李沐《动手学深度学习》卷积神经网络 经典网络模型
系列文章
李沐《动手学深度学习》预备知识 张量操作及数据处理
李沐《动手学深度学习》预备知识 线性代数及微积分
李沐《动手学深度学习》线性神经网络 线性回归
李沐《动手学深度学习》线性神经网络 softmax回归
李沐《动手学深度学习》多层感知机 模型概念和代码实现
李沐《动手学深度学习》多层感知机 深度学习相关概念
李沐《动手学深度学习》深度学习计算
李沐《动手学深度学习》卷积神经网络 相关基础概念
目录
- 系列文章
- 一、LeNet
-
- (一)LeNet网络架构
- (二)LeNet模型特点
- 二、深度卷积神经网络(AlexNet)
-
- (一)AlexNet与LeNet的对比
- (二)AlexNet的网络架构
- 三、使用块的网络(VGG)
-
- (一)VGG块
- (二)VGG16
- (三)VGG网络与AlexNet网络的对比
- 四、网络中的网络(NiN)
-
- (一)1x1卷积层
- (二)NiN块
- (三)NiN网络架构
- (四)NiN网络的特点
- 五、含并行连结的网络(GoogLeNet)
-
- (一)Inception块
- (二)GoogLeNet的网络架构
- (三)GooLeNet的创新点
- 六、批量规范化——BN
-
- (一)批量规范化的概念
- (二)批量规范化层
- 七、残差网络(ResNet)
-
- (一)引入背景
- (二)残差块
- (三)ResNet网络架构
- (四)ResNet网络的特点
- 八、稠密连接网络(DenseNet)
-
- (一)从ResNet到DenseNet
- (二)DenseNet模型
- (三)稠密块体:定义如何连接输入和输出
- (四)过渡层Transition Laye:控制通道数量
教材:李沐《动手学深度学习》
卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络,是机器学习利用自然图像中一些已知结构的创造性方法。
一、LeNet
LeNet首次采用了卷积层、池化层这两个全新的神经网络组件,接收灰度图像,并输出其中包含的手写数字,在手写字符识别任务上取得了瞩目的准确率。LeNet网络的一系列的版本,以LeNet-5版本最为著名,也是LeNet系列中效果最佳的版本。

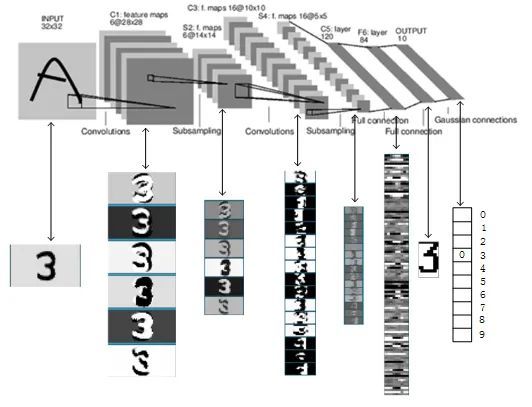
(一)LeNet网络架构
Lenet是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层,1个输出层。其中所有卷积层的卷积核都为 5x5,步长=1,池化方法都为平均池化,激活函数为 Sigmoid:
| 层结构 | 层编号 | 输入 | 输出 |
|---|---|---|---|
| 输入的二维图像(单通道) | 图片 | 32x32像素 | |
| 卷积层 | C1 | 32x32像素 | 6个28x28像素的特征图 |
| 池化层 | S2 | 28x28像素 | 6个14x14像素的特征图 |
| 激活函数 | |||
| 卷积层 | C3 | 14x14像素 | 16个10x10像素的特征图 |
| 池化层 | S4 | 10x10像素 | 16 个 5×5 大小的特征图 |
| 激活函数 | |||
| 卷积层 | C5 | 5x5像素 | 120 个 1×1 大小的特征图 |
| 全连接层 | F6 | 1x1像素 | 84个神经元 |
| 输出 | 10 个节点 |
输入层: 通过尺寸归一化,把输入图像全部转化成32×32大小,通道数为1
第一层-卷积层C1: 输入大小:32×32;输出featuremap大小:28×28
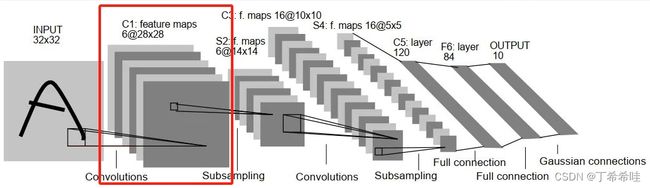
C1卷积层使用6个5x5大小的卷积核,padding=0,stride=1:
- 输出特征图大小:32-5+1=28
- 神经元数量:28×28×6
- 参数个数:(5x5+1)x6=156(由于参数(权值)共享的原因,对于同个卷积核每个神经元均使用相同的参数,其中5×5为卷积核参数,1为偏置参数)
- 连接数:训练参数×输出featuremap大小=(5×5+1)×6×28×28=122304(156为单次卷积过程连线数,28*28为输出特征层,每一个像素都由前面卷积得到,即总共经历28*28次卷积)

