spark基础(1)
1.spark出现原因

2.spark架构:


spark分为Master节点和slave节点,ApplicationMaster资源调度,Executor执行具体的task;
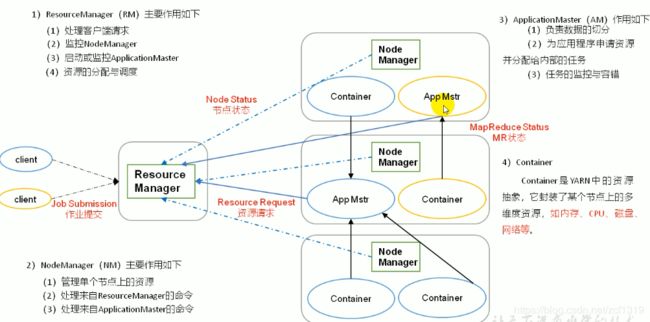
3.yarn架构

yarn由RM和NM组成,每个在yarn上运行的计算框架只需要实现AM接口,做到不同类型计算框架都可以在yarn运行;
每个运行在yarn上的任务都有一个AM;
AM做到了RM与Driver的桥梁;
具体作业任务由Driver调度;
spark只是一个计算框架,借助hdfs做数据存储,虽然spark有资源调度框架,但是跑在yarn集群上时,都是借助yarn的资源调度;
spark每个任务的driver跑在AM的container中,具体的task也跑在container中,可以做到资源隔离作用;不管是spark,还是MapReduce,都只需要实现AM接口,所有任务都跑在container中;
4、spark运行模式
4.1 Local模式
local模式是运行在一台计算机上面的模式,用于练手和测试;一般有三种格式:
local:默认一个线程;
local[K]:指定K个线程;
local[*]:适配CPU个数个线程;
4.2 独立集群模式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100--master:指定运行环境,是spark集群,还是yarn;独立集群就是spark://hadoop102:7077
4.3 yarn集群模式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100--master:指定运行环境,是spark集群,还是yarn;yarn集群就是yarn;
--deploy-mode:将驱动是发送到集群还是在本地客户端运行(提交任务的机器);
client:driver运行在提交作业的机器上(可以看到程序打印日志);
cluster:driver运行在集群上某个机器上(看不到日志,只可以看到running状态),Driver在AppMaster执行;
5.单词统计思想

- 1、一行行读取数据
- 2、对每行数据拆分成词
- 3、对单个单词转换结构为k-v键值对
- 4、对k-v键值对分组统计
scala> sc.textFile("input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res6: Array[(String, Int)] = Array((hello,2), (java,1), (spark,1))
数据流分析:
textFile("input"):读取本地文件input文件夹数据;
flatMap(_.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;
map((_,1)):对每一个元素操作,将单词映射为元组;
reduceByKey(_+_):按照key将值进行聚合,相加;
collect:将数据收集到Driver端展示。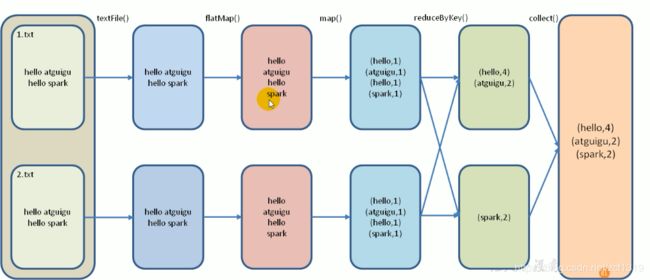
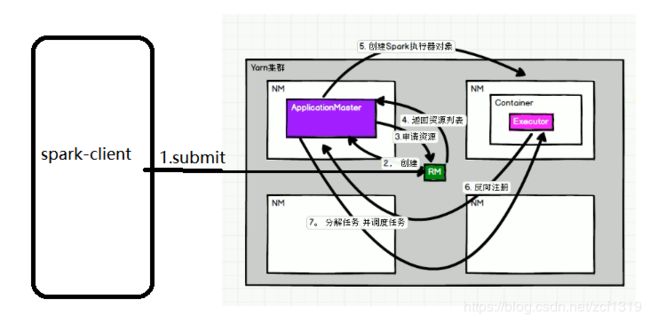
6、spark跑在yarn模式上
spark跑在yarn上时,spark客户端直接连接yarn,无需构建额外的spark集群;有spark-client,spark-cluster两种模式,其主要区别在于driver运行的位置;clinet模式可以用于调试,日志在提交的窗口显示;
spark运行在yarn上时需要启动HDFS和yarn;
Spark Yarn部署流程:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
100