图像算法面试之YOLO系列
**
图像算法面试之YOLO系列
起因:最近面试频繁被面试官问到YOLO系列相关知识,加深自己印象,写一写
面试题:描述一下yolo2的思想,yolo3有什么不同
YOLOV1
yolo的思想:将整张图片作为输入,直接在输出层回归bounding box的位置及其所属类别
和RCNN、faster-RCNN的不同:这两者也是将整张图片作为输入,但是faster-RCNN采用RCNN的proposal+classifier思想。将提取proposal的步骤放在CNN中,而yolo则采用直接回归的思想
实现方法:
1、将image分成S*S个grid cell,如果某个object的中心落在grid cell中,则由这个grid cell负责预测该object
2、每个grid cell负责预测B个bounding box,每个bounding box除了要回归自身的位置和大小外,还需要预测一个confidence
3、这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准
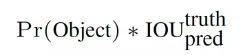
每个bounding box 要预测(x,y,w,h)和confidence。每个grid cell要预测一个类别信息,记为C类。则SS个grid cell,每个grid要预测B个bounding box和C个类别,输出就是:SS*(5*B+C)的tensor
4、在test时,每个grid cell预测的class信息和bounding box预测的confidence相乘,得到每个bounding box的class-specific confidence score:![]()
得到的每个class-specific confidence score之后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终结果
缺陷:
1、输出层为全连接层,在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率
2、虽然每个grid cell可以预测B个bounding box,但最终只选择IOU最高的bounding box作为检测输出,即每个grid最多只预测一个物体
YOLOV2改进
1、使用BN,提高网络收敛性,对每一个卷卷积层增加BN
2、YOLOv1有全连接,从而只能直接预测bounding box的坐标值。Faster-RCNN的方法只用卷积层与Region proposal Network来预测anchor box偏移值与置信度,而不直接预测坐标值。发现通过预测偏移值而非坐标值能够简化问题。去掉全连接。使用Anchor box来预测bounding box
3、Anchor box,在训练集的bounding box跑一下,k-means聚类,找到一个较好的值
4、更精细度的特征,加上passthrough layer来取得之前某个26*26分辨率特征,把高分辨率和低分辨率特征联系在一起
5、多尺度训练,yolov2每迭代几次都会改变网络参数,每10个batch,网络随机选择新图片尺寸
YOLOV3改进
1、多尺度预测
2、更好的基础网络(类resnet)和分类器darknet 53
3、分类器-类别预测
1、多尺度预测:
每种尺度预测3个box,anchor依然使用聚类,得到9个聚类中心,将其按大小均分给3个尺度
*尺度1:在基础网络之后添加一些卷积层再输出box信息
尺度2:从尺度1中的倒数第二层卷积层上采样再与最后一个1616大小特征图相加,再次通过多个卷积后输出box信息,相比尺度1变大两倍
尺度3:与尺度2类似,使用3232大小特征图
3、分类器-类别预测:
yolov3不使用softmax分类,因为softmax使得每个框只能识别一个类别,而用多个logstic分类器替代softmax准确率不会下降,分类损失采用binary cross-entropy loss
补:
BN就是把隐层神经元激活输入x=WU+B(U是输入)从变化布局一格的正太分布通过BN操作拉回到了均值为0。方差为1的正太分布,即原始正态分布中信左移或者右移到以0为均值,拉伸或者缩减形态形成以1为方差的图像。也就是说经过BN后,目前大部分Activation的值落入非线性函数的线性区间内,其对应的导数远离导数饱和区,这样来加速训练收敛过程
感谢:
感谢https://blog.csdn.net/guleileo/article/details/80581858#commentBox博主的分享,详细内容大家可以学习该博主分享