第二层-池化层S2(下采样): 输入大小:28x28;输出featuremap大小:14x14
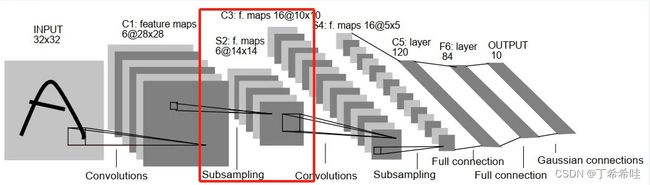
S2 层使用 6 个 2×2 大小的卷积核进行池化,padding=0,stride=2:
- 特征图大小:14x14(28/2=14)
- 参数个数:(1+1)x6=12,第一个1为最大池化中对应的2x2感受野中最大值的权重w,第二个1为偏置b
- 连接数:(2x2+1)x6x14x14=5880(2x2的感受野,1为偏置,14x14为输出特征值)
- S2 层相当于降采样层+激活层。先是降采样,然后激活函数 sigmoid 非线性输出。先对 C1 层 2x2 的视野求和,然后进入激活函数,即: s i g m o i d ( w ∑ i = 1 4 x i + b ) sigmoid(w\sum_{i=1}^4x_i+b) sigmoid(w∑i=14xi+b)。

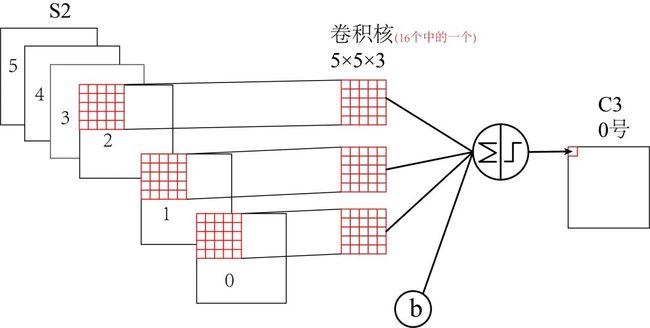
第三层-卷积层C3: 输入大小:14x14;输出featuremap大小:10x10
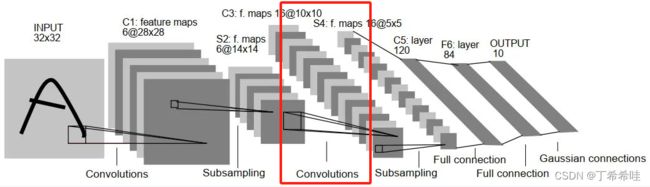
C3 层是卷积层,使用 16 个 5×5xn 大小的卷积核,padding=0,stride=1 进行卷积,但是16 个卷积核并不是都与 S2 的 6 个通道层进行卷积操作:
- C3 的前六个特征图(0,1,2,3,4,5)由 S2 的相邻三个特征图作为输入,对应的卷积核尺寸为:5x5x3;
- 接下来的 6 个特征图(6,7,8,9,10,11)由 S2 的相邻四个特征图作为输入对应的卷积核尺寸为:5x5x4;
- 接下来的 3 个特征图(12,13,14)号特征图由 S2 间断的四个特征图作为输入对应的卷积核尺寸为:5x5x4;
- 最后的 15 号特征图由 S2 全部(6 个)特征图作为输入,对应的卷积核尺寸为:5x5x6。
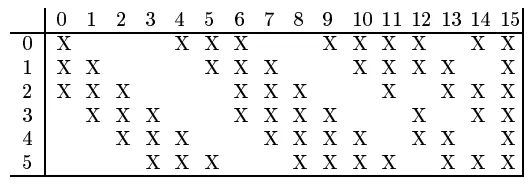
卷积核是 5×5 且具有 3 个通道,每个通道各不相同:
- 特征图大小: 16 个 10×10 大小的特征图(14-5+1=10)
- 参数个数:(5x5x3+1)x6+(5x5x4+1)x6+(5x5x4+1)x3+(5x5x6+1)x1=1516
- 连接数:1516x10x10 = 151600
第四层-池化层S4(下采样): 输入大小:10x10;输出featuremap大小:5x5
S4 层与 S2 一样也是降采样层,使用 16 个 2×2 大小的卷积核进行池化,padding=0,stride=2:
- 特征图大小:16 个 5×5 大小(10/2=5)
- 参数个数:(1+1)x16=32
- 连接数:(2x2+1)x16x5x5= 2000
第五层-卷积层C5: 输入大小:5x5;输出featuremap大小:1x1

