Hive
文章目录
- 1.Hive是什么
- 1.1 Hive与传统数据库的区别
- 1.2 关于Hive的索引与事务
- 2.Hive架构
- 3.Hive 上SQL执行的大致过程
- 4.Hive 服务组件及用途
- 4.1 服务端组件
- 4.2 客户端组件:
- 4.3 总结
- 4.3.1 关于Hive cli
- 4.3.2 关于HiveServer2与HiveServer
- 4.3.3 关于Thrift的简单说明
- 4.3.4 关于BeeLine
- 4.3.5 关于HCatalog
- 5.Hive配置
- 6.数据存储、数据文件
- 6.1 关于分区与分桶
- 6.1.1 Hive 分区表
- 6.1.2 Hive 桶
- 6.2 Hive元数据存储
- 6.3 Hive数据文件存储:存储文件格式
- 7.Hive执行引擎Tez与MapReduce
- 7.1 关于Tez
- 遇到的问题
- HiveServer2无法启动
- User:hcat is not allowed to impersonate ambari-qa
- HiveServer2正常后,Hive客户端进不去
1.Hive是什么
Hive是一个基于Hadoop的数据仓库基础工具,用于处理处理结构化数据

关于Hive,需要明确如下几点:
(1)hive本身不提供数据存储功能,使用HDFS做数据存储,
(2)hive也不提供分布式计算框架,hive的核心工作就是把sql语句翻译成MR程序
(3)hive也不提供资源调度系统,也是默认由Hadoop当中YARN集群来调度
1.1 Hive与传统数据库的区别
主要区别:
①数据库可以用在Online的应用中,Hive主要进行离线的大数据分析;
②数据库的查询语句为SQL,Hive的查询语句为HQL;
③数据库数据存储在LocalFS,Hive的数据存储在HDFS;
④Hive执行MapReduce,MySQL执行Executor;
⑤Hive侧重于分析,而非实时在线交易
⑥Hive延迟性高;
⑦Hive可扩展性高;
⑧Hive数据规模大;
1.2 关于Hive的索引与事务
(1)读时模式 vs 写时模式
用过数据库的都知道,数据库需要在创建时制定好数据格式,也就是俗称的建表。传统数据库和Hive在使用前都需要建表,但是不知道小伙伴们有没有遇到这种情况。传统数据库在建表之后往里面导数据时,通常会因为很多问题导致SQL异常,从而加载出错,而常见的情况就是数据格式不对。传统数据库在加载数据的时候会严格检查数据格式,如果不符合规范就会拒绝加载。而这种验证过程将耗费大量时间,这对于大数据而言,时间上是无法满足需求的。
Hive在插入数据的时候并不会验证数据,它只会在查询的时候验证。这种加载时验证的方式称之为读时模式,而查询时验证的方式则称之为写时模式。
(2) 更新
Hive在执行HQL语句的时候,后台其实还是使用MapReduce程序来完成任务的,而普通数据库则是借助自己的引擎。
MapReduce是基于HDFS系统的,通常而言Hive处理数据都是读多写少。Hive的表更新是采用覆盖的方式,而这种情况下处理数据绝大部分都会访问整个表。这对在大规模数据集上运行的数据仓库非常见效。
早期的Hive只能利用insert into语句,以增加文件的方式向表中批量增加行。而在0.14.0版本之后,Hive允许使用Insert into table … value语句,这代表着可以按行加数据,不过不能大量添加。另外update和delete操作也被允许执行了。
HDFS只能允许文件的覆盖,不允许文件的更新。所以update、delete和insert into操作引起的变化会存在一个很小的增量文件中。然后metastore在后台的MapReduce程序会将他们合并到“基表”中。这些操作就需要事务的支持,这样才能保证表的一致性。
(3)事务
Hive的隔离性是借助Zookeeper完成的。在0.7.0的版本Hive中,初次引入了锁的概念。有了锁则可以保证一个表的非查询操作在某一时刻只能由一个进程来执行。默认情况下锁功能是关闭的。
(4)索引
由于Hive是采用的写时模式,因此数据在加载的过程中不会被校验,因此也不会对数据建立索引。但是Hive并非不支持索引,只是Hive的索引只能建立在表的列上,而不支持主键或者外键。Hive的索引分为紧凑索引和位图索引。紧凑索引适用于值已经经过聚簇处理的情况,而位图索引适用于值的取值范围较小的情况。
其实对于更新、事务和索引,并非Hive不支持,而是影响性能,不符合最初数据仓库的设计理念。但是随着时间的发展,Hive在很多方面也做出了妥协,这也导致了Hive和传统数据库的区别越来越小。
2.Hive架构
https://cwiki.apache.org/confluence/display/Hive/Design#Design-HiveArchitecture

3.Hive 上SQL执行的大致过程

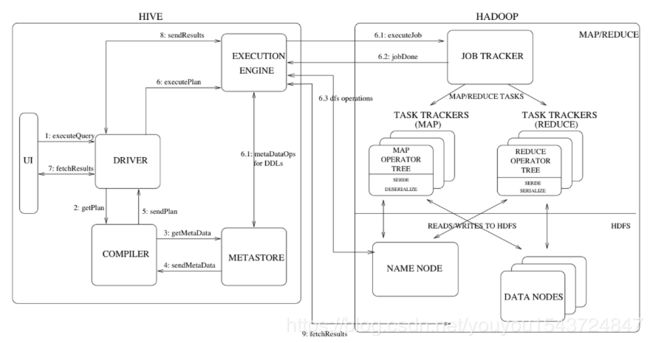
各个步骤说明:
- Execute Query Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。
- Get Plan 在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。
- Get Metadata 编译器发送元数据请求到Metastore(任何数据库)。
- Send Metadata Metastore发送元数据,以编译器的响应。
