AI+游戏:高效利用样本的强化学习 | 腾讯AI Lab学术论坛演讲
感谢阅读腾讯AI Lab微信号第26篇文章。腾讯AI Lab第二届学术论坛近期已结束,我们将在之后的文章陆续带来会上顶级嘉宾的演讲内容和相关的延伸阅读。本文是美国伊利诺伊大学厄巴纳-香槟分校计算机科学系助理教授彭健带来的主题演讲。
3月15日,腾讯AI Lab第二届学术论坛在深圳举行,聚焦人工智能在医疗、游戏、多媒体内容、人机交互等四大领域的跨界研究与应用。全球30位顶级AI专家出席,对多项前沿研究成果进行了深入探讨与交流。腾讯AI Lab还宣布了2018三大核心战略,以及同顶级研究与出版机构自然科研的战略合作(点击 这里 查看详情)。
腾讯AI Lab希望将论坛打造为一个具有国际影响力的顶级学术平台,推动前沿、原创、开放的研究与应用探讨与交流,让企业、行业和学界「共享AI+未来」。
彭健
美国伊利诺伊大学厄巴纳-香槟分校计算机科学系助理教授

在下午的“AI+游戏”论坛上,美国伊利诺伊大学厄巴纳-香槟分校计算机科学系助理教授彭健博士做了主题为《实现能高效利用样本的强化学习》的演讲。
彭健博士的研究方向是计算生物学和机器学习的相关领域(如基因组、系统生物学和分子生物学方面的大数据分析处理)。在计算生物学方面,他一直致力于开发高效的算法,对庞大的基因数据集以及系统生物学和分子生物学中的数据集进行分析处理整合。在机器学习方面,他的主要研究兴趣为采样、变分推理方法以及高维图模型的结构化学习算法。他曾获得CROI青年学者奖、斯隆研究奖、美国国家自然科学基金会职业生涯奖、PhRMA基金奖等多个国际著名奖项。他是ISMB、 RECOMB、 AISTATS、ACM-BCB、 AAAI 和 GLBIO等机器学习和生物信息学会议的程序委员会会员,以及PNAS、PLOS Computational Biology、 IEEE/ACM TCB等国际顶级期刊的审稿人。彭健博士为美国芝加哥大学丰田技术学院计算机科学博士,曾于美国麻省理工学院Berger Lab进行博士后研究。
演讲内容
深度强化学习的近期进展(包括深度 Q 学习和基于神经网络的策略优化)已经证明在传统人工智能方法无法解决的很多问题上是有效的。达到人类水平的游戏智能体、AlphaGo 和机器人操作都是其中引入注目的案例。但是,这些任务策略学习需要大量的计算资源,这使得深度强化学习算法难以实际应用于计算机游戏等更复杂的任务。
本演讲将讨论一些令现有算法难以应用的挑战(尤其是奖励传播延迟、方差估计高和探索不充分),同时介绍一些解决方案,展示它们在 Atari 游戏和机车机器人任务上的应用。
以下为演讲全文(为便于阅读进行过适当编辑整理):