C5 层是卷积层,使用 120 个 5×5x16 大小的卷积核,padding=0,stride=1进行卷积:
- 特征图大小:120 个 1×1 大小(5-5+1=1),相当于 120 个神经元的全连接层
- 参数个数:(5x5x16+1)x120=48120
- 连接数:48120x1x1=48120
- 与C3层不同,这里120个卷积核都与S4的16个通道层进行卷积操作
第六层-全连接层F6:
F6 层共有 84 个神经元,与 C5 层进行全连接,即每个神经元都与 C5 层的 120 个特征图相连。
F6 层有 84 个节点,对应于一个 7x12 的比特图,-1 表示白色,1 表示黑色,这样每个符号的比特图的黑白色就对应于一个编码:
- 参数个数:(120+1)*84=10164
- 连接数:(120+1)*84=10164

第七层-输出层:
最后的 Output 层也是全连接层,是 Gaussian Connections,采用了 RBF 函数(即径向欧式距离函数),计算输入向量和参数向量之间的欧式距离:
y i = ∑ j = 0 83 ( x j − w i j ) 2 y_i=\sum_{j=0}^{83}(x_j-w_{ij})^2 yi=j=0∑83(xj−wij)2
其中x是上一层输入,y是RBF的输出, i 取值从 0 到 9,j 取值从 0 到 7*12-1,w 为参数。RBF 输出的值越接近于 0,则越接近于 i,即越接近于 i 的 ASCII 编码图,表示当前网络输入的识别结果是字符 i。
- 参数个数:84*10=840
- 连接数:84*10=840
(二)LeNet模型特点
- 首次提出卷积神经网络基本框架: 卷积层,池化层,全连接层;
- 卷积层的权重共享,相较于全连接层使用更少参数,节省了计算量与内存空间;
- 卷积层的局部连接,保证图像的空间相关性;
- 使用映射到空间均值下采样,减少特征数量;
- 使用双曲线(tanh)或S型(sigmoid)形式的非线性激活函数。
二、深度卷积神经网络(AlexNet)
AlexNet是第一个在大规模视觉竞赛中击败传统计算机视觉模型的大型神经网络,它首次证明了学习到的特征可以超越手工设计的特征,一举打破了计算机视觉研究的现状。
(一)AlexNet与LeNet的对比
AlexNet和LeNet的设计理念非常相似,但也存在显著差异:
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层;
- AlexNet使用ReLU而不是sigmoid作为其激活函数(sigmoid的两个缺点:求导比较麻烦;随着网络加深会有梯度消失现象);
- AlexNet通过暂退法控制全连接层的模型复杂度减少过拟合,而LeNet只使用了权重衰减;
- AlexNet支持更高分辨率的彩色图像;
- AlexNet首次利用GPU进行网络的加速训练,并利用分组卷积突破当时GPU的显存瓶颈,多个GPU训练不但可以提高模型的训练速度,还能提升数据的使用规模;
- AlexNet使用了LRN局部响应归一化。
(二)AlexNet的网络架构
- AlexNet主要是堆砌的卷积层和池化层,最后加上全连接及softmax处理多分类任务。
- 除去输入层外,AlexNet一共包含8层:5个卷积层(C1、C2、C3、C4、C5)、2个全连接层(FC6、FC7)和1个输出层(output layer)。
- 网络结构分为上下两层,分别对应两个GPU操作过程,除了卷积层C3和3个全连接会有GPU间的交互,其它层两个GPU分别计算。

因为是两块GPU并行计算,上下两部分是一样的,所以维度计算只看下面的即可。
卷积后特征图的尺寸: N = W − F + 2 × P S + 1 N=\frac{W-F+2\times P}{S}+1 N=SW−F+2×P+1
- WxW是输入大小,FxF是卷积核大小,S为步长,P为padding的像素数
输入层: 实际图像尺寸为227x227x3
第一层-卷积层C1: 输入大小:[227, 227, 3];输出大小:[27, 27, 96]

