17. Android MultiMedia框架完全解析 - MediaClock分析与音视频同步
这里的代码分析流程就是《15. Android MultiMedia框架完全解析 - Render流程分析》中的代码流程,上次主要关注的是buffer的交互流程,这次主要分析的是音视频同步,即AVsync。
(一)音视频同步概念与方法
音视频同步是一个播放器要处理的基本问题,音视频同步的好坏直接影响到播放效果。
解码后的音频片段和视频片段,都分别带有 pts 时间戳信息。回放时需要做的,就是尽量保证 apts(音频时间戳)和 vpts(视频时间戳),之间的差值是最小的。为了达到这个目的,就需要在 audio device 和 video device进行渲染的时候进行控制。控制的方法就是 delay。
由于音频的采样率是固定的,在回放时我们必须保证连续性,就是说两个时间上连续的音频片段是不允许有 delay 的,(一般声卡每次播一个采样点而不是一帧。声音当一个采样点丢失了都可以听出来,视频则不然)如果有了 delay 人的耳朵可以很明显的分辨出来,给人的主观感受就是声音卡顿。
反则视频则不如此,虽然表面上说的是30p,不一定每一帧的间隔就必须精确到33.33ms,因为人肉眼是观察不出来的。
做音视频同步的话,有三种方法:
1)音频同步到视频;
2)视频同步到音频 ;
3)音视频都同步到外部时钟。
另外一个问题,音频和视频是各自线程独立播放的,所以需要同步行为来保证声画的时间节点是一致的或者时间偏差值在一定的范围内。
从技术上来说,解决音视频同步问题的最佳方案就是时间戳:
首先选择一个参考时钟(要求参考时钟上的时间是线性递增的);
生成数据流时依据参考时钟上的时间给每个数据块都打上时间戳(一般包括开始时间和结束时间);
在播放时,读取数据块上的时间戳,同时参考当前参考时钟上的时间来安排播放(如果数据块的开始时间大于当前参考时钟上的时间,则不急于播放该数据块,直到参考时钟达到数据块的开始时间;如果数据块的开始时间小于当前参考时钟上的时间,则“尽快”播放这块数据或者索性将这块数据“丢弃”,以使播放进度追上参考时钟)。

可见,避免音视频不同步现象有两个关键——
一是在生成数据流时要打上正确的时间戳。如果数据块上打的时间戳本身就有问题,那么播放时再怎么调整也于事无补。
如图,视频流内容是从0s开始的,假设10s时有人开始说话,要求配上音频流,那么音频流的起始时间应该是10s,如果时间戳从0s或其它时间开始打,则这个混合的音视频流在时间同步上本身就出了问题。
打时间戳时,视频流和音频流都是参考参考时钟的时间,而数据流之间不会发生参考关系;也就是说,视频流和音频流是通过一个中立的第三方(也就是参考时钟)来实现同步的。
第二个关键的地方,就是在播放时基于时间戳对数据流的控制,也就是对数据块早到或晚到采取不同的处理方法。
图中,参考时钟时间在0-10s内播放视频流内容过程中,即使收到了音频流数据块也不能立即播放它,而必须等到参考时钟的时间达到10s之后才可以,否则就会引起音视频不同步问题。
为了更好地理解基于时间戳的音视频同步方案,下面举一个生活中的例子。假设你和你的一个朋友约好了今天18:00在沪上广场见面,然后一起吃饭,再去打游戏。实际上,这个18:00就是你和你朋友保持同步的一个时间点。结果你17:50就到了沪上广场,那么你必须等你的朋友。10分钟过后,你的朋友还没有到,这时他打来电话说有事耽搁了,要晚一点才能到。你没办法,因为你已经在旁边的餐厅预订了位置,如果不马上赶过去,预订就会被取消,于是你告诉你的朋友直接到餐厅碰头吧,要他加快点。于是在餐厅将来的某个时间点就成为你和你朋友的又一个同步点。虽然具体时间不定(要看你朋友赶过来的速度),但这样努力的方向是对的,你和你朋友肯定能在餐厅见到面。结果呢?你朋友终于在18:30赶过来了,你们最终“同步”了。吃完饭19:30了,你临时有事要处理一下,于是跟你朋友再约好了20:00在附近的一家游戏厅碰头。你们又不同步了,但在游戏厅将来的某个时间点你们还是会再次同步的。
悟出什么道理了没有?其实,同步是一个动态的过程,是一个有人等待、有人追赶的过程。同步只是暂时的,而不同步才是常态。人们总是在同步的水平线上振荡波动,但不会偏离这条基线太远。
(二)打时间戳的方法
既然上面讲了,最好的方法是打时间戳,那么音视频都是怎么打时间戳的?
