python爬取下载b站视频
python爬虫系列:
上一篇
python爬取图虫网图库
今天突然来了兴趣想要爬取下载b站视频,话不多说,说干就干。
Usage
下载仓库
[email protected]:inspurer/PythonSpider.git
或者直接下载:https://github.com/inspurer/PythonSpider/tree/master/bilibili
替换
随便打开一个b站的界面,比如
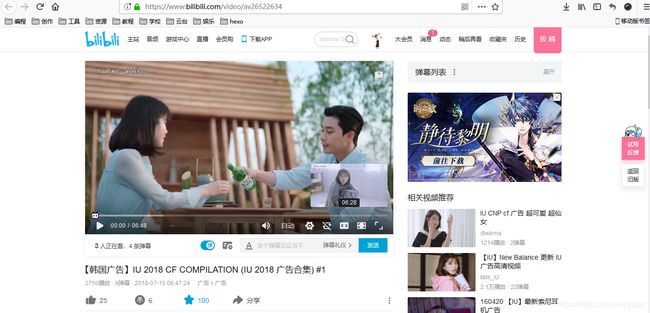 将url复制到代码中去,运行代码,稍等一会儿,上述图中的视频就被下载下来了。
将url复制到代码中去,运行代码,稍等一会儿,上述图中的视频就被下载下来了。
How to Code
分析网页源码
按f12浏览器开发者工具 ,通过一番审查,我们定位到视频的url在网页源代码的位置如下:
window.__playinfo__={
"from":"local",
"result":"suee",
"quality":32,
"format":"flv480",
"timelength":408884,
"accept_format":"flv720,flv480,flv360",
"accept_description":["高清 720P","清晰 480P","流畅 360P"],
"accept_quality":[64,32,15],
"video_codecid":7,
"video_project":true,
"seek_param":"start",
"seek_type":"offset",
"durl":[{"order":1,"length":408884,"size":42782550,"ahead":"EhA=","vhead":"AWQAHv/hAB5nZAAerNlA2D3n//AoACfxAAADAAEAAAMAMA8WLZYBAAVo6+zyPA==",
"url":"http://upos-hz-mirrorkodo.acgvideo.com/upgcxcode/48/61/45596148/45596148-1-32.flv?e=ig8euxZM2rNcNbRa7b4VhoMz7WhjhwdEto8g5X10ugNcXBlqNxHxNEVE5XREto8KqJZHUa6m5J0SqE85tZvEuENvNC8xNEVE9EKE9IMvXBvE2ENvNCImNEVEK9GVqJIwqa80WXIekXRE9IB5QK==&deadline=1543136253&dynamic=1&gen=playurl&oi=1862807981&os=kodo&platform=pc&rate=176800&trid=69ea1a81ac21448f9e2189ef479a2d6d&uipk=5&uipv=5&um_deadline=1543136253&um_sign=c479f3fd3075b359d0a04e5eb584ac55&upsig=1c05ca3838af92d2c1411cf3000e8345http://upos-hz-mirrorkodo.acgvideo.com/upgcxcode/48/61/45596148/45596148-1-32.flv?e=ig8euxZM2rNcNbRa7b4VhoMz7WhjhwdEto8g5X10ugNcXBlqNxHxNEVE5XREto8KqJZHUa6m5J0SqE85tZvEuENvNC8xNEVE9EKE9IMvXBvE2ENvNCImNEVEK9GVqJIwqa80WXIekXRE9IB5QK==&deadline=1543136253&dynamic=1&gen=playurl&oi=1862807981&os=kodo&platform=pc&rate=176800&trid=69ea1a81ac21448f9e2189ef479a2d6d&uipk=5&uipv=5&um_deadline=1543136253&um_sign=c479f3fd3075b359d0a04e5eb584ac55&upsig=1c05ca3838af92d2c1411cf3000e8345","backup_url":["http://upos-hz-mirrorcos.acgvideo.com/upgcxcode/48/61/45596148/45596148-1-32.flv?um_deadline=1543136253&platform=pc&rate=176800&oi=1862807981&um_sign=c479f3fd3075b359d0a04e5eb584ac55&gen=playurl&os=cos&trid=69ea1a81ac21448f9e2189ef479a2d6d"]}]}
最后的url就是我们想要的结果。
如果在浏览器中查找不方便的话,我们可以把通过代码把网页源码输出到本地
response = requests.get(url='https://www.bilibili.com/video/av26522634', headers= self.getHtmlHeaders)
print(response.status_code)
if response.status_code == 200:
print(response.text)
为了伪装成浏览器,我们需要在reqests添加Headers
这个Headers需要我们去浏览器中手动获取
切换到NetWork标签下,再选择Headers,

self.getHtmlHeaders={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q = 0.9'
}
这里只选择了几个关键的
解析得到视频地址
根据上一步分析,我们得到了网页的源码,并在源码中定位到了视频地址,接下来,我们就用代码自动获取这个地址了
#用正则、json得到视频url;用pq失败后的无奈之举
pattern = r'\window\.__playinfo__=(.*?)\ '
result = re.findall(pattern, html)[0]
temp = json.loads(result)
#temp['durl']是一个列表,里面有很多字典
#video_url = temp['durl']
for item in temp['data']['durl']:
if 'url' in item.keys():
video_url = item['url']
顺便获取下视频的名字:
#用pq解析得到视频标题
doc = pq(html)
video_title = doc('#viewbox_report > h1 > span').text()
然后组合返回下:
return{
'title': video_title,
'url': video_url
}
下载视频
通过在开发者工具中搜索关键词,比如上面得到的视频url,我们可以定位到在浏览器中真正下载视频的请求在哪
 然后把它的Headers添加到reqests中,就可以下载视频了
然后把它的Headers添加到reqests中,就可以下载视频了
with open(filename, "wb") as f:
f.write(requests.get(url=url, headers=self.downloadVideoHeaders, stream=True, verify=False).content)
愉快地观看本地视频
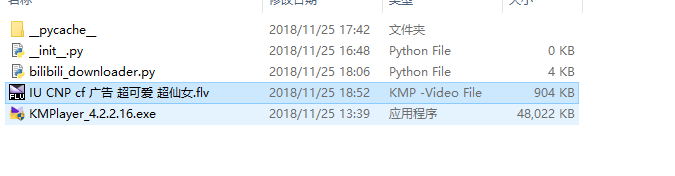 如果你下载的视频在本地播放不了,请不要试图修改源代码中保存文件的格式由
如果你下载的视频在本地播放不了,请不要试图修改源代码中保存文件的格式由.flv改成.mp4,因为b站的视频本来就是flv格式的,需要用特殊的视频播放器播放,这里推荐一个无毒无害的KMPlayer,https://pan.baidu.com/s/1DBOaPGbdTXOvodbrZRhzmQ,提取码:fw0b
源代码
工程所有源代码均已上传至github,https://github.com/inspurer/PythonSpider/tree/master/bilibili
欢迎star,fork。