视频安防“上帝视角“的畅想
畅想
目前的视频安防手段主要还是记录不同角度的二维画面,实时(比如闯红灯抓拍)或事后分析处理。由于安防摄像头数量众多,安装角度和安装地点分散,很难对存量的巨大数量的视频录像做有效分析。目前很多安防视频平台正在利用深度学习的能力不断增强对视频解读的能力,但是效果基本就是类似去数据库里查某些字段,对普通一线的使用人员来说,这些视频分析手段存在一定的门槛,很难有一个简单的手段把大量的视频画面整合成一个整体。
说白了,目前的视频安防就像医院里拍片子,布的点再多,也不过是多个角度的二维画面,而不是一个实时活生生的3D模型,看懂仍然需要专业知识。
降低门槛的办法不是没有,那就是把信息整合成自然的方式呈现出来。
设想有这样一种叫做“上帝之眼”的魔幻雷达,它能以3D的方式还原真实的世界,就像实况足球一样,可以让人从任意角度、任意距离、任意视场角回放整个世界发生的所有细节。
这听起来很像刘慈欣的小说《镜子》里的情节,每个原子都能在那个设备中被仿真出来。当然我们期望的这种魔幻雷达不是仿真世界,而是记录世界。
有了这种魔幻的雷达,我们就能以3D的方式在电脑里渲染出来世界运行的样子,以需要的任何方式去观察。比如对于一栋房子,可以去掉墙壁观察里面的所有任务的活动,就像上帝一样无视一切遮挡。

对于一个小区或者一个街道,可以像看沙盒一样看到全局的细节。
上图是一个常见的小区渲染图,但是如果这个图是实时3D的,而且和真实的世界一模一样,就可以放大看、离近看。什么区域人多,有没有人打架,都一清二楚。有了这个雷达,就不需要再去巡逻了,带个VR眼睛就能在虚拟空间中进行巡视,说不定这玩意还可以用作旅游呢。
分析
从上面的畅想中可以知道,要实现“上帝之眼”打开上帝视角,可以把需求分解为两部分,一部分是比较固定的场景,场景可以是一个街道,也可以是一栋楼的所有房间。另一部分就是变化较大的行人和汽车,今天我们只考虑行人这个元素,暂不考虑汽车。
技术分解
3D场景重建
3D场景重建是一个比较成熟的领域。
如果是室外的3D场景,可以采用无人机进行倾斜摄影,有大量成熟的商业方案可选择。


室内的3D场景重建也有很多成熟的方法,双目、激光甚至结构光。比如网上有家叫做Auto3D的公司就提供室内3D重建设备,据说已经在链家APP上用上了。


除了这些传统方法,深度学习领域有大量单目3D场景重建的努力,也取得了不错的效果,但是商业应用上还不够成熟,相信不久的将来(有可能是5年内)会有成熟的商业化方案。
有了3D场景重建,最终可以在任意角度得到的类似下面的透视图

3D行人姿态估计
浙大CAD实验室三维视觉研究组在CVPR2019上提出了一种多视角多人三维姿态估计新方法,可以在在给定标定好的多视角图像, 恢复场景中多人的三维姿态。
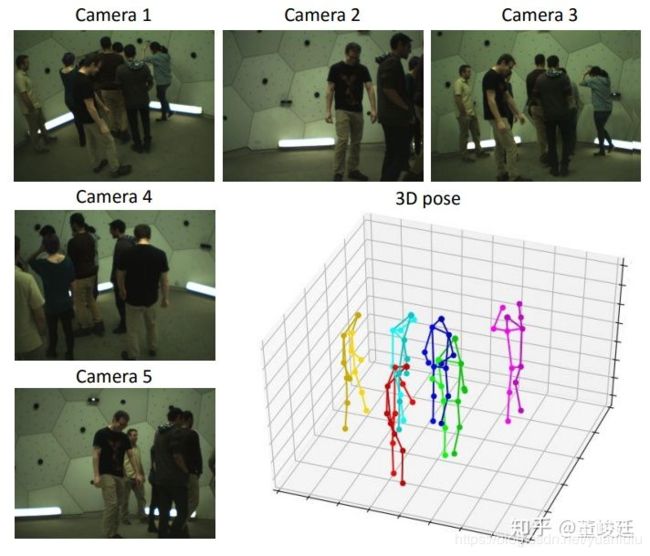
安防摄像头基本就是固定且多视角的,刚好可以利用这种技术。
3D行人渲染
旷视研究院在CVPR2019提出一种行人重识别监督之下的纹理生成网络,该模型可从单一图像中生成3D纹理。

可以把旷视和浙大CAD实验室的方案结合起来,用于生成行人的3D姿态纹理。
多目标跟踪和重识别
有了行人的3D渲染,还要结合多目标跟踪技术和行人重识别技术,减少姿态估计和渲染的计算量,并解决行人交叉、遮挡等问题。
参考资料
本文所有图片来自网络,我本人没有版权。侵立删。
姿态估计
浙大CAD实验室三维视觉研究组提出快速鲁棒的多视角多人三维姿态估计新方法,已开源
行人重识别和行人3D纹理
旷视研究院提出一种行人重识别监督之下的纹理生成网络
3D场景重建
目前有哪些做倾斜摄影比较好的公司,国内的和国外的都可以?
计算机视觉方向简介 | 深度相机室内实时稠密三维重建
Auto3D往事
单幅RGB图像整体三维场景解析与重建
基于单目视觉的三维重建算法综述