2.1 视频时间戳
一般这个值依赖于帧率,1000/fps为帧间间隔,相当于一个个间隔时间加上去了。
pts = inc++ * (1000/fps); //其中inc是一个静态的,初始值为0,每次打完时间戳加1。
2.2 音频时间戳
依赖于音频的sample rate来计算,(1000 / sample_rate)是每个采样多长时间,(frame_size * 1000 / sample_rate)计算出来一个frame_size长度的音频帧的时长:
pts = inc++ * (frame_size * 1000 / sample_rate);
这只是举一个例子,但是从上面打时间戳的方法上就可以看出来,根据音频帧中的时间戳是可以计算出来播放时长,而视频帧的时间戳是计算不出来时长的,就算要同步到外部时钟上,也是需要根据音频帧与外部时钟同步后,视频帧再同步到音频帧上。
具体在NuPlayer中是如何做的,大致思路是:根据音频帧播放的数目,参考外部时钟每隔一段时间打一个锚点,然后将视频帧根据这个锚点来进行同步。
(三)NuPlayer中音视频同步方法详解
在之前的文章中分析过,音视频的同步是在NuPlayer::Renderer中做的,具体的流程在《15. Android MultiMedia框架完全解析 - Render流程分析》中已经分析,这里列出主要有关音视频同步的代码分析,先来看函数流程图:
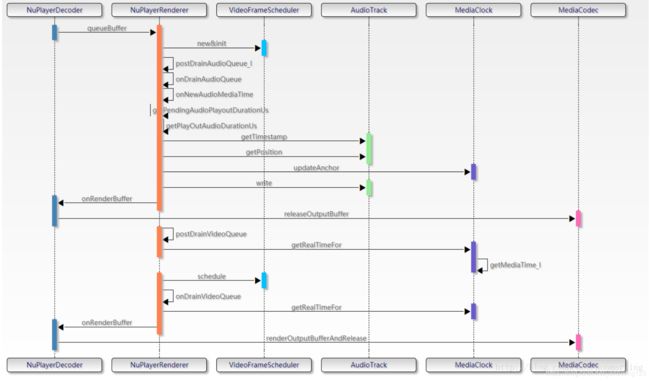
NuPlayerDecoder拿到解码后的音视频数据后queueBuffer给NuPlayerRenderer,在NuPlayerRenderer中通过postDrainAudioQueue_l方法调用AudioTrack进行写入,并且获取“Audio当前播放的时间”,可以看到这里也调用了AudioTrack的getTimeStamp和getPosition方法,同时会利用MediaClock类记录一些锚点时间戳变量。NuPlayerRenderer中调用postDrainVideoQueue方法对video数据进行处理,包括计算实际送显时间,利用vsync信号调整送显时间等,这里的调整是利用VideoFrameScheduler类完成的。需要注意的是,实际上NuPlayerRenderer方法中只进行了avsync的调整,真正的播放还要通过onRendereBuffer调用到NuPlayerDecoder中,进而调用MediaCodec的release方法进行播放。
因为音视频同步的方法是根据音频帧播放的数目,参考外部时钟每隔一段时间打一个锚点,然后将视频帧根据这个锚点来进行同步,所以先来分析音频部分:
3.1 Audio部分
1)从 NuPlayer::Decoder::handleAnOutputBuffer()函数开始, 在它里面调用mRenderer->queueBuffer(mIsAudio, buffer, reply); 从而把Buffer交给Renderer处理,同时注意这个reply,它是NuPlayer::Decoder交给NuPlayer::Renderer的回调消息,当Renderer中完成对Buffer的Render操作后,会通过这个reply反馈给NuPlayer::Decoder。
最终会执行到NuPlayer::Renderer::onQueueBuffer()函数中:
void NuPlayer::Renderer::onQueueBuffer(const sp &msg) {
......
if (audio) {
Mutex::Autolock autoLock(mLock);
mAudioQueue.push_back(entry);
postDrainAudioQueue_l();
} else {
mVideoQueue.push_back(entry);
postDrainVideoQueue();
}
......
int64_t firstAudioTimeUs;
int64_t firstVideoTimeUs;
CHECK(firstAudioBuffer->meta()
->findInt64("timeUs", &firstAudioTimeUs));
CHECK(firstVideoBuffer->meta()
->findInt64("timeUs", &firstVideoTimeUs));
//这里分别获取音视频帧的PTS
int64_t diff = firstVideoTimeUs - firstAudioTimeUs;
ALOGV("queueDiff = %.2f secs", diff / 1E6);
if (diff > 100000ll) {
// Audio data starts More than 0.1 secs before video.