- Send Plan 编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
- Execute Plan 驱动程序发送的执行计划到执行引擎。
- Execute Job 在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
-
- Metadata Ops 与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。
- Fetch Result 执行引擎接收来自数据节点的结果。
- Send Results 执行引擎发送这些结果值给驱动程序。
- Send Results 驱动程序将结果发送给Hive接口。
4.Hive 服务组件及用途
https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-RunningWebHCat(Templeton)
4.1 服务端组件
(1) Driver组件
该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
(2)Metastore组件
元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性.
Hive的metastore组件是hive元数据集中存放地。Metastore组件包括两个部分:metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,
Hive的MetaStore组件可以单独部署。
(3) Thrift服务
thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
Hive Thrift服务由HiveServer2提供。
4.2 客户端组件:
(1) CLI
command line interface,命令行接口。
(2) Thrift客户端
上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
(3)WEBGUI
hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。
4.3 总结
4.3.1 关于Hive cli
https://cwiki.apache.org/confluence/display/Hive/Replacing+the+Implementation+of+Hive+CLI+Using+Beeline
Hive Cli目前属于一个过时的客户端工具。它主要有两个功能:1,用作一个在SQL on Hadoop重客户端;2,作为HiveServer1的命令行工具。目前,HiveServer1相关代码已经从Hive中移除了,取而代之的是HiveServer2。因此,Hive CLI的第二个用途就没有用了。对于对一个功能来说,Beeline可用来作为一个替代(或者说是被设计为提供Hive Cli同等的功能)。
最为理想的是将HiveCli相关的代码废弃(取而代之的是beeline+HiveServer2)。但是,考虑到有许多的历史代码都是使用的Hive cli(有许多已有的系统都是基于Hive Cli开发的,为了保持兼容性),目前,基于Beeline重新实现了Hive Cli (目前的Hive Cli是构建在Beeline之上的,可认为Hive cli 是Beeline的一个同名)
4.3.2 关于HiveServer2与HiveServer
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Overview
https://cwiki.apache.org/confluence/display/Hive/HiveServer
(1) HiveServer
HiveServer是一种可选服务,允许远程客户端可以使用各种编程语言向Hive提交请求并检索结果。HiveServer是建立在Apache ThriftTM(http://thrift.apache.org/) 之上的,因此有时会被称为Thrift Server,这可能会导致混乱,因为新服务HiveServer2也是建立在Thrift之上的.自从引入HiveServer2后,HiveServer也被称为HiveServer1。
PS:警告
HiveServer无法处理来自多个客户端的并发请求.这实际上是HiveServer导出的Thrift接口所施加的限制,也不能通过修改HiveServer源代码来解决。
HiveServer2对HiveServer进行了重写,来解决这些问题,从Hive 0.11.0版本开始。建议使用HiveServer2。
从Hive1.0.0版本(以前称为0.14.1版本)开始,HiveServer开始被删除。请切换到HiveServer2。
(2) HiveServer2
HiveServer2(HS2) 是一种能使用户可以在客户端上提交Hive查询的服务。 HiveServer2是HiveServer1的改进版。目前,HiveServer1已经被废弃。HiveServer2可以支持多客户端并发和身份认证。旨在为开放API客户端(如JDBC和ODBC)提供更好的支持。
HiveServer2单进程运行,提供组合服务,包括基于Thrift的Hive服务(TCP或HTTP)和用于Web UI的Jetty Web服务器。
