引言
AGS中可以导出每次飞行的快照数据,这些数据对于飞行品质的分析非常有帮助。目前上航每月737航班约产生9000-10000行快照信息,每行信息包含200个字段
分析字段
现阶段仅针对以下字段进行监控和分析,分别对应100英尺以下最大坡度、接地最大垂直载荷,油门慢车高度、接地姿态
event_name_landing=['`ROLL_MAX_BL100 (deg)`','`VRTG_MAX_LD (g)`','`RETARD_ALT (FT)`','`PITCH_LANDING (deg)`']
分析方法一
使用经典的mysql导出数据列表,将字段信息写入list列表,再通过对list进行统计学分析得到结果
print("机队,字段,月份,航班快照量,Q1值,中位数,Q3值,Q90,标准差,变异系数,平均值")
for column in columnlist:
for month in monthlist:
sql="select ags.ags_id,flnk.`航班日期`,ags.`From`,ags.`To`,ags.%s as 数据 from ags_snapshot ags,flight_link_chn flnk where flnk.key_id=ags.key_id and date_format(flnk.航班日期,'%%Y-%%m')='%s' and flnk.机型 IN (%s)" % (column,month,ac_type)
#print(sql)
a=query(sql)
if a.rowcount>0:
result=a.fetchall()
list=[]
for row in result:
#data=row['数据']
#数据库里是字符串,这里必须转换成浮点数
list.append(float(row['数据']))
#输出结果
print(len(list))
Q1=np.percentile(list,25)
Q2=np.percentile(list,50)
Q3=np.percentile(list,75)
#注:Q90在个人数据中没有意义,不做统计
Q90=np.percentile(list,90)
m_std=std(list,ddof=1)
m_mean=mean(list)
m_cv=std(list,ddof=1)/m_mean
#print(name,month,Q2,Q3,m_std,m_cv)
#清空list列表
list=[]
print("%s,%s,%s,%d,%f,%f,%f,%f,%f,%f,%f" % ("B737机队",column,month,len(list),Q1,Q2,Q3,Q90,m_std,m_cv,m_mean))
else:
pass
pass
分析方法二
使用pandas做为数据输入源,理论上速度更快
print("机队,字段,月份,航班快照量,Q1值,中位数,Q3值,Q90,标准差,变异系数,平均值")
for column in columnlist:
for month in monthlist:
sql="select ags.ags_id,flnk.`航班日期`,ags.`From`,ags.`To`,ags.%s as 数据 from ags_snapshot ags,flight_link_chn flnk where flnk.key_id=ags.key_id and date_format(flnk.航班日期,'%%Y-%%m')='%s' and flnk.机型 IN (%s)" % (column,month,ac_type)
df=query_df(sql)
#数据类型转换 text->float
df_float=df['数据'].astype('float')
count=df_float.count()
Q1=df_float.quantile(0.25)
Q2=df_float.quantile(0.50)
Q3=df_float.quantile(0.75)
#注:Q90在个人数据中没有意义,不做统计
Q90=df_float.quantile(0.9)
m_std=df_float.std()
#m_std=std(list,ddof=1)
m_mean=df_float.mean()
m_cv=m_std/m_mean
print("%s,%s,%s,%d,%f,%f,%f,%f,%f,%f,%f" % ("B737机队",column,month,count,Q1,Q2,Q3,Q90,m_std,m_cv,m_mean))
#print(stats1(df_float))
分析结果:
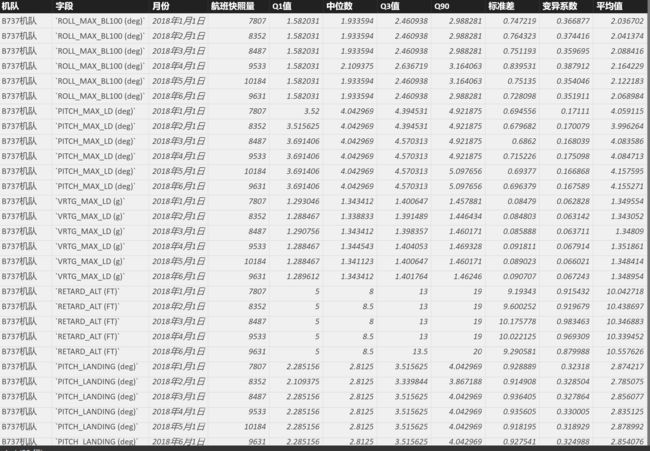
image.png