// Drop some audio.
//这里对音视频帧的第一个pts做一下纠正,保证一开始两者就是同步的。
(*mAudioQueue.begin()).mNotifyConsumed->post();
mAudioQueue.erase(mAudioQueue.begin());
return;
}
syncQueuesDone_l();
}
然后就会发送kWhatDrainAudioQueue命令,跳转到处理函数中:
case kWhatDrainAudioQueue:
{
......
if (onDrainAudioQueue()) {
//onDrainAudioQueue方法中,如果最后发现audioQueue中还有数据,则会返回true,表示需要
继续写入数据,详细的分析见下面2)中的分析
uint32_t numFramesPlayed;
CHECK_EQ(mAudioSink->getPosition(&numFramesPlayed),
(status_t)OK);//通过这个方法获取已经播放的frame position。
uint32_t numFramesPendingPlayout =
mNumFramesWritten - numFramesPlayed;
//写入的帧数 mNumFramesWritten 减去已经播放的帧数 numFramesPlayed 就是还没有播放的帧数
// This is how long the audio sink will have data to
// play back.
int64_t delayUs =
mAudioSink->msecsPerFrame()
* numFramesPendingPlayout * 1000ll;
//这里就是将还没有播放的帧数转换成时间,设为delayUs
if (mPlaybackRate > 1.0f) {
delayUs /= mPlaybackRate;
}
//这里是对倍率播放的设置
// Let's give it more data after about half that time
// has elapsed.
delayUs /= 2;
//这里调用onDrainAudioQueue的间隔设置为delayUs/2
// check the buffer size to estimate maximum delay permitted.
const int64_t maxDrainDelayUs = std::max(
mAudioSink->getBufferDurationInUs(), (int64_t)500000 /* half second */);
ALOGD_IF(delayUs > maxDrainDelayUs, "postDrainAudioQueue long delay: %lld > %lld",
(long long)delayUs, (long long)maxDrainDelayUs);
Mutex::Autolock autoLock(mLock);
postDrainAudioQueue_l(delayUs);
}
break;
}注意这里,又跳转到 postDrainAudioQueue_l(delayUs);里面了,从而会一直调用kWhatDrainAudioQueue这个循环,但是需要注意的是:这里同时加了一个延时,这就是一个很关键的点,说明播放器在音频的处理循环中是有一定间隔的,并非不停的运转Loop。
至于怎么设置延时时间的,可以看上面的注释,已经都写清楚了,核心就是音频的采样率是固定的,它的帧数与播放时间有一个直接的关系,可以直接进行转换。
2)这里看看onDrainAudioQueue()函数中:
bool NuPlayer::Renderer::onDrainAudioQueue() {
uint32_t numFramesPlayed;
uint32_t prevFramesWritten = mNumFramesWritten;
while (!mAudioQueue.empty()) {//循环处理Audio Queue中的数据
QueueEntry *entry = &*mAudioQueue.begin();
mLastAudioBufferDrained = entry->mBufferOrdinal;
if (entry->mBuffer == NULL) {
// EOS
......
}
// ignore 0-sized buffer which could be EOS marker with no data
//第一次Drain Audio Queue就会执行到这一个分支
if (entry->mOffset == 0 && entry->mBuffer->size() > 0) {
int64_t mediaTimeUs; //读取音频帧的pts
CHECK(entry->mBuffer->meta()->findInt64("timeUs", &mediaTimeUs));
ALOGV("onDrainAudioQueue: rendering audio at media time %.2f secs",
mediaTimeUs / 1E6);
onNewAudioMediaTime(mediaTimeUs);
//利用获取的这个pts来初始化几个锚点,下面会重点分析这个
}
size_t copy = entry->mBuffer->size() - entry->mOffset;//表示buffer中还剩多少数据
ssize_t written = mAudioSink->write(entry->mBuffer->data() + entry->mOffset,
copy, false /* blocking */);
//继续通过AudioSink向buffer中写数据,我们期望写入copy大小,written返回实际写入的数量
if (written < 0) {
......