基于Thrift的Hive服务是HiveServer2的核心,负责维护Hive查询(例如,从Beeline)。Thrift是构建跨平台服务的RPC框架。其堆栈由4层组成:server,Transport,Protocol和处理器。可以在 https://thrift.apache.org/docs/concepts 找到有关分层的更多详细信息。
4.3.3 关于Thrift的简单说明
Thrift是Facebook公布的一款开源跨语言的RPC框架。
thrift通过一个中间语言IDL(接口定义语言)来定义RPC的数据类型和接口,这些内容写在以.thrift结尾的文件中,然后通过特殊的编译器来生成不同语言的代码,以满足不同需要的开发者,比如java开发者,就可以生成java代码,c++开发者可以生成c++代码,生成的代码中不但包含目标语言的接口定义,方法,数据类型,还包含有RPC协议层和传输层的实现代码.

thrift是一种c/s的架构体系.在最上层是用户自行实现的业务逻辑代码.第二层是由thrift编译器自动生成的代码,主要用于结构化数据的解析,发送和接收。TServer主要任务是高效的接受客户端请求,并将请求转发给Processor处理。Processor负责对客户端的请求做出响应,包括RPC请求转发,调用参数解析和用户逻辑调用,返回值写回等处理。从TProtocol以下部分是thirft的传输协议和底层I/O通信。TProtocol是用于数据类型解析的,将结构化数据转化为字节流给TTransport进行传输。TTransport是与底层数据传输密切相关的传输层,负责以字节流方式接收和发送消息体,不关注是什么数据类型。底层IO负责实际的数据传输,包括socket、文件和压缩数据流等。
4.3.4 关于BeeLine
默认情况下,在状态Hive的机器上输入hive,进入的是Hive cli。可以输入:hive --service beeline进入beeline 终端(或者直接输入beeline)(以上,都是在设置了环境变量的情况下,如果没有设置,则需要进入$HIVE_HOME/bin)
进入beeline后,可通过!connect命令连接hiveserver2,如输入:!connect jdbc:hive2://hiveserver2_node:hiverserver2_port
该种情况下,没有选择具体的数据库,可以操作hive中的所有数据库。如果只使用某个数据库的话,可直接连接特定的数据库:!connect jdbc:hive2://hiveserver2_node:hiverserver2_port/databaseName
另外,进入beeline后,如果执行SQL没有抛错,也没有结果反馈的化,可SQL最前面或最后面加一个空格(SQL一般需要加入分号表示结束)(这个很烦,还没有找出规律,好像有的没有空格,也可以正确的反馈)
PS:个人感觉起来,Beeline用起来没有Hive cli好用呢
4.3.5 关于HCatalog
https://cwiki.apache.org/confluence/display/Hive/HCatalog+UsingHCat

HCatalog是一个Hadoop之上的表、存储管理工具。它的服务对象为:使用不同数据处理工具的用户,如Pig,MapReduce等。
作用:当使用不同工具处理数据时,用户可以更加方便的读写数据,而不用管数据具体存放在那,或是数据以什么格式的文件存储(如RCFile,Text,SequenceFiles,ORC)
HCatalog支持读写任意格式的SerDe(序列化 - 反序列化)文件。默认情况下,HCatalog支持RCFile,CSV,JSON和SequenceFile以及ORC文件格式。要使用自定义格式,您必须提供InputFormat,OutputFormat和SerDe。
HCatalog构建于Hive metastore,并包含Hive的DDL。HCatalog为Pig和MapReduce提供读写接口,并使用Hive的命令行界面发布数据定义和元数据探索命令。
(1)一般的hdfs读写
传统的对于hdfs的读写都是直接设置inputPath 和 outPath ,而且对于数据都是以文件的形式访问的,不涉及到结构化/半结构化的东东,及时如hive存储在hdfs的的结构化数据,外部系统访问也只能自己去了解具体的结构是如何存储的,然后自己读文件再访问,传统访问hdfs的方式如下:
使用InputFormat、Split、RecordReader用于读,具体方式如下:
List InputFormat.getSplits() ;
RecordReader InputFormat. createRecordReader(InputSplit split) ;
RecordReader. nextKeyValue();
RecordReader. getCurrentValue();
这样的流程来访问 。
使用OutputFormat、RecordWriter来写入hdfs数据,具体如下:
OutputFormat. getRecordWriter();
RecordWriter.write(K key, V value)
对于一般的table结构数据,都是将Key值置成NullWritable,作为一个无用的值来存储。
(2)Hcatalog与hdfs的结合:定义了文件的schema