该层的处理流程是:卷积–>ReLU–>局部响应归一化(LRN)–>池化
-
卷积:96个11x11x3的卷积核,padding=0,stride=4
- 输出:55x55x96( N = 227 − 11 + 2 × 0 4 + 1 = 55 N=\frac{227-11+2\times0}{4}+1=55 N=4227−11+2×0+1=55)
-
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中
-
局部响应归一化LRN:在深度学习中提高准确度的技术方法
- 一般是在激活、池化后进行
- LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 局部响应归一化的输出仍然是55x55x96。将其分成两组,每组大小是55x55x48,分别位于单个GPU上。
-
池化:使用3x3,stride=2的池化单元进行最大池化操作
- 输出(分为两组):27x27x48( N = 55 − 3 + 2 × 0 2 + 1 = 27 N=\frac{55-3+2\times0}{2}+1=27 N=255−3+2×0+1=27)
- 这里使用的是重叠池化,即stride小于池化单元的边长
第二层-卷积层C2: 输入大小:[27, 27, 96];输出大小:[13, 13, 256]
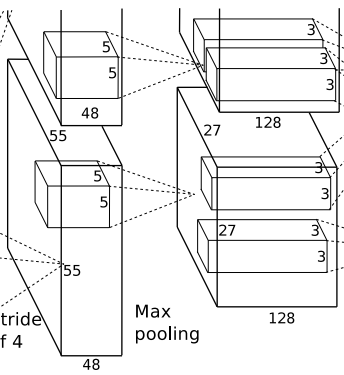
该层的处理流程是:卷积–>ReLU–>局部响应归一化(LRN)–>池化
- 卷积:两组均为128个5x5x48的卷积核,padding=2,stride=1
- 输入:27x27x48
- 输出:27x27x128( N = 27 − 5 + 2 × 2 1 + 1 = 27 N=\frac{27-5+2\times2}{1}+1=27 N=127−5+2×2+1=27)
- ReLU:将卷积层输出的FeatureMap输入到ReLU函数中
- 局部响应归一化:每组输出仍然是27x27x128
- 池化:使用3x3,stride=2的池化单元进行最大池化操作
- 输出(分为两组):13x13x128( N = 27 − 3 + 2 × 0 2 + 1 = 13 N=\frac{27-3+2\times0}{2}+1=13 N=227−3+2×0+1=13)
- 这里使用的是重叠池化,即stride小于池化单元的边长
第三层-卷积层C3: 输入大小:[13, 13, 256];输出大小:[13, 13, 192]
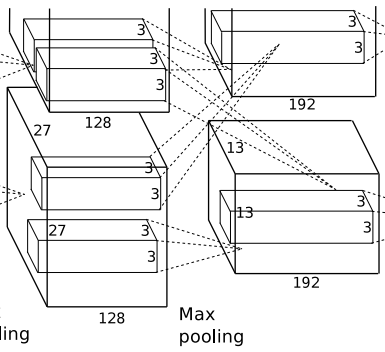 该层的处理流程是:卷积–>ReLU
该层的处理流程是:卷积–>ReLU
- 卷积:384个3x3x256的卷积核,padding=1,stride=1
- 输入:13x13x256
- 输出:13x13x384( N = 13 − 3 + 2 × 1 1 + 1 = 13 N=\frac{13-3+2\times1}{1}+1=13 N=113−3+2×1+1=13)
- ReLU:将卷积层输出的FeatureMap输入到ReLU函数中,将输出其分成两组,每组FeatureMap大小是13x13x192,分别位于单个GPU上。
第四层-卷积层C4: 输入大小:[13, 13, 192];输出大小:[13, 13, 192]

该层的处理流程是:卷积–>ReLU
- 卷积:192个3x3x192的卷积核,padding=1,stride=1
- 输入:13x13x192
- 输出:13x13x192( N = 13 − 3 + 2 × 1 1 + 1 = 13 N=\frac{13-3+2\times1}{1}+1=13 N=113−3+2×1+1=13)
- ReLU:将卷积层输出的FeatureMap输入到ReLU函数中
第五层-卷积层C5: 输入大小:[13,13,192];输出大小:[6x6x128]
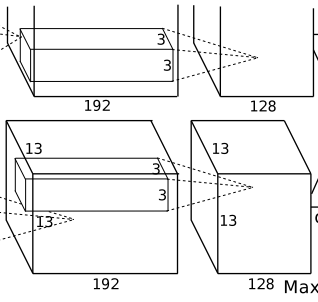
该层的处理流程是:卷积–>ReLU–>池化
- 卷积:两组均为128个3x3x192的卷积核,padding=1,stride=1
- 输入:13x13x192
- 输出:13x13x128( N = 13 − 3 + 2 × 1 1 + 1 = 13 N=\frac{13-3+2\times1}{1}+1=13 N=113−3+2×1+1=13)
- ReLU:将卷积层输出的FeatureMap输入到ReLU函数中
- 局部响应归一化:每组输出仍然是27x27x128
- 池化:使用3x3,stride=2的池化单元进行最大池化操作
- 输出(分为两组):6x6x128( N = 13 − 3 + 2 × 0 2 + 1 = 6 N=\frac{13-3+2\times0}{2}+1=6 N=213−3+2×0+1=6)
- 这里使用的是重叠池化,即stride小于池化单元的边长
第六层-全连接层FC6: 输入大小:[6,6,128];输出大小:[1,1,2048]
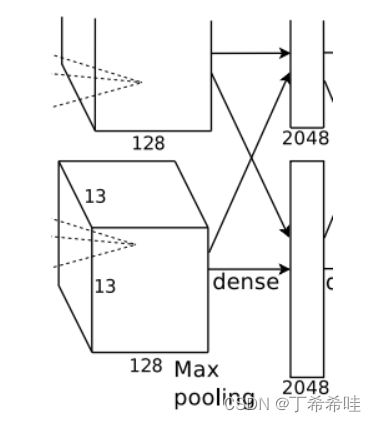 该层的流程为:(卷积)全连接 -->ReLU -->Dropout (卷积)
该层的流程为:(卷积)全连接 -->ReLU -->Dropout (卷积)
- 全连接:4096个6×6×256的卷积核进行卷积
- 输入:6x6x256
- 输出:1x1x4096( N = 6 − 6 + 2 × 0 1 + 1 = 1 N=\frac{6-6+2\times0}{1}+1=1 N=16−6+2×0+1=1)
- ReLU:这4096个神经元的运算结果通过ReLU激活函数中
- Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。4096个神经元也被均分到两块GPU上进行运算。
第七层-输出层: 输入大小:[1,1,2048];输出大小:[6x6x128]
 该层的流程为:(卷积)全连接 -->Softmax
该层的流程为:(卷积)全连接 -->Softmax
- 全连接:
- 输入:4096个神经元
- 输出:1000个神经元,这1000个神经元即对应1000个检测类别。
- Softmax:这1000个神经元的运算结果通过Softmax函数中,输出1000个类别对应的预测概率值。
三、使用块的网络(VGG)
(一)VGG块
一个VGG块:一系列卷积层+用于空间下采样的最大汇聚层