}
entry->mOffset += written; //更新offset
size_t remainder = entry->mBuffer->size() - entry->mOffset;
if ((ssize_t)remainder < mAudioSink->frameSize()) {
if (remainder > 0) {
ALOGW("Corrupted audio buffer has fractional frames, discarding %zu bytes.",
remainder);
entry->mOffset += remainder;
copy -= remainder;
}
//当前buffer已经全部写入了,送给decoder的onRenderBuffer方法
entry->mNotifyConsumed->post();
mAudioQueue.erase(mAudioQueue.begin());
entry = NULL;
}
size_t copiedFrames = written / mAudioSink->frameSize();
mNumFramesWritten += copiedFrames;//更新mNumFramesWritten
{
Mutex::Autolock autoLock(mLock);
int64_t maxTimeMedia;
maxTimeMedia =
mAnchorTimeMediaUs +
(int64_t)(max((long long)mNumFramesWritten - mAnchorNumFramesWritten, 0LL)
* 1000LL * mAudioSink->msecsPerFrame());
//锚点媒体时间戳加上新写入帧数对应的时长,即为媒体时间戳最大值
mMediaClock->updateMaxTimeMedia(maxTimeMedia);
//更新MediaClock中的maxTimeMedia
notifyIfMediaRenderingStarted_l();
}
if (written != (ssize_t)copy) {
......
}
}
// calculate whether we need to reschedule another write.
//还有数据的话,继续循环准备下一次写入
bool reschedule = !mAudioQueue.empty()
......
return reschedule;
}
当第一次Drain Audio Queue时,会根据获得的初始pts值通过onNewAudioMediaTime()函数中去初始化几个锚点值,看看它是怎么做的:(mediaTimeUs参数即为获取到的初始pts)
void NuPlayer::Renderer::onNewAudioMediaTime(int64_t mediaTimeUs) {
Mutex::Autolock autoLock(mLock);
if (mediaTimeUs == mAnchorTimeMediaUs) {
return;
}
setAudioFirstAnchorTimeIfNeeded_l(mediaTimeUs);
int64_t nowUs = ALooper::GetNowUs();
if (mNextAudioClockUpdateTimeUs >= 0) {
if (nowUs >= mNextAudioClockUpdateTimeUs) {
int64_t nowMediaUs = mediaTimeUs - getPendingAudioPlayoutDurationUs(nowUs);
//pts减去还没播放的时间,其实就是当前已经播放的时间,即playedDuration,将其设置为nowMediaUs,至于怎么计算的,在后面详细分析
mMediaClock->updateAnchor(nowMediaUs, nowUs, mediaTimeUs);
//利用当前的系统时间,当前播放的媒体时间,pts来更新锚点
}
} else {
......
}
mAnchorNumFramesWritten = mNumFramesWritten;//“锚点写入帧数量”初始化为0
mAnchorTimeMediaUs = mediaTimeUs;//将锚点媒体时间戳设置为初始audio pts
}
void NuPlayer::Renderer::setAudioFirstAnchorTimeIfNeeded_l(int64_t mediaUs) {
if (mAudioFirstAnchorTimeMediaUs == -1) {
mAudioFirstAnchorTimeMediaUs = mediaUs;
mMediaClock->setStartingTimeMedia(mediaUs);
}
}
void MediaClock::setStartingTimeMedia(int64_t startingTimeMediaUs) {
Mutex::Autolock autoLock(mLock);
mStartingTimeMediaUs = startingTimeMediaUs;
}这里引入了几个新变量,即锚点时间,
mAnchorTimeMediaUs 为锚点媒体时间戳,可以理解为从最开始播放时记录下来的第一个媒体时间戳,一直到当前正在播放这一帧的总时长,但是它主要将音频pts与系统时钟做了统一,即将音频同步到系统时钟上。
mAnchorTimeRealUs为锚点real系统时间戳,可以理解为最后一帧播放的时间,对应到系统时钟后的时间。
nowMediaUs 为已经播放的时间,
mAnchorNumFramesWritten 为锚点写入帧数量
int64_t nowMediaUs = mediaTimeUs - getPendingAudioPlayoutDurationUs(nowUs);
//pts减去还没播放的时间,其实就是当前已经播放的时间,即playedDuration,将其设置为nowMediaUs,至于怎么计算的,在后面详细分析这里来看这段代码什么意思?看下面这个图:

想要计算播放时长,我们已经知道了下一帧的pts,只要减去还没有播放的,就是已经播放的。。。。这个逻辑看似很奇怪,但是它的核心思想在于音频是固定采样率的,同时,有两个参数也是知道的:一个是写入audioTrack的帧数mNumFrameWritten,另一个是已经播放的帧数playedFramed,下面就来看看这个函数:
int64_t NuPlayer::Renderer::getPendingAudioPlayoutDurationUs(int64_t nowUs) {
//计算writtenFrames对应的duration
int64_t writtenAudioDurationUs = getDurationUsIfPlayedAtSampleRate(mNumFramesWritten);
if (mUseVirtualAudioSink) {
int64_t nowUs = ALooper::GetNowUs();
int64_t mediaUs;
if (mMediaClock->getMediaTime(nowUs, &mediaUs) != OK) {
return 0ll;
} else {
return writtenAudioDurationUs - (mediaUs - mAudioFirstAnchorTimeMediaUs);
}
}
return writtenAudioDurationUs - mAudioSink->getPlayedOutDurationUs(nowUs);
}
int64_t NuPlayer::Renderer::getDurationUsIfPlayedAtSampleRate(uint32_t numFrames) {
int32_t sampleRate = offloadingAudio() ?