HCatalog将每份结构化的hdfs数据定义schema和访问信息(db、table、partition),然后读和写的时候使用db、table、partition(对于无partition这个可以为空)这三部分信息来访问相应的表数据,屏蔽掉表底层InputFormat、OutFormat以及path信息,读&&写时候只许关系以下几个访问类即可:
HCatInputFormat
HCatRecordReader
HCatOutputFormat, HCatRecord>
FileRecordWriterContainer, HCatRecord>
几个类就行了,读写的接口Value均是HCatRecord对象,Key值是WritableComparable即可,不过一般key值都是NullWritable,并无实际用途 。
5.Hive配置
6.数据存储、数据文件
Hive中主要包含以下几种数据模型:Table(表),External Table(外部表),Partition(分区),Bucket(桶)
-
表:Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在 HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp 目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。
-
外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
-
分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp 表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse /dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
-
桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user /hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
Hive数据抽象结构图

6.1 关于分区与分桶
6.1.1 Hive 分区表
在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。分区表指的是在创建表时指定的partition的分区空间。
Hive可以对数据按照某列或者某些列进行分区管理,所谓分区我们可以拿下面的例子进行解释。
当前互联网应用每天都要存储大量的日志文件,几G、几十G甚至更大都是有可能。存储日志,其中必然有个属性是日志产生的日期。在产生分区时,就可以按照日志产生的日期列进行划分。把每一天的日志当作一个分区。
将数据组织成分区,主要可以提高数据的查询速度。至于用户存储的每一条记录到底放到哪个分区,由用户决定。即用户在加载数据的时候必须显示的指定该部分数据放到哪个分区。
(1) 实现细节
- 一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
- 表和列名不区分大小写。
- 分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在, 但是该字段不存放实际的数据内容,仅仅是分区的表示(伪列) 。
(2) 语法
- 创建一个分区表,以 ds 为分区列:
create table invites (id int, name string) partitioned by (ds string) row format delimited fields terminated by 't' stored as textfile;
- 将数据添加到时间为 2013-08-16 这个分区中:
load data local inpath '/home/hadoop/Desktop/data.txt' overwrite into table invites partition (ds='2013-08-16');
- 将数据添加到时间为 2013-08-20 这个分区中:
load data local inpath '/home/hadoop/Desktop/data.txt' overwrite into table invites partition (ds='2013-08-20');
- 从一个分区中查询数据:
select * from invites where ds ='2013-08-12';
- 往一个分区表的某一个分区中添加数据:
insert overwrite table invites partition (ds='2013-08-12') select id,max(name) from test group by id;
可以查看分区的具体情况,使用命令:
hadoop fs -ls /home/hadoop.hive/warehouse/invites
或者:
show partitions tablename;
6.1.2 Hive 桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
(1)把表(或者分区)组织成桶(Bucket)有两个理由:
a. 获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
b. 使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
(2)创建带桶的 table :