(二)VGG16
- VGG16由13个卷积层与3个全连接层组成,一共16层;
- VGG16中的13个卷积层可以分为5块:第1块卷积层由2个conv3-64组成,第2块卷积层由2个conv3-128组成,第3块卷积层由3个conv3-256组成,第4块卷积层由3个conv3-512组成,第5块卷积层由3个conv3-512组成;然后是2个FC4096,1个FC1000;
- VGG反复堆叠3×3的小卷积核和2×2的最大池化层,使用ReLU激活函数;
- 经过一次池化操作,其后卷积层的卷积核个数就增加一倍,直至到达512。
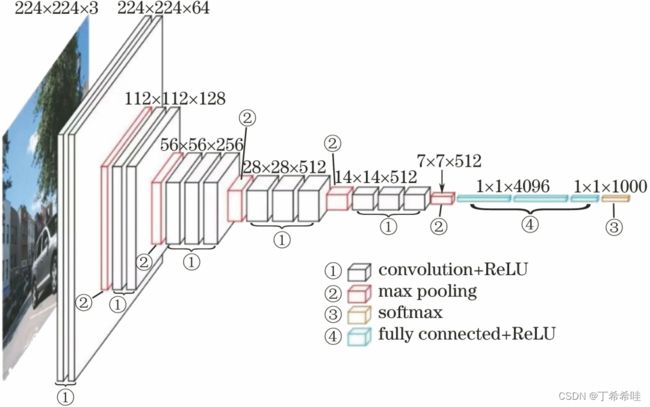
| 层结构 | 层操作 | 输入 | 输出 |
|---|---|---|---|
| 输入层 | 图片 | 224x224x3 | |
| 64通道卷积层块 | 2层3x3x64卷积;padding操作 | 224x224x3 | 224x224x64 |
| maxpooling1 | 窗口大小为2x2、步长为2 | 224x224x64 | 112x112x64 |
| 128通道卷积层块 | 2层3x3x128卷积;padding操作 | 112x112x64 | 112x112x128 |
| maxpooling2 | 窗口大小为2x2、步长为2 | 112x112x128 | 56x56x128 |
| 256通道卷积块 | 3层3x3x256卷积;padding操作 | 56x56x128 | 56x56x256 |
| maxpooling3 | 窗口大小为2x2、步长为2 | 56x56x128 | 28x28x128 |
| 512通道卷积块 | 3层3x3x256卷积;padding操作 | 28x28x128 | 28x28x512 |
| maxpooling4 | 窗口大小为2x2、步长为2 | 28x28x512 | 14x14x512 |
| 512通道卷积块 | 3层3x3x256卷积;padding操作 | 14x14x512 | 14x14x512 |
| maxpooling5 | 窗口大小为2x2、步长为2 | 14x14x512 | 7x7x512 |
| 全连接层1 | 7x7x512 | 4096 | |
| 全连接层2 | 4096 | 4096 | |
| 全连接层3 | 4096 | 1000 |
(三)VGG网络与AlexNet网络的对比
- 使用尺寸更小的3x3卷积核串联来获得更大的感受野,放弃使用11x11和5x5这样的大尺寸卷积核
- 深度更深、非线性更强,网络的参数也更少
- 去掉了AlexNet中的局部响应归一化层(LRN)层
四、网络中的网络(NiN)
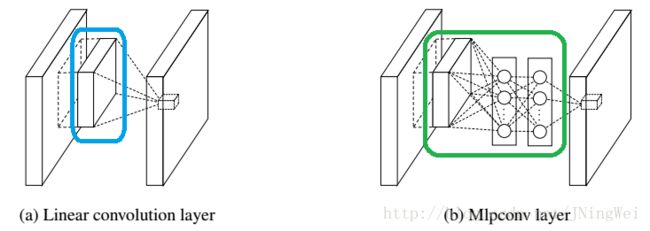
(一)1x1卷积层
- 卷积层的输入和输出通常是四维数组(样本,通道,高,宽),而全连接层的输入和输出通常是二维数组(样本,特征)。如果想在全连接层后接上卷积层,需要将全连接层的输出变换为四维;
- 1x1卷积层可以看成全连接层,其中空间维度(高和宽)上的每个元素相当于样本,通道相当于特征,从而使空间信息能够自然传递到后面的层中去。

