变换为键和值用于训练注意力模型:在带参数的注意力汇聚模型中, 任何一个训练样本的输入都会和除自己以外的所有训练样本的“键-值”对进行计算, 从而得到其对应的预测输出。
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
# keys的形状:('n_train','n_train'-1)
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
# values的形状:('n_train','n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
使用平方损失函数和随机梯度下降对模型进行训练
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5])
for epoch in range(5):
trainer.zero_grad()
l = loss(net(x_train, keys, values), y_train)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
animator.add(epoch + 1, float(l.sum()))
三、注意力评分函数
注意力汇聚的输出计算成为值的加权和,由于注意力权重是概率分布, 因此加权和其本质上是加权平均值。
- 注意力汇聚函数为值的加权和:
f ( q , ( k 1 , v 1 ) , . . . , ( k m , v m ) ) = ∑ i = 1 m α ( q , k i ) v i f(q,(k_1,v_1),...,(k_m,v_m))=\sum_{i=1}^m\alpha (q,k_i)v_i f(q,(k1,v1),...,(km,vm))=i=1∑mα(q,ki)vi - 注意力权重是查询 q q q和键 k i k_i ki通过注意力评分函数 a a a映射成标量后经过softmax运算得到的:
α ( q , k i ) = s o f t m a x ( a ( q , k i ) ) = e x p ( a ( q , k i ) ) ∑ j = 1 m e x p ( a ( q , k j ) ) \alpha (q,k_i)=softmax(a(q,k_i))=\frac{exp(a(q,k_i))}{\sum_{j=1}^mexp(a(q,k_j))} α(q,ki)=softmax(a(q,ki))=∑j=1mexp(a(q,kj))exp(a(q,ki))

(一)掩蔽softmax操作
掩蔽softmax操作: 任何超出有效长度的位置都被掩蔽并置为0。(仅将有意义的词元作为值来获取注意力汇聚)
#@save
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
(二)评分函数一:加性注意力
加性注意力作为评分函数:用于查询和键是不同长度的矢量的情况
α ( q , k ) = w v T t a n h ( W q q + W k k ) \alpha(q,k)=w_v^Ttanh(W_qq+W_kk) α(q,k)=wvTtanh(Wqq+Wkk)
#@save
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm(self.dropout(self.attention_weights), values)
(三)评分函数二:缩放点积注意力
原理:计算query和key之间的点积来作为相似度
缩放点积注意力评分函数:
a ( q , k ) = q T k / d a(q,k)=q^Tk/\sqrt d a(q,k)=qTk/d
查询 Q Q Q、键 K K K和值 V V V的缩放点积注意力:
s o f t m a x ( Q K T d ) V softmax(\frac{QK^T}{\sqrt{d}})V softmax(dQKT)V
#@save
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
四、Bahdanau注意力
(一)Bahdanau注意力模型
- t ′ t' t′:解码时间步
- T T T:输入序列的词元数
- α \alpha α:注意力权重(采用加性注意力打分函数)
- s t ′ − 1 s_{t'-1} st′−1:解码器隐状态,作为查询
- h t h_t ht:编码器隐状态,作为键和值
c t ′ = ∑ t = 1 T α ( s t ′ − 1 , h t ) h t c_{t'}=\sum_{t=1}^T\alpha(s_{t'-1},h_t)h_t ct′=t=1∑Tα(st′−1,ht)ht

(二)定义注意力解码器
AttentionDecoder类:定义带有注意力机制解码器的基本接口
#@save
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
在Seq2SeqAttentionDecoder类中实现带有Bahdanau注意力的循环神经网络解码器:
class Seq2SeqAttentionDecoder(AttentionDecoder):
#初始化解码器状态
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
(三)训练
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
五、多头注意力
多头注意力模型:
- 用独立学习得到的h组不同的线性投影来变换查询、键和值;
- 将这h组变换后的查询、键和值将并行地送到注意力汇聚中;
- 将h个注意力汇聚的输出拼接在一起, 并通过另一个可以学习的线性投影进行变换, 得到最终输出。