mCurrentOffloadInfo.sample_rate : mCurrentPcmInfo.mSampleRate;
return (int64_t)((int32_t)numFrames * 1000000LL / sampleRate);
}下面又跳转到MediaPlayerService::AudioOutput::getPlayedOutDurationUs()函数中,它选择性的使用两种方法去获取播放的时长:mTrack->getTimestamp(ts)和mTrack->getPosition(&numFramesPlayed):
int64_t MediaPlayerService::AudioOutput::getPlayedOutDurationUs(int64_t nowUs) const
{
uint32_t numFramesPlayed;
int64_t numFramesPlayedAt;
AudioTimestamp ts;
static const int64_t kStaleTimestamp100ms = 100000;
status_t res = mTrack->getTimestamp(ts);//第一种方法
if (res == OK) { // case 1: mixing audio tracks and offloaded tracks.
numFramesPlayed = ts.mPosition;//当前播放的framePosition
numFramesPlayedAt = ts.mTime.tv_sec * 1000000LL + ts.mTime.tv_nsec / 1000;
//framePosition对应的系统时间
const int64_t timestampAge = nowUs - numFramesPlayedAt;
//这个时间与系统时间不应该差的太多,阈值默认为100ms
if (timestampAge > kStaleTimestamp100ms) {
......
}
//ALOGD("getTimestamp: OK %d %lld", numFramesPlayed, (long long)numFramesPlayedAt);
} else if (res == WOULD_BLOCK) {//case 2: transitory state on start of a new track
......
} else {// case 3: transitory at new track or audio fast tracks.
res = mTrack->getPosition(&numFramesPlayed);//第二种方法
CHECK_EQ(res, (status_t)OK);
numFramesPlayedAt = nowUs;
numFramesPlayedAt += 1000LL * mTrack->latency() / 2; /* XXX */
//当前系统时间加上latency才是真正playedOut的时间,这里取了latency/2,可以看做是一种平均,因为latency方法返回值可能并不准
//ALOGD("getPosition: %u %lld", numFramesPlayed, (long long)numFramesPlayedAt);
}
// TODO: remove the (int32_t) casting below as it may overflow at 12.4 hours.
int64_t durationUs = (int64_t)((int32_t)numFramesPlayed * 1000000LL / mSampleRateHz)
+ nowUs - numFramesPlayedAt;
if (durationUs < 0) {
ALOGV("getPlayedOutDurationUs: negative duration %lld set to zero", (long long)durationUs);
durationUs = 0;
}
ALOGV("getPlayedOutDurationUs(%lld) nowUs(%lld) frames(%u) framesAt(%lld)",
(long long)durationUs, (long long)nowUs, numFramesPlayed, (long long)numFramesPlayedAt);
return durationUs;
}来简单说说这几个变量,numFramesPlayed代表“从底层获取到的已播放帧数”,需要注意的是,这个并不一定是当前系统时间下已经播放的实时帧数,而numFramesPlayedAt代表“numFramesPlayed对应的系统时间”,所以