1x1卷积层的作用:
- 降维的同时增加模型深度:减少网络模型参数,增加网络层深度,一定程度上提升模型的表征能力;
- 加入非线性:卷积层之后经过激励层,1x1的卷积在前一层的学习表示上添加了非线性激励,提升网络的表达能力。
(二)NiN块
NiN块是NiN中的基础块,以一个普通卷积层开始,后面是两个1x1的卷积层,这两个1x1卷积层充当带有ReLU激活函数的逐像素全连接层。第一层的卷积窗口形状通常由用户设置,随后的卷积窗口形状固定为1x1。
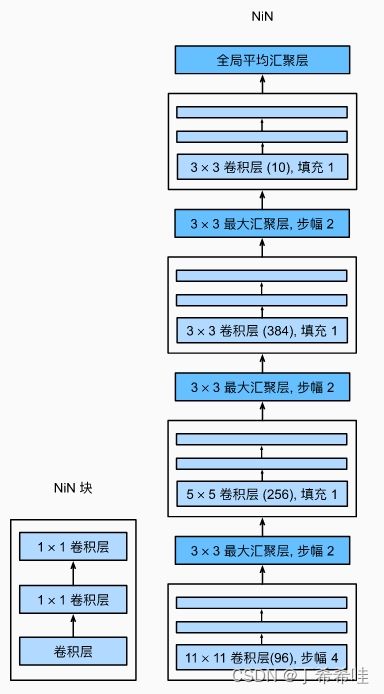
(三)NiN网络架构
Network in Network描述了一种新型卷积神经网络结构:由多个卷积层+全连接层构成的微型网络(mlpconv)来提取特征,用全局平均池化层来输出分类。
- NiN由三个mplconv层 + 一个GAP全局平均池化层组成
- 微型网络mplconv内部由多层感知机实现(其中包含1个可调整大小的conv层+2个1×1的卷积层),mpl中感知机层数是可以调整的,也可以被用在卷积层之间,个数随需调整。
- NIN网络用微型网络mlpconv层代替了传统的卷积层;用GAP代替了传统CNN模型中末尾的全连接层。

(四)NiN网络的特点
- 先前CNN中简单的线性卷积层被替换为了多层感知机(MLP,多层全连接层和非线性函数的组合),Mlpconv层可以更好地对局部特征块建模;
- 先前CNN中的全连接层被替换为了全局池化层,GAP(全局平均池化)可以用于防止过拟合,当做正则化器使用。

假设分类任务共有C个类别,先前CNN中最后一层为特征图层数共计N的全连接层,要映射到C个类别上;改为全局池化层后,最后一层为特征图层数共计C的全局池化层,恰好对应分类任务的C个类别,这样一来,就会有更好的可解释性了。
五、含并行连结的网络(GoogLeNet)
(一)Inception块
GoogLeNet中的基本卷积块被称为Inception块(Inception block)。Inception块由四条并行路径组成,4个路径从不同层面抽取信息,然后在输出通道层合并。

Inception模块的基本组成结构有四个:1x1卷积,3x3卷积,5x5卷积,3x3最大池化。
(二)GoogLeNet的网络架构
GoogLeNet可以大致分为六个部分:
- 第一部分是卷积层,包含64个7x7步长为2的卷积核,后接最大池化层。
- 第二部分是卷积层,包含64个1x1的卷积核,然后是192个3x3步长为1的卷积核,后接最大池化层。
- 第三部分是两个Inception层,后接最大池化层。
- 第四部分是五个Inception层,后接最大池化层。
- 第五部分是两个Inception层,后接平均池化层。
- 第六部分是是输出层,包括1000个神经元的全连接,用于预测图像属于哪一类。

