找工作笔试面试那些事儿(1)---C,C++基础和编程风格(2)
作者:寒小阳
时间:2013年8月。
出处:http://blog.csdn.net/han_xiaoyang/article/details/10515417。
声明:版权所有,转载请注明出处,谢谢。
四、表达式和基本语句
4.1 运算符与复合表达式
首先非常重要的一个点是C/C++运算符的优先级问题,下图为总结的一张表,结合律特殊的运算符已经用黑体加粗标明出来了。
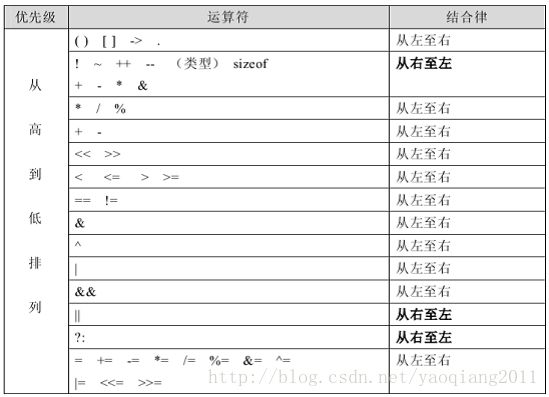
说实话,上表中的运算符优先级和结合律要熟记是非常困难的。虽说有表在,但是也不能每次都查表,所以我们在写程序的时候尽量要遵循后续规则:
如果代码行中的运算符比较多,用括号确定表达式的操作顺序,避免使用默认的优先级。
例:word = (high << 8) | low和if ((a | b) && (a & c))
对于复合表达式的一些建议:
1)不要编写太复杂的复合表达式。例如i = a >= b && c < d && c + f <= g + h ;就太复杂
2)不要有多用途的复合表达式。例如d = (a = b + c) + r ;应该拆成两个语句
3)不要把程序中的复合表达式与“真正的数学表达式”混淆。
4.2 if语句
if语句看似C ++/C语言中最简单、最常用的语句,然而很多程序员用隐含错误的方式写if语句。同时笔试面试的时候有些公司还是非常热衷于考察这个点,作为对应聘者基础知识扎实度评判的标准。
考察最多的是if语句各种与零值比较的语句写法:
1)布尔变量与零值比较
不要将布尔变量直接与TRUE 、FALSE 或者1、0 进行比较。假设布尔变量名字为flag,它与零值比较的标准if 语句如下:
if (flag) // 表示flag为真
其它的用法都属于不良风格,例如:
if (flag == TRUE)
if (flag == 1 )
if (flag == FALSE)
if (flag == 0)
2)整型变量与零值比较
应当将整型变量用“==”或“!= ”直接与0 比较。假设整型变量的名字为value,它与零值比较的标准if 语句如下:
if (value == 0)
if (value != 0)
不可模仿布尔变量的风格而写成
if (value) // 会让人误解 value是布尔变量
if (!value)
3)浮点变量与零值比较
不可将浮点变量用“==”或“!= ”与任何数字比较。千万要留意,无论是f loat 还是double类型的变量,都有精度限制。所以一定要避免将浮点变量用“==”或“!= ”与数字比较,应该设法转化成“>=”或“<=”形式。
假设浮点变量的名字为x ,应当将
if (x == 0.0) // 隐含错误的比较
转化为
if ((x>=-EPSINON) && (x<=EPSINON))
其中EPSINON 是允许的误差(即精度)
4)指针变量与零值比较
应当将指针变量用“==”或“!= ”与NULL比较。指针变量的零值是“空”(记为NULL)。尽管NUL L 的值与0 相同,但是两者意义不同。假设指针变量的名字为p ,它与零值比较的标准if 语句如下:
if (p == NULL) // p与NULL显式比较,强调p 是指针变量
if (p != NULL)
不要写成
if (p == 0) // 容易让人误解p 是整型变量
if (p != 0)
或者
if (p) // 容易让人误解p 是布尔变量
if (!p)
关于if语句的补充点:if (NULL == p) 这样古怪的格式,并不是程序员写错了,是为了防止将if (p == NULL)误写成if (p = NULL) ,而有意把p和NULL颠倒。编译器认为 if (p = NULL) 是合法的,但是会指出 if (N ULL = p)是错误的,因为NULL不能被赋值。
4.3 关于循环语句
C++/C循环语句中,for 语句使用频率最高,w hile语句其次,do语句很少用。这里从for循环出发,提出几点需要注意的点:
1)在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少CPU 跨切循环层的次数。
例如以下图右比左执行效率高:

2)如果循环体内存在逻辑判断,并且循环次数很大,宜将逻辑判断移到循环体的外面。如下图右框内的程序,简洁度略有下降,但是执行效率却大幅度提高。

3)不可在for 循环体内修改循环变量,防止for 循环失去控制。
4)建议for 语句的循环控制变量的取值采用“半开半闭区间”写法。如下左所示:

4.4 关于switch语句
Switch语句格式如下所示:

注意点:
1)每个cas e 语句的结尾不要忘了加break,否则将导致多个分支重叠(除非有意使多个分支重叠)。
2)不要忘记最后那个default 分支。即使程序真的不需要default 处理,也应该保留语句 default : break; 这样做并非多此一举,而是为了防止别人误以为你忘了default 处理。
五、常量
C 语言用 #define来定义常量(称为宏常量)。C++ 语言除了 #define外还可以用const来定义常量(称为const常量),常量是一种标识符,它的值在运行期间恒定不变。
5.1. 常量的意义
这个在笔试面试的时候也考过几次啊,属于比较基础比较细节的东西。总结下来主要是不使用常量的话有以下三个缺点:
1 ) 程序的可读性(可理解性)变差。程序员自己会忘记那些数字或字符串是什么意思,用户则更加不知它们从何处来、表示什么。
2 ) 在程序的很多地方输入同样的数字或字符串,难保不发生书写错误。
3 ) 如果要修改数字或字符串,则会在很多地方改动,既麻烦又容易出错。
但注意,我们在定义常量时要尽量使用含义直观的常量来表示那些将在程序中多次出现的数字或字符串。
例如:
#define MAX 100 /* C 语言的宏常量 */
const int MAX = 100; // C++ 语言的const 常量
const float PI = 3.14159; // C++ 语言的const 常量
5.2 C++常量两种定义方式的不同
C++ 语言可以用const和#define两种定义常量的方式,但是建议使用前者,因为:
1)const常量有数据类型,而宏常量没有数据类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且在字符替换可能会产生意料不到的错误(边际效应)。
2)有些集成化的调试工具可以对const 常量进行调试,但是不能对宏常量进行调试。
5.3 常量定义的相关规则
简单说来,定义常量的时候,最好遵循以下规则:
1)需要对外公开的常量放在头文件中,不需要对外公开的常量放在定义文件的头部。为便于管理,可以把不同模块的常量集中存放在一个公共的头文件中。
2)如果某一常量与其它常量密切相关,应在定义中包含这种关系,而不应给出一些孤立的值。
例如: const float RADIUS = 100;
const float DIAMETER = RADIUS * 2;
5.4 关于类中的常量
非常重要的一点,也是常犯的错误,有时我们希望某些常量只在类中有效,所以想当然地觉得应该用const修饰数据成员来实现。但是const 数据成员只在某个对象生存期内是常量,而对于整个类而言却是可变的,因为类可以创建多个对象,不同的对象其const 数据成员的值可以不同。
所以:不能在类声明中初始化const 数据成员。因为类的对象未被创建时,编译器不知道SIZE的值是什么。const 数据成员的初始化只能在类构造函数的初始化表中进行。
如果想建立在整个类中都恒定的常量。const数据成员是完成不了滴,应该用类中的枚举常量来实现。
class A
{…
enum { SIZE1 = 100, SIZE2 = 200}; // 枚举常量
int array1[SIZE1];
int array2[SIZE2];
};
枚举常量不会占用对象的存储空间,它们在编译时被全部求值。枚举常量的缺点是:它的隐含数据类型是整数,其最大值有限,且不能表示浮点数(如PI=3.14159)。