durationUs = numFramesPlayed/sampleRate +nowUs - numFramesPlayedAt才是当前系统时间下已经播放的音频时长。
总结一下,这里什么意思呢?就是说在执行getPendingAudioPlayoutDurationUs()函数时,音频还继续在播放过程中,它会继续走一段时间,如图中红色所示,这时候计算播放时长的话,需要把这段延时加上去。
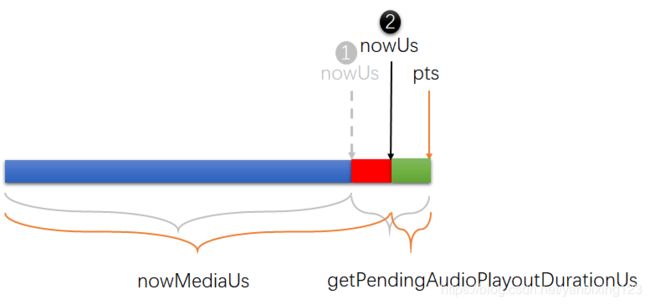
计算完这个时间后,继续调用 mMediaClock->updateAnchor(nowMediaUs, nowUs, mediaTimeUs);来更新锚点时间戳:
void MediaClock::updateAnchor(
int64_t anchorTimeMediaUs,
int64_t anchorTimeRealUs,
int64_t maxTimeMediaUs) {
Mutex::Autolock autoLock(mLock);
int64_t nowUs = ALooper::GetNowUs();
int64_t nowMediaUs =
anchorTimeMediaUs + (nowUs - anchorTimeRealUs) * (double)mPlaybackRate;
mAnchorTimeRealUs = nowUs;
mAnchorTimeMediaUs = nowMediaUs;
}这里可以看到它是如何更新的,更新前:
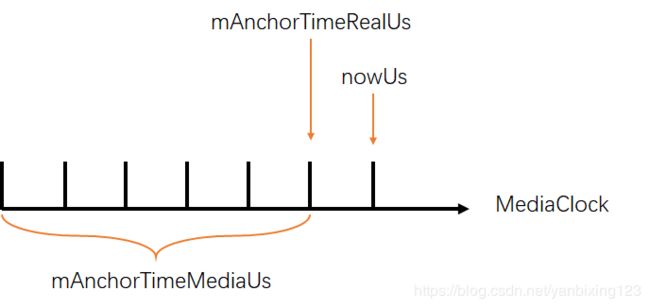
更新后:
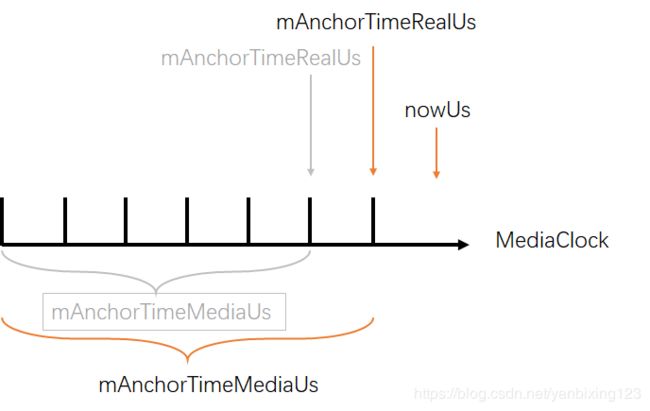
到此为止,就讲完Audio与系统时钟的同步,之后的Video会根据这些锚点来同步。
3.2 Video部分
还是从NuPlayer::Renderer::onQueueBuffer()函数开始分析,它直接就调用到NuPlayer::Renderer::postDrainVideoQueue()函数:
void NuPlayer::Renderer::postDrainVideoQueue() {
......
QueueEntry &entry = *mVideoQueue.begin();
sp msg = new AMessage(kWhatDrainVideoQueue, this);
msg->setInt32("drainGeneration", getDrainGeneration(false /* audio */));
int64_t delayUs;
int64_t nowUs = ALooper::GetNowUs();
int64_t realTimeUs;
if (mFlags & FLAG_REAL_TIME) {
......
} else {
int64_t mediaTimeUs;
CHECK(entry.mBuffer->meta()->findInt64("timeUs", &mediaTimeUs));//获取pts
{
Mutex::Autolock autoLock(mLock);
if (mAnchorTimeMediaUs < 0) {
mMediaClock->updateAnchor(mediaTimeUs, nowUs, mediaTimeUs);
mAnchorTimeMediaUs = mediaTimeUs;
realTimeUs = nowUs;
} else if (!mVideoSampleReceived) {
// Always render the first video frame.
realTimeUs = nowUs;
} else if (mAudioFirstAnchorTimeMediaUs < 0
|| mMediaClock->getRealTimeFor(mediaTimeUs, &realTimeUs) == OK) {
realTimeUs = getRealTimeUs(mediaTimeUs, nowUs);
//根据pts和系统时钟计算realTimeUs,这个realTimeUs的含义应该理解为:视频应该在这个时间点播放
} else if (mediaTimeUs - mAudioFirstAnchorTimeMediaUs >= 0) {
needRepostDrainVideoQueue = true;
realTimeUs = nowUs;
} else {
realTimeUs = nowUs;
}
}
......
