davinci指标排序的bug以及数据库关键字,别名加引号的说明
在指标排序的时候,会报错,维度排序可以,因为指标字段选入之后,davinci会自动加上sum,avg,count,max等然后程序用正则匹配
public static final String REGEX_SQL_AGGREGATE = "sum\\(.*\\)|avg\\(.*\\)|count\\(.*\\)|COUNTDISTINCT\\(.*\\)|max\\(.*\\)|min\\(.*\\)";
!matcher.find()一次执行有误,第二次执行才正确,所以前面加一个matcher.find()即可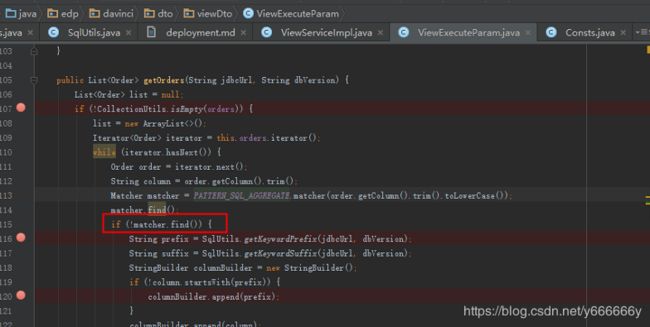
如果只执行一次order 字段有sum等的就不会加引号,就如下,会报错
SELECT "所属库" , sum("指标量") AS "sum(指标量)" FROM (SELECT "所属部分","所属库", COUNT( "指标代码" ) as "指标量" FROM (SELECT arrayElement(splitByChar('|',event_property_value),1) as "指标代码", arrayElement(splitByChar('|',event_property_value),2) as "指标名", arrayElement(splitByChar('|',event_property_value),3) as "所属库", arrayElement(splitByChar('|',event_property_value),4) as "所属部分" FROM default.daily_new_clientrpt_slave WHERE event_property_code != '' AND event_property_code='101101000800016005' AND "所属库" !='' AND day = today() ORDER BY day DESC) T GROUP BY "所属库","所属部分" ORDER BY "指标量" DESC) T GROUP BY "所属库" ORDER BY "所属库" asc, sum(指标量) asc
数据库关键字,别名加引号的说明:
```yml
postgresql:
name: postgresql
desc: postgresql
driver: org.postgresql.Driver
keyword_prefix:
keyword_suffix:
alias_prefix: \"
alias_suffix: \"
```
***注意***
- `keyword_prefix`和`keyword_suffix`表示关键字前缀和后缀,假设使用 mysql 数据库,并将`desc`关键字作为字段使用,那么你的查询语句应该是:
```select `desc` from table```
这里的 ‘`’ 就是前后缀,它们必须成对被配置,可以都为空。
- `alias_prefix`和`alias_suffix`表示别名前后缀,仍以 mysql 为例,假设你的 sql 语句如下:
```select column as '列' from table```
这里为 ‘column’ 起了别名为‘列’,那么‘'’将作为前后缀配置,前后缀必须成对被配置,可以都为空。
- 对于以上别名配置,你可以使用`''`将字符包起来,也可以使用转移符`\`,二者只能出现一种。
- 手动将相应的驱动 jar 包拷贝到`lib`目录下。
- 重启 Davinci 服务。