我们使用CLUSTERED BY 子句来指定划分桶所用的列和要划分的桶的个数:
CREATE TABLE bucketed_user (id INT) name STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;
在这里,我们使用用户ID来确定如何划分桶(Hive使用对值进行哈希并将结果除 以桶的个数取余数。这样,任何一桶里都会有一个随机的用户集合
对于map端连接的情况,两个表以相同方式划分桶。处理左边表内某个桶的 mapper知道右边表内相匹配的行在对应的桶内。因此,mapper只需要获取那个桶 (这只是右边表内存储数据的一小部分)即可进行连接。这一优化方法并不一定要求 两个表必须桶的个数相同,两个表的桶个数是倍数关系也可以。用HiveQL对两个划分了桶的表进行连接,可参见“map连接”部分。
(3)创建带桶的 table ,并对桶内数据进行排序:
桶中的数据可以根据一个或多个列另外进行排序。由于这样对每个桶的连接变成了高效的归并排序(merge-sort), 因此可以进一步提升map端连接的效率。以下语法声明一个表使其使用排序桶:
CREATE TABLE bucketed_users (id INT, name STRING)
CLUSTERED BY (id) SORTED BY (id ASC) INTO 4 BUCKETS;
我们如何保证表中的数据都划分成桶了呢?把在Hive外生成的数据加载到划分成桶的表中,当然是可以的。其实让Hive来划分桶更容易。这一操作通常针对已有的表。
Hive并不检查数据文件中的桶是否和表定义中的桶一致(无论是对于桶 的数量或用于划分桶的列)。如果两者不匹配,在査询时可能会碰到错 误或未定义的结果。因此,建议让Hive来进行划分桶的操作。
6.2 Hive元数据存储
6.3 Hive数据文件存储:存储文件格式
7.Hive执行引擎Tez与MapReduce
7.1 关于Tez
遇到的问题
HiveServer2无法启动
(1)原因一
HiveServer2无法启动,遇到的原因有两个:1是配置的Zookeeper集群没有起来,因为HiveServer2需要把自己注册到Zookeeper上,Zookeeper没有启动的化,HiveServer2出现问题。
解决办法:启动Zookeeper集群
(2)原因二:
抛错日志:
Java.net.Connection:Call From node2/XXXX to node1/XXXX failed on connection exception:java.net.ConnectionException:Conection refused;
原因:以前部署过HDFS,Hive,并将HDFS NameNode部署在node1上面,然后卸载了HDFS,Hive,重新部署,将HDFS NameNode部署在node3上面。但是Hive还是找的以前的HDFS NameNode.
解决办法:看网上之前说的是Hive数据库中CDS,SDS表的问题,后来update这连个表也没有恢复。后来搜索了一下机器上的所有配置文件,搜索node1,8020相关的问题,也没有发现hdfs,hive相关的错误配置项。然后在看Hive启动脚本时,发现Hive (HDP Hive)在启动时会检查系统是否有HBase,如果在/etc/hbase目录下有相关配置的化,会加载HBase的相关配置(由于在第一部署时,同时部署了HBASE,HBASE还保留着之前的配置,没有刷新 (配置刷新是在服务启动的时候刷的,HBASE之后没有启动过))。综上所述,Hive由于HBASE的配置问题,导致使用错误的配置启动(这里,感觉算是一个bug ,因为Hive并没有配置HBase,默认情况下,应该是将数据存储在HDFS中的,和HBASE并没有联系,但是每次启动前都会去检测/etc/hbase目录)
找到问题产生的原因,解决办法就是修改hbase的相关配置就好了
User:hcat is not allowed to impersonate ambari-qa
解决办法:在HDFS core-site中配置代理,包括:hadooop.proxyuser.XX.groups与hadooop.proxyuser.XX.host
HiveServer2正常后,Hive客户端进不去
问题:输入hive进入hive cli时,抛出连接异常,跑错日志如下:
抛错日志:
Java.net.Connection:Call From node2/XXXX to node1/XXXX failed on connection exception:java.net.ConnectionException:Conection refused;
原因:这个也是在部署HDFS,HIVE,并卸载重新部署后发生的(改变了HDFS namenode地址)。感觉问题出现的原因是:Hive将数据放在hdfs中,但是重新部署HDFS后,并没有格式化,导致HDFS中还保留有残留数据。并且Hive 的metadata中也有,不仅是CDS和SDS表,如next_lock_id,next_tnx_id表等,会记录之前的数据库操作,但是这个你的HDFS数据对不上。
解决办法:停止Hive后,删除Hive的metadata数据库然后新建,然后对HDFS 强制执行format,然后重启。重启后问题解决。(只是修改hive warehouse目录,不对hdfs格式化并一定能成功。或是只是删除hive metadata数据库也不是每次生效)