自然语言处理-错字识别(基于Python)kenlm、pycorrector
转载出处:https://blog.csdn.net/HHTNAN
中文文本纠错划分
中文文本纠错任务,常见错误类型包括:
- 谐音字词,如 配副眼睛-配副眼镜
- 混淆音字词,如 流浪织女-牛郎织女
- 字词顺序颠倒,如 伍迪艾伦-艾伦伍迪
- 字词补全,如爱有天意-假如爱有天意
- 形似字错误,如 高梁-高粱
- 中文拼音全拼,如 xingfu-幸福
- 中文拼音缩写,如 sz-深圳
- 语法错误,如想象难以-难以想象
当然,针对不同业务场景,这些问题并不一定全部存在,比如输入法中需要处理前四种,搜索引擎需要处理所有类型,语音识别后文本纠错只需要处理前两种, 其中’形似字错误’主要针对五笔或者笔画手写输入等。
简单总结了一下中文别字错误类型:
- 别字: 感帽,随然,传然,呕土
- 人名,地名错误:哈蜜(正:哈密)
- 拼音错误:咳数(ke shu)—> ke sou,
- 知识性错误:广州黄浦(埔)
- 用户发音、方言纠错:我系东北滴黑社会,俚蛾几现在在我手上。(我是东北的黑社会,你儿子现在在我手上。)
- 重复性错误:在 上 上面 上面 那 什么 啊
- 口语化问题:呃 。 呃 ,啊,那用户名称是叫什么呢?(正:那用户名称是叫什么呢?)
解决方案
规则的解决思路
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误,整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
- 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
深度模型的解决思路
- 端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,rnn_attention在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
- CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
- seq2seq模型是使用encoder-decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一。
特征
- kenlm: kenlm统计语言模型工具
- rnn_lm: TensorFlow、PaddlePaddle均有实现栈式双向LSTM的语言模型
- rnn_attention模型: 参考Stanford
- University的nlc模型,该模型是参加2014英文文本纠错比赛并取得第一名的方法
- rnn_crf模型: 参考阿里巴巴2016参赛中文语法纠错比赛并取得第一名的方法
- seq2seq模型: 使用序列模型解决文本纠错任务,文本语法纠错任务中常用模型之一
- seq2seq_attention模型: 在seq2seq模型加上attention机制,对于长文本效果更好,模型更容易收敛,但容易过拟合
错误检测
- 字粒度:语言模型困惑度(ppl)检测某字的似然概率值低于句子文本平均值,则判定该字是疑似错别字的概率大。
- 词粒度:切词后不在词典中的词是疑似错词的概率大。
错误纠正
- 通过错误检测定位所有疑似错误后,取所有疑似错字的音似、形似候选词
- 使用候选词替换,基于语言模型得到类似翻译模型的候选排序结果,得到最优纠正词
思考
现在的处理手段,在词粒度的错误召回还不错,但错误纠正的准确率还有待提高,更多优质的纠错集及纠错词库会有提升,我更希望算法上有更大的突破。
另外,现在的文本错误不再局限于字词粒度上的拼写错误,需要提高中文语法错误检测(CGED, Chinese Grammar Error Diagnosis)及纠正能力,列在TODO中,后续调研。
pycorrector
中文文本纠错工具。音似、形似错字(或变体字)纠正,可用于中文拼音、笔画输入法的错误纠正。python3开发。
pycorrector依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
安装
pip install pycorrector
结果报错

根据报错继续执行pip install pypinyin 安装pypinyin模块。
之后执行pip install pycorrector还是报错。
算了还是换成半自动安装吧
