大数据与Elasticsearch结合kibana可视化展示
大数据与Elasticsearch结合kibana可视化展示
安装hadoop2.7.3版本(官方推荐)(PS:hadoop3.+以上不支持,试过),hadoop可以搭全分布式和伪分布式,我是用伪分布式。
一、Hadoop伪分布式搭建:
解压Hadoop2.7.3:
1、固定ip
将集群中每一台主机ip设为静态,并且可以相互通信
先使用ifconfig查看当前网卡名称
2 设置每一台机器自己的主机名为了方便标识
sudo vim /etc/hostname
设置为Master
3 设置主机名和其ip的映射关系 DNS
sudo vi /etc/hosts
添加例如:
192.168.117.50 master
192.168.117.60 slave1
192.168.117.70 slave2
4 保证每台节点安装过ssh 服务端
5 解压安装文件
tar -zxvf /home/briup/software/hadoop-3.1.0.tar.gz -C /home/briup/software/
tar -zxvf /home/briup/software/jdk-8u201-linux-x64.tar.gz -C /home/briup/software/
6 建立软件连接,为了之后更换版本方便
ln -s hadoop-3.1.0/ hadoop
ln -s jdk1.8.0_201/ jdk
7 配置环境变量
vim ~/.bashrc
添加
export JAVA_HOME=/home/briup/software/jdk
export HADOOP_HOME=/home/briup/software/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin/:$HADOOP_HOME/sbin
8 新建目录
mkdir -p ~/software/data/hadoop/hdfs
mkdir ~/software/data/hadoop/hdfs/nn ~/software/data/hadoop/hdfs/dn ~/software/data/hadoop/hdfs/snn
mkdir -p ~/software/data/hadoop/yarn
mkdir ~/software/data/hadoop/yarn/nm ~/software/data/hadoop/yarn/logs
mkdir ~/software/hadoop/logs
sudo chmod -R 777 ~/software/hadoop/logs/
9 修改hadoop-env.sh core-site.xml hdfs-site.xml yarn-site.xml
1. hadoop-env.sh:
修改jdk地址
export JAVA_HOME=/home/hadoop/software/jdk
2. core-site.xml:
>
>
>fs.defaultFS >
>hdfs://wang:9000 >
>
>
>hadoop.tmp.dir >
>file:/home/hadoop/software/hadoop/tmp >
>
>
3. hdfs-site.xml
>
>
>dfs.nameservices >
>hadoop-cluster >
>
>
>dfs.namenode.secondary.http-address >
>wang:50090 >
>
>
>dfs.blocksize >
>32m >
>
>
>dfs.replication >
>1 >
>
>
>dfs.namenode.name.dir >
>file:/home/hadoop/software/data/hadoop/hdfs/nn >
>
>
>fs.checkpoint.dir >
>file:/home/hadoop/software/data/hadoop/hdfs/snn >
>
>
>fs.checkpoint.edits.dir >
>file:/home/hadoop/software/data/hadoop/hdfs/snn >
>
>
>dfs.datanode.data.dir >
>file:/home/hadoop/software/data/hadoop/hdfs/dn >
>
>
>dfs.permissions >
>true >
>
>
4. yarn-site.xml:
>
<!-- Site specific YARN configuration properties -->
yarn.resourcemanager.hostname
wang
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.local-dirs
/home/hadoop/software/data/hadoop/yarn/nm
>
二、单机安装es和kibana
1.下载es和kibana的安装包,解压。
我的版本是elasticsearch-6.5.4和kibana-6.5.4-linux-x86_64版本
建立软链接
ln -s elasticsearch-6.5.4 elasticsearch
ln -s kibana-6.5.4-linux-x86_64 kibana
2.es修改配置文件 ./elasticsearch/config
Vim elasticsearch.yml
修改两项,添加路径,文件夹需要提前建立
path.data: /home/hadoop/software/elasticsearch/data
path.logs: /home/hadoop/software/elasticsearch/logs
其他不需要改不然运行很容易报错,network.host不要改,单机配置你的机器性能不够就会报错。就是默认localhost。
3.kibana修改配置 ./kibana/config
Vim kibana.yml
修改server.host,添加自己的ip地址
例如:
server.host: “192.168.75.129”
4.开启es和kibana
先开启es,移动到./elasticsearch下
./bin/elasticsearch
./bin/elasticsearch -d(后台运行,建议用这个)
等待一会查看localhost:9200端口界面

有着界面说明开启成功。
再开启kibana,移动到./kibana
./bin/kibana
查看ip:5601
有页面查看就开启kibana了
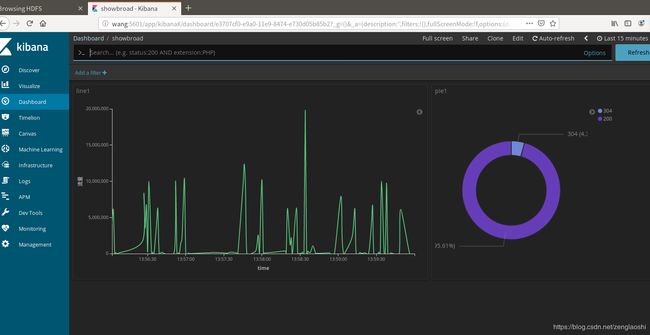
三、利用spark写数据传到es中,kibana视图显示
安装spark和scala安装包。我的版本是spark-2.4.3和scala-2.11.8
解压安装就能用
因为是单机模式
用IDEA新建Spark项目
Pom引入
org.elasticsearch</groupId>
elasticsearch-hadoop</artifactId>
6.5.4</version>
</dependency>
按照你elasticsearch版本设置
Logger.getLogger("org").setLevel(Level.WARN)
valconf=newSparkConf().setAppName("spark_to_es").setMaster("local[*]")
conf.set("es.index.auto.create","true")
conf.set("es.nodes","localhost")
conf.set("es.port","9200")
设置spark
Spark rdd插入es
Rdd.saveToEs(“index/ree”)
(PS:index是指索引,ree是指分片)
Rdd的形式只能是Seq形式不然es不识别,
Seq(Map(key,value)…)形式,最好是用Seq(Map)形式,其他不太好用,官方也是Seq(Map)形式。
Spark DataSet/DataFrame形式插入es
以样例类形式插入(官方)
Case class People(name:String,age:Int)
官方还是对rdd进行操作转化为DataSet/DataFrame。
最后打包到虚拟机运行
Spark-submit –-class com.nanyang.core.Core1 Spark1-1.0-SNAPSHOT-jar-with-dependencies.jar
运行就行了,在kibana界面可以看到数据是否进来在kibana中左侧management中
Index management中查看是否有你建立的引索。

这样就表示有数据进入es了。最后可以对数据做可视化展示。