delayUs = realTimeUs - nowUs;//还有多久播放这一帧
int64_t postDelayUs = -1;
if (delayUs > 500000) {//这一帧来的太早了,超过了500ms的门限值,则重新loop一次。
postDelayUs = 500000;
if (mHasAudio && (mLastAudioBufferDrained - entry.mBufferOrdinal) <= 0) {
postDelayUs = 10000;
}
} else if (needRepostDrainVideoQueue) {
// CHECK(mPlaybackRate > 0);
// CHECK(mAudioFirstAnchorTimeMediaUs >= 0);
// CHECK(mediaTimeUs - mAudioFirstAnchorTimeMediaUs >= 0);
postDelayUs = mediaTimeUs - mAudioFirstAnchorTimeMediaUs;
postDelayUs /= mPlaybackRate;
}
......
realTimeUs = mVideoScheduler->schedule(realTimeUs * 1000) / 1000;
//利用vsync信号调整realTimeUs
int64_t twoVsyncsUs = 2 * (mVideoScheduler->getVsyncPeriod() / 1000);
//2倍vsync duration
delayUs = realTimeUs - nowUs;
//利用调整后的realTimeUs再计算一次“还有多久播放这一帧”
ALOGW_IF(delayUs > 500000, "unusually high delayUs: %" PRId64, delayUs);
// post 2 display refreshes before rendering is due
msg->post(delayUs > twoVsyncsUs ? delayUs - twoVsyncsUs : 0);
mDrainVideoQueuePending = true;
}
来看看getRealTimeUs()函数(realTimeUs = getRealTimeUs(mediaTimeUs, nowUs);):
int64_t NuPlayer::Renderer::getRealTimeUs(int64_t mediaTimeUs, int64_t nowUs) {
int64_t realUs;
if (mMediaClock->getRealTimeFor(mediaTimeUs, &realUs) != OK) {
return nowUs;
}
return realUs;
}
status_t MediaClock::getRealTimeFor(
int64_t targetMediaUs, int64_t *outRealUs) const {
int64_t nowUs = ALooper::GetNowUs();
int64_t nowMediaUs;
status_t status =
getMediaTime_l(nowUs, &nowMediaUs, true /* allowPastMaxTime */);
*outRealUs = (targetMediaUs - nowMediaUs) / (double)mPlaybackRate + nowUs;
return OK;
}
status_t MediaClock::getMediaTime_l(
int64_t realUs, int64_t *outMediaUs, bool allowPastMaxTime) const {
int64_t mediaUs = mAnchorTimeMediaUs
+ (realUs - mAnchorTimeRealUs) * (double)mPlaybackRate;
if (mediaUs > mMaxTimeMediaUs && !allowPastMaxTime) {
mediaUs = mMaxTimeMediaUs;
}
if (mediaUs < mStartingTimeMediaUs) {
mediaUs = mStartingTimeMediaUs;
}
if (mediaUs < 0) {
mediaUs = 0;
}
*outMediaUs = mediaUs;
return OK;
}将这几个公式总结起来,就是:
realTimeUs = pts - nowMediaUs + nowUs;
= pts - (mAnchorTimeMediaUs + (nowUs - mAnchorTimeRealUs)) + nowUs
为什么这么复杂呢?个人理解,这么做是为了音视频同步的精度,因为nowUs一直在变化,而函数的执行同样需要消耗时间,每一步中都会去重新获取nowUs来增加精度。
用图来表示,就是nowMediaUs是不断变化的,在它的变化过程中,我们不断的打下锚点,但是锚点是滞后nowMediaUs的:
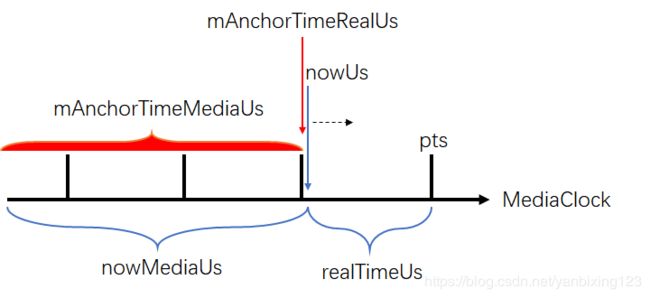
而我们希望计算一个比较精确的realTimeUs,所以就采用这种方式来计算:

通过这种方法大概就是优化了图中阴影位置的时间。
之后就是VideoFrameScheduler::schedule()函数了,这个函数根据vsync来调整视频帧应该显示的时间:
nsecs_t VideoFrameScheduler::schedule(nsecs_t renderTime) {
nsecs_t origRenderTime = renderTime;
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
if (now >= mVsyncRefreshAt) {
updateVsync();
}
// without VSYNC info, there is nothing to do
if (mVsyncPeriod == 0) {
ALOGV("no vsync: render=%lld", (long long)renderTime);
return renderTime;
}
// ensure vsync time is well before (corrected) render time
if (mVsyncTime > renderTime - 4 * mVsyncPeriod) {
mVsyncTime -=
((mVsyncTime - renderTime) / mVsyncPeriod + 5) * mVsyncPeriod;
}
// Video presentation takes place at the VSYNC _after_ renderTime. Adjust renderTime
// so this effectively becomes a rounding operation (to the _closest_ VSYNC.)