我擦还是不行。经过辗转反侧的查询。最后执行
pip install https://github.com/kpu/kenlm/archive/master.zip
之后在执行pip install pycorrector/。。。成功了。

以上安装参考连接:
https://github.com/kpu/kenlm
https://github.com/shibing624/pycorrector
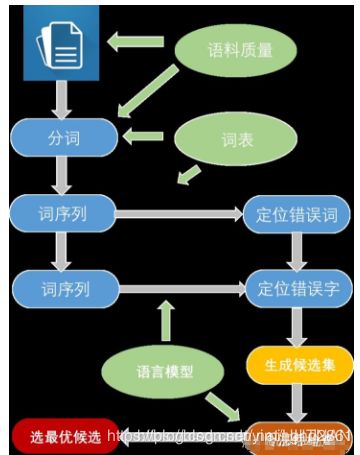
其工作流程如下:
几个现成的工具包:
- https://github.com/shibing624/pycorrector pycorrector
简介:考虑了音似、形似错字(或变体字)纠正,可用于中文拼音、笔画输入法的错误纠正,能够给出给出出错位置。
语言模型:
Kenlm(统计语言模型工具)
RNNLM(TensorFlow、PaddlePaddle均有实现栈式双向LSTM的语言模型)
代码:
import pycorrector
corrected_sent, detail = pycorrector.correct(‘少先队员因该为老人让坐’)
print(corrected_sent, detail)
单词、短句效果:9/13 效果尚可
速度:0.366050 all, 0.028157692 avg ;
可扩展性:词典可扩展,可使用自己的语料进行训练,该repo使用的是人民日报数据。扩展性强。
测试样本效果:‘感帽了’,‘你儿字今年几岁了’, ‘少先队员因该为老人让坐’,‘随然今天很热’,‘传然给我’,‘呕土不止’,‘哈蜜瓜’,‘广州黄浦’,‘在 上 上面 上面 那 什么 啊’,‘呃 。 呃 ,啊,那用户名称是叫什么呢?’, ‘我生病了,咳数了好几天’, ‘对京东新人度大打折扣’,‘我想买哥苹果手机’
- https://github.com/ccheng16/correction 10 months ago
简介:
使用语言模型计算句子或序列的合理性
bigram, trigram, 4-gram 结合,并对每个字的分数求平均以平滑每个字的得分
根据Median Absolute Deviation算出outlier分数,并结合jieba分词结果确定需要修改的范围
根据形近字、音近字构成的混淆集合列出候选字,并对需要修改的范围逐字改正
句子中的错误会使分词结果更加细碎,结合替换字之后的分词结果确定需要改正的字
探测句末语气词,如有错误直接改正
特点:
训练的语言模型很多,根据介绍看,整体比较完善,看起来高大上。不过code跑不起来,作者没回应—–后面再改一下作者代码,看看能否跑起来。
- https://github.com/PengheLiu/Cn_Speck_Checker 2 years ago
简介:
针对医学数据训练出来的,基于编辑距离,可自行训练–效果一般,统计词频和共现信息,不太完善,返回大量candidates
特点:
人们通常越往后字打错的可能越大,因而可以考虑每个字在单词中的位置给予一定权重,这中方法有助于改进上面的第一种“传然”- "虽然"的情况;
考虑拼音的重要性,对汉语来讲,通常人们打错时拼音是拼对的,只是选择时候选择错了,因而对候选词也可以优先选择同拼音的字。
单词、短句效果:1/13 效果差,因为训练语料是医学文章
速度:None
可扩展性:词典+模型。扩展性还可以。
测试样本效果:‘感帽了’,‘你儿字今年几岁了’, ‘少先队员因该为老人让坐’,‘随然今天很热’,‘传然给我’,‘呕土不止’,‘哈蜜瓜’,‘广州黄浦’,‘在 上 上面 上面 那 什么 啊’,‘呃 。 呃 ,啊,那用户名称是叫什么呢?’, ‘我生病了,咳数了好几天’, ‘对京东新人度大打折扣’,‘我想买哥苹果手机’
- proofreadv1 – 效果一般,主要用于搜索引擎中的搜索关键词的别字纠错 5 years ago
词频字典+bi-gram
https://github.com/apanly/proofreadv1
模型比较老旧,不考虑
- https://github.com/taozhijiang/chinese_correct_wsd 3 years ago
京东客服机器人语料做的中文纠错–更接近我们的应用场景,主要解决同音自动纠错问
题,比如:
对京东新人度大打折扣 – > 对京东信任度大打折扣
我想买哥苹果手机 纠正句:我想买个苹果手机
但代码多年未更新,目前跑不起来。