大家下午好,我叫彭健,来自美国伊利诺伊大学厄巴纳-香槟分校计算机系,今天我讲一讲我们研究组对深度强化学习的一些改进。
目前的游戏 AI(特别是一些基于深度学习的 AI)的表现相比传统的基于规则的算法实现了很大的提升。而且在各种各样的游戏上都有这种现象,比如控制类游戏、物理模拟类游戏(比如《愤怒的小鸟》)、基于第一视角的探索性游戏(比如《Minecraft》)、以及更难的有大面积搜索空间的游戏(比如《王者荣耀》、《DotA》、《星际争霸》)。另外,AlphaGo 是目前最有影响力的工作。其实所有这些游戏 AI 背后的算法都有深度强化学习。
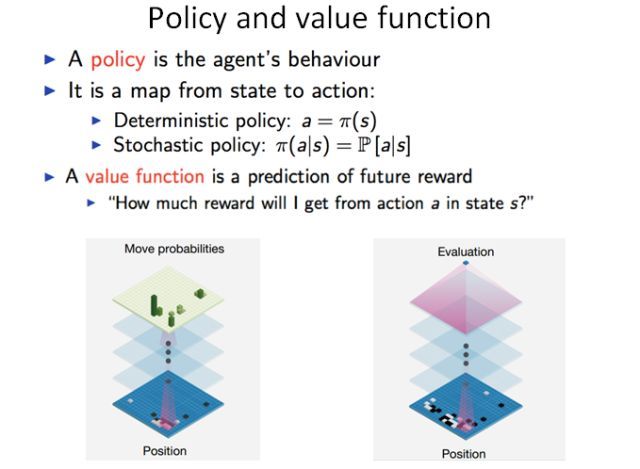
在深度强化学习中目前有两种比较有效的算法。第一种算法是策略优化,也就是说我们通过一个函数定义智能体的一个行为,比如根据当前的游戏画面或围棋盘面定义接下来的操作。这个过程中有两种可能:一种是确定性的策略,也就是说知道下面需要走哪一步;还有一种是随机的,也就是说可能存在各种不同的选择,我可以根据概率来选择其中一个操作。策略优化方法是现在目前比较流行的方法,因为这是一种比较简单和直接的优化办法。目前主要的方法是通过策略梯度来进行优化,也就是通过优化策略来最大化未来得到的奖励(reward)。
第二种方法叫做 Q 学习,这是一种通过学习价值函数或价值网络的方法。这个价值函数能给出对未来奖励的预测。在 AlphaGo 中,这两种算法是交叉在一起的。策略网络学习下一步要走哪个子,价值函数对当前落子进行价值估计。
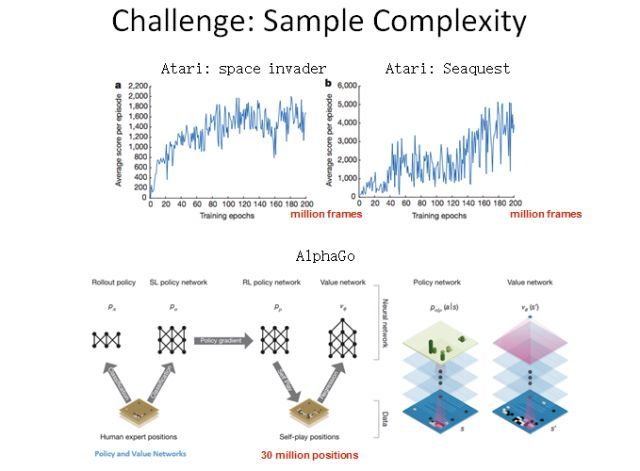
在目前的深度强化学习中,最大的一个难题是采样复杂度太高了,也就是说我们需要大量数据来训练我们的智能体。不论是策略优化方法还是 Q 学习的方法,都需要大量数据。比如这里展示的几个例子,在《Space Invader》和《Seaquest》这两个 Atari 游戏中,智能体所获得的分数会随训练数据增加而增加。可以看到,利用经典的深度强化学习算法可能需要 2 亿帧画面才能学到比较好的效果。AlphaGo 最早在 Nature 公布的版本也需要 3000 万个盘面。
这样高的采样复杂度,就导致我们没法在各种复杂游戏中使用深度强化学习。有两个可能的原因。第一个原因是游戏中的奖励信号通常是稀疏的或会延迟到来,也就是说我们在相当长的时间内都不会得到游戏的反馈。另一个原因可能是没有足够的探索,也就是说我们当前学习的策略可能会被困在局部最优。
下面我讲一下针对这两个问题我提出来的可能解决方案。
第一,考虑到奖励的稀疏性和延迟性问题,我们就想有没有办法可以使奖励传递得更快?