renderTime -= mVsyncPeriod / 2;
const nsecs_t videoPeriod = mPll.addSample(origRenderTime);
if (videoPeriod > 0) {
// Smooth out rendering
size_t N = 12;
nsecs_t fiveSixthDev =
abs(((videoPeriod * 5 + mVsyncPeriod) % (mVsyncPeriod * 6)) - mVsyncPeriod)
/ (mVsyncPeriod / 100);
// use 20 samples if we are doing 5:6 ratio +- 1% (e.g. playing 50Hz on 60Hz)
if (fiveSixthDev < 12) { /* 12% / 6 = 2% */
N = 20;
}
nsecs_t offset = 0;
nsecs_t edgeRemainder = 0;
for (size_t i = 1; i <= N; i++) {
offset +=
(renderTime + mTimeCorrection + videoPeriod * i - mVsyncTime) % mVsyncPeriod;
edgeRemainder += (videoPeriod * i) % mVsyncPeriod;
}
mTimeCorrection += mVsyncPeriod / 2 - offset / (nsecs_t)N;
renderTime += mTimeCorrection;
nsecs_t correctionLimit = mVsyncPeriod * 3 / 5;
edgeRemainder = abs(edgeRemainder / (nsecs_t)N - mVsyncPeriod / 2);
if (edgeRemainder <= mVsyncPeriod / 3) {
correctionLimit /= 2;
}
// estimate how many VSYNCs a frame will spend on the display
nsecs_t nextVsyncTime =
renderTime + mVsyncPeriod - ((renderTime - mVsyncTime) % mVsyncPeriod);
if (mLastVsyncTime >= 0) {
size_t minVsyncsPerFrame = videoPeriod / mVsyncPeriod;
size_t vsyncsForLastFrame = divRound(nextVsyncTime - mLastVsyncTime, mVsyncPeriod);
bool vsyncsPerFrameAreNearlyConstant =
periodicError(videoPeriod, mVsyncPeriod) / (mVsyncPeriod / 20) == 0;
if (mTimeCorrection > correctionLimit &&
(vsyncsPerFrameAreNearlyConstant || vsyncsForLastFrame > minVsyncsPerFrame)) {
// remove a VSYNC
mTimeCorrection -= mVsyncPeriod / 2;
renderTime -= mVsyncPeriod / 2;
nextVsyncTime -= mVsyncPeriod;
if (vsyncsForLastFrame > 0)
--vsyncsForLastFrame;
} else if (mTimeCorrection < -correctionLimit &&
(vsyncsPerFrameAreNearlyConstant || vsyncsForLastFrame == minVsyncsPerFrame)) {
// add a VSYNC
mTimeCorrection += mVsyncPeriod / 2;
renderTime += mVsyncPeriod / 2;
nextVsyncTime += mVsyncPeriod;
if (vsyncsForLastFrame < ULONG_MAX)
++vsyncsForLastFrame;
}
ATRACE_INT("FRAME_VSYNCS", vsyncsForLastFrame);
}
mLastVsyncTime = nextVsyncTime;
}
// align rendertime to the center between VSYNC edges
renderTime -= (renderTime - mVsyncTime) % mVsyncPeriod;
renderTime += mVsyncPeriod / 2;
ALOGV("adjusting render: %lld => %lld", (long long)origRenderTime, (long long)renderTime);
ATRACE_INT("FRAME_FLIP_IN(ms)", (renderTime - now) / 1000000);
return renderTime;
}这里还应该有个倍速播放的分析,其实就是在计算时间时把倍速算进去,下次有时间再修改这篇文章,加进去。
讲述AVSYNC的文章中,这个最清晰了,墙裂推荐:
https://blog.csdn.net/nonmarking/article/details/78746671
此文结束。