计算方法:
- f f f:注意力汇聚的函数(可以是加性注意力和缩放点击注意力)
h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) h_i=f(W_i^{(q)}q,W_i^{(k)}k,W_i^{(v)}v) hi=f(Wi(q)q,Wi(k)k,Wi(v)v) - h h h个头经过另一个线性变换后进行连结:
W o [ h 1 ⋮ h h ] W_o\begin{bmatrix} h_1\\ \vdots \\ h_h \\ \end{bmatrix} Wo h1⋮hh
多头注意力的实现:
导入相关库:
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
#@save
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
六、自注意力和位置编码
(一)自注意力
f ( q , ( k 1 , v 1 ) , . . . , ( k m , v m ) ) = ∑ i = 1 m α ( q , k i ) v i f(q,(k_1,v_1),...,(k_m,v_m))=\sum_{i=1}^m\alpha (q,k_i)v_i f(q,(k1,v1),...,(km,vm))=∑i=1mα(q,ki)vi
自注意力机制:
y i = f ( x i , ( x 1 , x 1 ) , . . . , ( x n , x n ) ) y_i=f(x_i,(x_1,x_1),...,(x_n,x_n)) yi=f(xi,(x1,x1),...,(xn,xn))
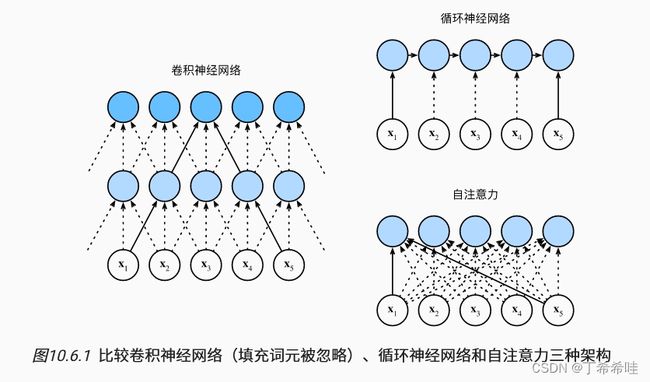
(二)比较卷积神经网络、循环神经网络和自注意力
(三)位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作。 为了使用序列的顺序信息,可以通过在输入表示中添加位置编码,来注入绝对的或相对的位置信息。
七、Transformer
Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层。
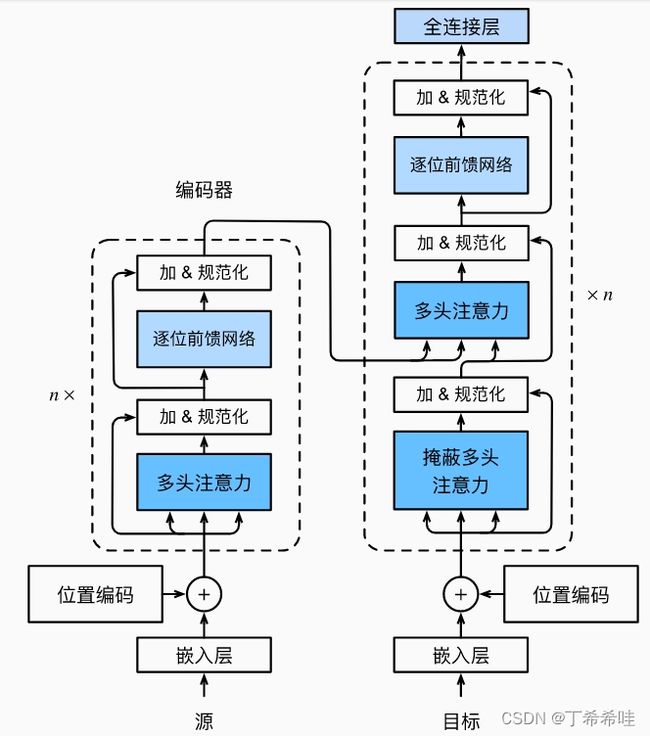
(一)模型
Transformer的编码器由多个相同的层叠加而成,每个层有两个子层:
- 第一个子层是多头自注意力汇聚
- 第二个子层是基于位置的前馈网络
- 每个子层都采用了残差连接,在残差连接的加法计算后,紧接着应用层规范化
Transformer解码器除了编码器中描述的两个子层之外,解码器在这两个子层之间插入了第三个子层(编码器-解码器注意力层):
- 编码器-解码器注意力中,查询来自前一个解码器层的输出,键和值来自整个编码器的输出
- 解码器自注意力中,查询、键和值都来自上一个解码器层的输出
(二)基于位置的前馈网络
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的(positionwise)的原因。
#@save
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
(三)残差连接和层规范化
使用残差连接和层规范化来实现AddNorm类:
#@save
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
(四)编码器
EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
#@save
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
Transformer编码器堆叠了num_layers个EncoderBlock类:
#@save
class TransformerEncoder(d2l.Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
(五)解码器
Transformer解码器也是由多个相同的层组成。在DecoderBlock类中实现的每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力。
# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
由num_layers个DecoderBlock实例组成的完整的Transformer解码器:
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
(六)训练
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)