现在我们考虑一个很简单的游戏——第一视角的迷宫探索类游戏。在这个游戏中,我们只能观察到前方视野中的数据。我们的任务是从迷宫的某处出发,到达某个点。这种情况下,我们就只有一个非零奖励,也就是迷宫的出口。在探索过程中,我们不能得到任何反馈。在围棋中也是一样,我们一直要到最后一步才能知道我们是输还是赢。
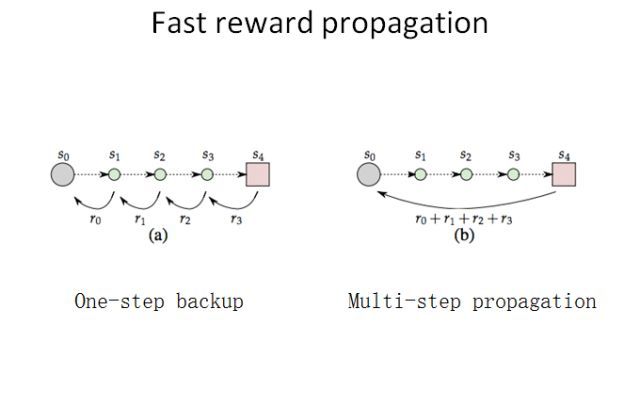
在这样的情况下,我们自然会想能不能让奖励信号传播得更快一点。经典的 Q 学习算法是每次传播一步,也就是采取了一个动作就立即会有一个奖励反馈。我们很自然就会想:也许能把很多步的奖励积累起来,跨越多个时间点一次性传播回当前时间点。
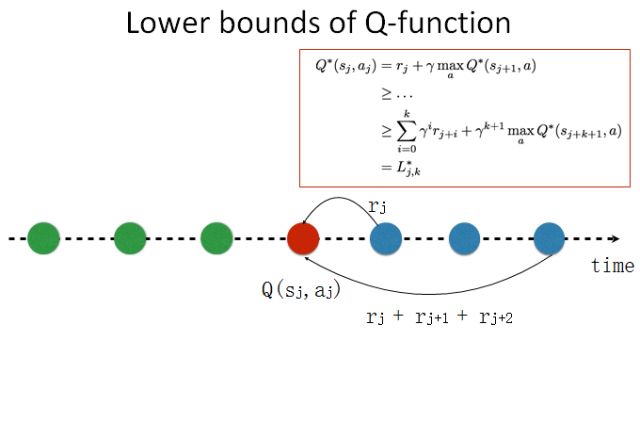
下面我给大家介绍一下我的一个简单想法。假设在 Q 学习中有一个时间线,在一局游戏中不同的时间点上有不同的动作,对应不同的奖励。每个时间点都有一个价值函数 Q(sj,aj),表示在当前状态 s 时采取动作 a 的价值。经典的 Q 学习算法就是这样的,我们向下走一步,然后看能不能通过这一步的操作来更新 Q。
如果我们想实现更快的奖励传播,我们就需要向前多看若干步。这是一个很自然的想法。如果我们知道整个时间线,在当前状态,我可能对未来有一个规划和估计;如果我知道我的未来,我就可以知道当前可能会有更好的选择,我就可以得到一个对未来比较乐观的估计。我知道如果我选择一个其它动作,我能在当前时间线上得到更好的价值。这是一种展望未来式(looking forward)的算法。利用贝尔曼方程(Bellman Equation),我们可以得到当前估计的下限。
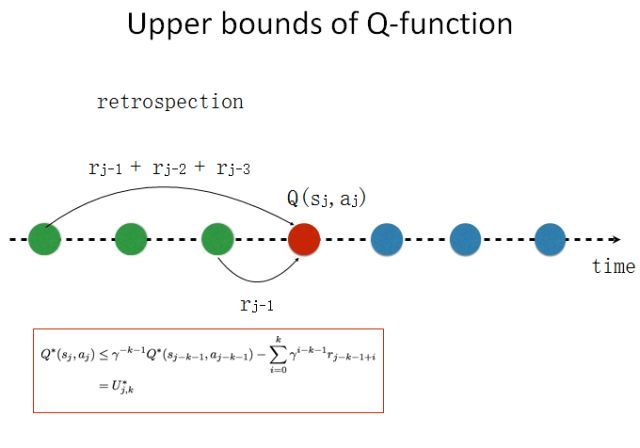
我们也可以向回看,进行一下反省。如果我们知道这样一个时间线,我们可以回到过去,我可以知道在过去的时候我可能有更好的选择。我们同样可以用贝尔曼方程展开,得到当前估计的上限。这个算法比较简单。

如图所示,上面是经典深度 Q 学习的算法,这是每一步的算法。现在我只需要对这个算法修改一点点,加两个约束——一个是基于未来的下限,一个基于过去的上限。这样我们就能大大减小价值函数的搜索空间,从而能实现更好的采样效率。
我们做了一些简单的实验。在 DeepMind 用来评价自己的算法的 64 个 Atari 游戏基准上,我们评估我们的方法的采样效率。在一个 GPU 上,经典的 DQN 算法需要 10 天以上时间才能达到与人类相当的游戏水平,而我们的算法只需要一天,而且得到的结果还更好。这个方向可能还有其它做法,这只是我们的一个尝试。
第二个问题是没有足够的探索,也就是说游戏智能体可能会困在局部最优。