- https://github.com/beyondacm/Autochecker4Chinese 9 months ago
original sentence:感帽,随然,传然,呕土
corrected sentence:感冒,虽然,传染,呕吐
original sentence:对京东新人度大打折扣,我想买哥苹果手机
corrected sentence:对京东新人度大打折扣,我国买卖苹果手机
单词、短句效果:5/13 效果差
速度:2.860311 all , 0.220023 avg; with print
可扩展性:词典可扩展,不使用自己的语料进行训练。扩展性一般。
测试样本效果:‘感帽了’,‘你儿字今年几岁了’, ‘少先队员因该为老人让坐’,‘随然今天很热’,‘传然给我’,‘呕土不止’,‘哈蜜瓜’,‘广州黄浦’,‘在 上 上面 上面 那 什么 啊’,‘呃 。 呃 ,啊,那用户名称是叫什么呢?’, ‘我生病了,咳数了好几天’, ‘对京东新人度大打折扣’,‘我想买哥苹果手机’
- https://github.com/SeanLee97/xmnlp 3-4 months ago
nlp工具包,包含分词、情感分析,没有专注于错别字纠正,效果较差
单词、短句效果:3/13 效果差
速度:2.860311 all , 0.220023 avg; without print: 0:00:00.000017 all
可扩展性:既没发现词典、也没发现模型。扩展性较差。
测试样本效果:‘感帽了’,‘你儿字今年几岁了’, ‘少先队员因该为老人让坐’,‘随然今天很热’,‘传然给我’,‘呕土不止’,‘哈蜜瓜’,‘广州黄浦’,‘在 上 上面 上面 那 什么 啊’,‘呃 。 呃 ,啊,那用户名称是叫什么呢?’, ‘我生病了,咳数了好几天’, ‘对京东新人度大打折扣’,‘我想买哥苹果手机’
总结:
- 效果:现有错别字纠正package大部分是通用领域的错别字检查,缺乏统一的评判标准,效果参差不齐。长句效果差,短句、单词效果好一些,未来应用到产品中,也要根据标点符号截成短句,再进行错别字检查。
- 口语化、重复性的问题,所有package不能解决此类问题。
- 误判率的问题!!!错别字纠正功能有可能把正确的句子改成错误的。。这就要求,正确率x要远大于误判率y。假设有m个问题,其中2%是有错别字的,m*2%x>m(1-2%)*y,根据个人的经验,误判率y是可以控制在1%以下的,如果有比较好的词表,可以控制在0.5%以下。根据上述不等式,误判率控制在0.5%以下,正确率达到24.5%就能满足上述不等式。
- 项目中,若测试数据不含重复错别字样本(错别字:帐单,其中的帐这个错别字只出现过一次),错别字纠正的正确率达到了50%,误判率0.49%左右。若包含重复样本,正确率达到了70%以上。
后面这三点比较关键:
- 项目中使用了基于n-gram语言模型,使用kenLM训练得到的,DNN LM和n-gram LM各有优缺点,这里卖个关子,感兴趣的可以思考一下二者区别。另外,基于字的语言模型,误判率会较高;基于词的语言模型,误判率会低一些(符合我个人的判断,在我的实验里情况也确实如此)。
- 训练语言模型的语料中并不clean,包含了很多错别字,这会提高误判率。使用更干净的语料有助于降低误判率,提高正确率。
- 专业相关词表很关键,没有高质量的词表,很多字也会被误认为是错别字,所以也会提高误判率。
测试样本:
‘感帽了’,‘你儿字今年几岁了’, ‘少先队员因该为老人让坐’,‘随然今天很热’,‘传然给我’,‘呕土不止’,‘哈蜜瓜’,‘广州黄浦’,‘在 上 上面 上面 那 什么 啊’,‘呃 。 呃 ,啊,那用户名称是叫什么呢?’, ‘我生病了,咳数了好几天’, ‘对京东新人度大打折扣’,‘我想买哥苹果手机’
效果评价简介:
a. 单词、短句效果:一共13个测试样本,9/13表示13个样本中,纠正了9个错误。(长句效果差,没有考虑)
b. 速度:考虑了13个样本的总时间(用all表示,单位统一为秒),以及平均每个样本的纠错时间(用avg表示)
其中, with print 表示该纠错方法的用时包含了“输出到terminal的时间”,without print表示该纠错方法的用时没有包含“输出到terminal的时间”。这么划分的原因是 输出到terminal比较耗时,部分package可以选择输出or不输出。
c. 可扩展性:主要(1)考虑该纠错方法是否包含 自定义的错别字词典,方便个性化定制;(2)考虑该纠错方法,是否提供模型代码方便,在小娜的文本上进行训练语言模型。