大话西游之王道考研数据结构第六讲---二叉树的遍历和线索化二叉树
第六讲--二叉树的遍历和线索化二叉树
复习:
1.树中结点个数和度数的关系?
2.二叉树中,度为0的结点个数![]() 和度为2的结点个数
和度为2的结点个数![]() 之间的关系?
之间的关系?
3.编号为i的结点,父亲结点编号是多少,左孩子和右孩子分别是多少?
4.满二叉树第k层上,最左面那个结点的编号是多少?最右面那个结点编号是多少?
一、二叉树的遍历的方式

所谓二叉树的遍历,是指按某条搜索路径访问树中的每个结点,使得每个结点均被访问一次,而且仅被访问一次。
比如,我们想知道世上有哪些神仙,最大的是如来,其次可以分为天上一派(最大太上老君),地下一派(最大阎王爷),我们只需要把如来,天上那一派,地下那一派都输出了,就知道有哪些神仙了。
而天上那一派里面,又大致分两派,我们只需要把玉皇大帝 和那两派都输出了,天上那一派就知道有些谁了。
地上也是如此。
很明显,这是一个递归的形式,但是到底先输出天上那一派呢,还是如来,还是地下那一派呢?
因此。我们有三种不同的输出方式~(先不考虑层序)。
我们要想输出上述的二叉树,容易想到是的采用递归的形式,我们可以:
1.输出当前结点N,2.输出当前结点的左结点L,3.输出当前节点的右结点R
对于每一个结点都这样做,当然如果没有左结点或者右结点我们就不输出了。
可以看到,我们其实可以对1,2,3随意的排序(前提是先输出L,然后输出R,所以也就是什么时候输出N的问题了)。这样的输出结果一般是不同的。不同的排序方式代表着不同的遍历方式,可以有:NLR(N在最前面,也就是1->2->3),LNR(N在中间,也就是2->1->3),LRN(N在最后面,也就是2->3->1)。
当然,我们还有层序遍历,这就有点类似图中的广度优先搜索了。按照层的有小到大,每一层从左到右输出。
(这次内容比较严肃,我就不讲西游记了~)
二、二叉树遍历构建
1.老规矩,我们先简绍一下结构体
typedef struct BiTNode
{
char data; //用来存放内容
struct BiTNode *l_child,*r_child; //左孩子,右孩子
}*BiTree;2.CreatBitree(&T),这里采用的是先序遍历的顺序,以递归的方式进行创建
void CreatBitree(BiTree &T)
{
//我们创建的时候,采用的是先序遍历的顺序进行创建
char data;
scanf("%c",&data);
if(data == '#') //这个标记表示当前结点为空
//也就是假如某个结点A的左孩子是空的话,在下面先创建A,然后需要CreatBitree(T->l_child)去创建左孩子
//然后进入到这里,输入的内容是#,它就直接把A的左孩子置为NULL了
T = NULL;
else
{
T = (struct BiTNode *)malloc(sizeof(struct BiTNode)); //1.N
T->data = data;
CreatBitree(T->l_child); //左孩子为空,调用函数自动返回其父 2.L
CreatBitree(T->r_child);//接着访问右孩子 3.R
}
}3.PreOrder(T):先序遍历
void PreOrder(BiTree T)
{
//先序遍历
if(T)
{
printf("%c",T->data); //1.N
PreOrder(T->l_child); //2.L
PreOrder(T->r_child); //3.R
}
} 4.InOrder(T):中序遍历
void InOrder(BiTree T)
{
//中序遍历
if(T)
{
InOrder(T->l_child); //2.L
printf("%c",T->data); //1.N
InOrder(T->r_child); //3.R
}
}5.PostOrder(T):后序遍历
void PostOrder(BiTree T)
{
//后续遍历
if(T)
{
PostOrder(T->l_child); //2.L
PostOrder(T->r_child); //3.R
printf("%c",T->data); //1.N
}
}7.LevelBiTree(T):层序遍历
void LevelBiTree(BiTree &T)
{
queue t; //创建一个队列
t.push(T); //先把头结点入队
while(!t.empty()) //如果队列不为空的话
{
if(t.front()->l_child!=NULL) //左结点入队
t.push(t.front()->l_child);
if(t.front()->r_child!=NULL) //右结点入队
t.push(t.front()->r_child);
printf("%d",t.front()->data); //输出N
t.pop(); //出队
}
} 接下来我们可以算一下,不同遍历方式下,最开始那个图中的输出结果:

我们得先把图转化为第一行的ABD##EF#H##G##C##,这个转化需要我们自己做一遍先序遍历,遇到子树为空的置为#。
这个东西一定要会遍历,没有什么捷径,多做几个题~
二、由遍历序列构造二叉树
这一般是传统的ACM(大学生程序设计竞赛)里面二叉树的考题,如果感兴趣的话可以搜一下杭电1710这道题,试着做一下,题目要求给出二叉树的中序和前序,让你求后序。我之前做过一个最后让求层序镜像~稍微难一点点
任意给出一个序列(先序,后续,层序),加上中序,我们就可以把这颗树画出来了(理由不会考,记住就行)。首先,我们得认识到不同遍历结果反映的一些问题(拿上面的输出来讲)。
我们的先确定哪个是根,以及根的左子树有哪些,右子树有哪些。
1.确定根:通过前序或者后续确定
前序遍历:采用的是NLR,那么第一个元素肯定是根。上面第一个是A
后续遍历:采用的是LRN,那么肯定最后一个元素就是根了。上面最后一个是A
2.确定根的左子树和右子树有哪些:通过中序遍历确定
中序遍历:采用的是LNR,也就是如果我们知道谁是根节点的话,在中序遍历中,找到这个结点,其左边肯定是根结点的左子树了(DBFHEG),右边是右子树(C)。
3.我们把中序遍历确定的左子树(DBFHEG)摘出来,也在前序/后序中把这一部分摘出来。
在前序中,我们摘出来的结果是(BDEFHG),(中序划分出的那些内容,其在前序中肯定是连续的,不要打乱顺序摘出来)
在后续中,我们摘出来的结果是(DHFGEB),(中序划分出的那些内容,其在后序中肯定是连续的,不要打乱顺序摘出来)
摘出来以后,当做一个二叉树,重复执行1,2,3.