比如,这是我们之前尝试的一个游戏。智能体需要探索一个迷宫,然后救出人质或达到一些其它目的。这个游戏的场景很简单,所以很容易训练。但很快在这个状态就会卡住,就无法得到一个很好的策略。
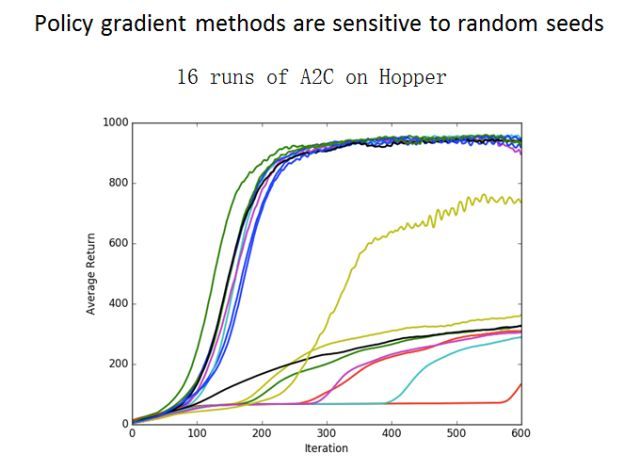
其它一些强化学习算法也会陷入类似的问题。比如在机器人学的研究中,人们利用了 A2C和 PPO 等一些其它算法。可以看到,如果用同样的算法训练同样的游戏若干次,不同的次数可能就会得到非常不同的训练结果。这是因为策略优化和 DQN 算法很容易陷入局部最优,而且我们不知道它们什么时候能跳出来。

所以我们就想,如果只训练一个模型容易陷入局部最优,那么我们就训练多个模型。这个算法与自然界采用的一些方法很像,比如蚁群算法和其它一些组合优化算法。我们可以同时采取多个不同的模型,同时进行训练。我们的目标是同时优化这些模型的表现,同时让这些模型看起来不太一样。基于这一思考,我们首先提出一种名叫非参数变分推理(SVPG)的算法,这个工作发表在 UAI 2017 会议上。

另一个比较直观的想法是用遗传算法。我们通过经典的遗传算法,同时维护若干个模型,然后让这些模型分别自己进化并进行杂交。之后我们选取其中更好的后代进行优化。针对深度强化学习,我们设计了一个新的基于神经网络的 crossover 优化器。也就是说,当我们有一个父亲模型和一个母亲模型的时候,我们可以怎样得到一个比较好的后代模型?
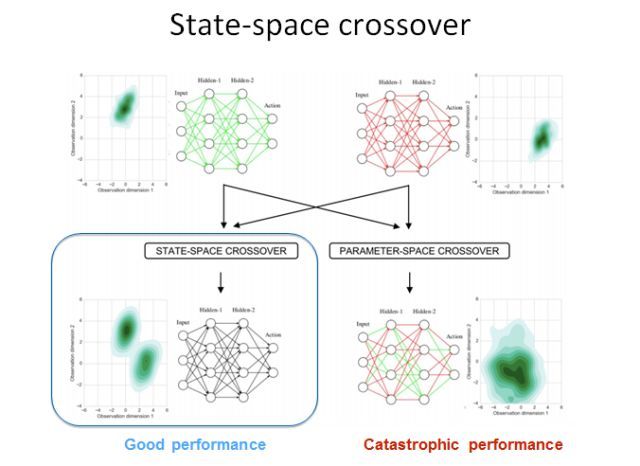
我们用了一个不同于传统的方法。我们用模仿学习(imitation learning)方法训练一个后代,让它去模拟父亲和母亲的策略行为。然后我们在一些机器人环境中探索了这些算法的优异性。我们的算法在大多数机器人任务上都能超越之前的最佳方法。
我刚才介绍了针对探索和奖励延迟问题的一些解决方法。而深度强化学习还有很多其它问题。如果我们想利用深度强化学习设计比较复杂的游戏 AI,可能就会遇到很多难题。比如,第一个问题可能是策略梯度估计时方差比较大——我们做了一些优化这个方差的工作。第二个问题是动作空间比较大,我们需要一些抽象(abstraction)方法来缩小动作空间。第三个问题是现在的算法的数据有效性还是不够,我们需要一些更好的优化算法。
谢谢!