辅助分类器:
GoogLeNet中共增加了两个辅助的softmax分支:
- 让低层的卷积层学习到的特征也有很好的区分能力
- AC在训练的时候也跟着学习,把自己学习到的梯度反馈给网络,算上网络最后一层的梯度反馈,GoogLeNet一共有3个“梯度提供商”,在提高网络收敛速度的同时也能有效解决梯度消失的问题
(三)GooLeNet的创新点
- GooLeNet的Inception结构融合了不同尺度的特征信息;
- 使用1x1的卷积核进行降维映射处理, 降低了维度也减少了参数量(NiN是用于代替全连接层);
- 用全局平均池化代替全连接层大大减少了参数量(与NiN一致);
- 添加两个辅助分类器帮助训练,避免梯度消失,用于向前传导梯度,也有一定的正则化效果,防止过拟合。
六、批量规范化——BN
(一)批量规范化的概念
批量规范化:基于批量统计的规范化。每次训练迭代中:
- 首先基于当前小批量对输入进行规范化(减去均值除以标准差)
- 然后应用比例系数和比例偏移

批量规范化的作用:
- 使整个神经网络各层的中间输出值更加稳定;
- 批量规范化被认为可以使优化更加平滑,加快优化速度,使用更高的学习率
(二)批量规范化层
批量规范化和其他层之间的一个关键区别是,由于批量规范化在完整的小批量上运行,因此不能像以前在引入其他层时那样忽略批量大小
-
全连接层
批量规范化层置于全连接层中的仿射变换和激活函数之间:( x x x是全连接层的输入, ϕ \phi ϕ是激活函数,BN是批量规范化的运算符)
h = ϕ ( B N ( W x + b ) ) h=\phi(BN(Wx+b)) h=ϕ(BN(Wx+b)) -
卷积层
批量规范化层也可以置于卷积层之后、非线性激活函数之前:- 全连接层只有一个通道,是对一定批量样本的特征进行批量归一化;
- 卷积层有多个输出通道时,是分别对每个通道上一定批量样本进行批量归一化,每个输出通道的批量规范化都有对应的拉伸和偏移参数。
-
预测过程中的批量规范化
批量规范化在训练模式和预测模式下的行为通常不同:- 训练:以batch为单位,对每个batch计算均值和方差。
- 预测:用移动平均估算整个训练数据集的样本均值和方差。
- 将训练好的模型用于预测时不需要样本均值中的噪声以及在微批次上估计每个小批次产生的样本方差。
七、残差网络(ResNet)
(一)引入背景
- 退化问题:实践中加深网络结构并不总是能够提高性能,甚至会导致性能下降;
- 梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0;
- 梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大;
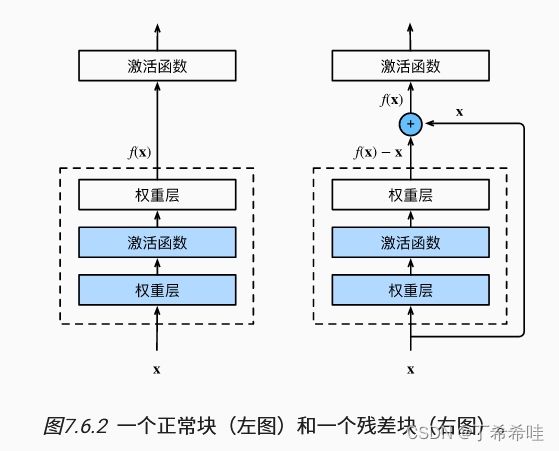
(二)残差块
残差块中 x i n p u t x_{input} xinput 直接跳过多层加入到最后的输出 F ( x ) o u t p u t 2 F(x)_{output2} F(x)output2单元当中,解决 F ( x ) o u t p u t 1 F(x)_{output1} F(x)output1可能带来的模型退化问题
- 传统网络: F ( x ) o u t p u t 1 = x i n p u t F(x)_{output1} = x_{input} F(x)output1=xinput
- 残差网络: F ( x ) o u t p u t 2 = F ( x ) o u t p u t 1 + x i n p u t F(x)_{output2} = F(x)_{output1} + x_{input} F(x)output2=F(x)output1+xinput
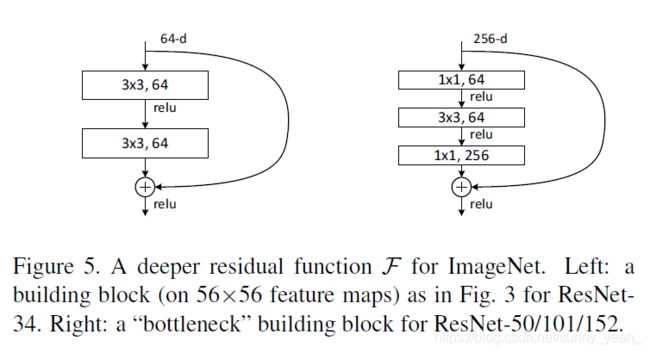
两种ResNet block结构的参数数量相同,右侧的residual blocl结构通过 1X1卷积既能够改变通道数,又能大幅减少计算量和参数量:
- 浅层网络: 采用的是左侧的 residual block 结构(18-layer、34-layer)
- 深层网络: 采用的是右侧的 residual block 结构(50-layer、101-layer、152-layer)
(三)ResNet网络架构
ResNet的整体架构与VGG、GoogLeNet较为类似,只是主体部分替换为残差块。通过堆叠不同数量和形式的残差块,可以得到不同层级的Resnet:
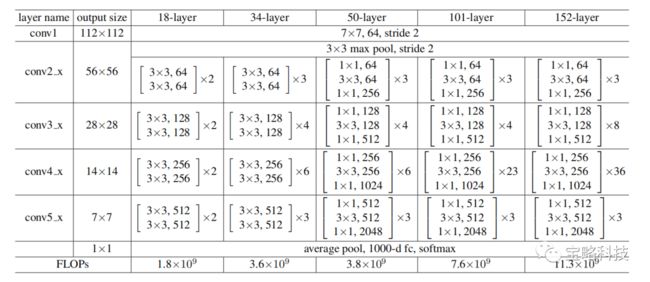
ResNet网络先进入7×7的卷积层以及3×3的池化层,接着是若干个残差块,最后通过全局平均池化层以及softmax输出类别。

(四)ResNet网络的特点
- 超深的网络结构(超过1000层);
- 提出residual(残差结构)模块;
- 使用Batch Normalization 加速训练(丢弃dropout)。
八、稠密连接网络(DenseNet)
(一)从ResNet到DenseNet
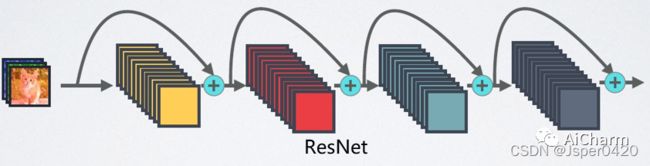
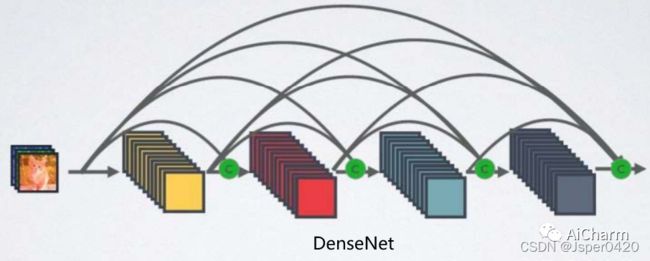
- ResNet和DenseNet的关键区别:DenseNet输出是连接,而不是如ResNet的简单相加。
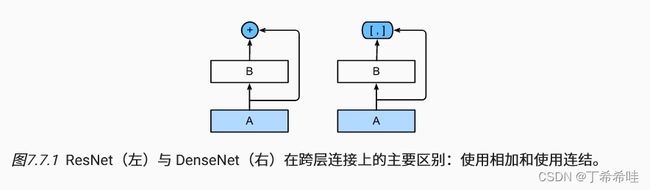
- DenseNet将前面所有层与后面的层建立密集连接来对特征进行重用,从而使得网络深度较大的同时梯度又不会消失。DenseNet网络的稠密连接:
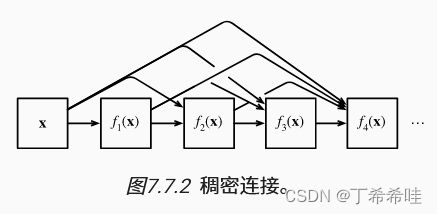
- ResNet:建立前面层与后面层之间的“短路连接”,这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。
- DenseNet:采用密集连接机制,每个层都会与前面所有层在channel维度上连接在一起,实现特征重用,作为下一层的输入。这样,不但减缓了梯度消失的现象,也使其可以在参数与计算量更少的情况下实现比ResNet更优的性能。
(二)DenseNet模型
DenseNet的密集连接方式需要特征图大小保持一致,所以DenseNet 网络使用DenseBlock+Transition的结构:
- DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式;
- Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。

(三)稠密块体:定义如何连接输入和输出
DenseBlock中的非线性组合函数采用的是BN+ReLU+3x3Conv的结构。
(四)过渡层Transition Laye:控制通道数量
- 密集块之间使用过渡层来控制特征图的大小,从而减少计算成本;
- 过渡层由一个卷积层和一个池化层组成:卷积层用于减小通道数,从而降低特征图的维度;池化层用于减小特征图的尺寸。这些操作有助于在保持网络性能的同时降低计算需求。
参考:
这可能是神经网络 LeNet-5 最详细的解释了!
手撕 CNN 经典网络之 AlexNet(理论篇)
图像分类篇[1]:AlexNet网络详解及复现
深度学习理论篇之 ( 十五) – VGG之初探深度之谜
NiN:使用1×1卷积层替代全连接层
【深度学习】NIN (Network in Network) 网络
GoogLeNet详解
[ 图像分类 ] 经典网络模型4——ResNet 详解与复现
深度学习之重读经典(五)ResNet
ResNet详解
深度学习经典网络解析:4.DenseNet