同理,我们可以把右子树做一样的操作。
三、线索化二叉树
1.不管是那一种遍历,某个结点的在输出序列中的前驱结点和后继结点是非常难求出来的。
2.我们发现在n个结点的二叉树里面,有n+1个空结点。
(空结点都是人造的,生了0个孩子的人有俩空结点,生了1个孩子的有1个,生了俩的没有,所以空结点个数为![]() ,而我们之前有一个重要的公式为:
,而我们之前有一个重要的公式为: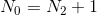 ,替换一个
,替换一个![]() ,有;
,有;![]() )
)
3.我们是否可以利用这n+1个空结点, 把结点的前驱和后继存起来,这样找前驱和后继会很方便。
引入线索化二叉树的目的就是为了加快查找结点的前驱和后继
线索化二叉树时候,我们作这样的规定:如果一个结点没有左孩子时候,我们就让左孩子指向其前驱结点;如果一个结点没有右孩子时候,我们就让右孩子指向其后继结点。
BUT!,这么做完以后,你咋知道这个左孩子到底是真的左孩子还是前驱结点呢?这样有可能把自己叔叔看成自己孩子了~
因此,我们是不是需要有一个标记,告诉我们这个左孩子到底是前驱结点(叔叔)还是左孩子(儿子)~
我们引入ltag和rtag作一个标记,当ltag = 0时候,代表左孩子指的就是左孩子,当ltag = 1的时候,代表左孩子指的是前驱结点(叔叔)。rtag和ltag一样~
所以,线索话二叉树的结构体就变为:
typedef struct BiTNode
{
char data;
int ltag,rtag;
struct BiTNode *l_child,*r_child;
}BiTNode,*BiTree;线索化二叉树对代码一般不作要求(我们学校肯定不会考这个的代码)~但是我们一定得会给一个二叉树加线索,这就得非常熟悉这个二叉树的不同遍历方式的输出是什么了,这样我们才能知道前驱和后继,才能加线索~
如果你对代码感兴趣的话,可以看看下面这个代码(这是我当初学的时候写的,有些地方看起来不太好)~
#include
#include
/*线索二叉树及对二叉树进行双向链表化*/
typedef enum {Link,Thread}PointTag; //枚举,Link表示存在l_child,Thread表示不存在
typedef struct BiTNode
{
char data;
int ltag,rtag;
struct BiTNode *l_child,*r_child;
}BiTNode,*BiTree;
BiTree pre; //前一个节点
void Visit (BiTree P)
{
printf("%c\n",P->data);
}
int CreatBiTree(BiTree &T)
{
char data;
scanf("%c",&data);
if(data == '#')
T = NULL;
else
{
T = (BiTree)malloc(sizeof(BiTNode));
T->data = data;
CreatBiTree(T->l_child);
if(T->l_child) //T节点如果有l_child,ltag标记为link
T->ltag = Link;
CreatBiTree(T->r_child);
T->rtag = Link;
}
return 0;
}
void InThreading(BiTree p) //前序遍历进行中序线索化
{
if(p)
{
printf("pre: %c\n",pre->data);
printf("p: %c\n",p->data);
if(p->ltag == Link)
InThreading(p->l_child);
printf("pre: %c\n",pre->data);
Visit(pre);
Visit(p);
if(!p->l_child) //如果P没左孩子
{
Visit(p);
p->l_child = pre;
Visit(p->l_child);
p->ltag = Thread;
}
if(!pre->r_child) //如果pre没左孩子
{
Visit(pre);
pre->r_child = p;
Visit(p);
pre->rtag = Thread;
}
pre = p;
if(p->rtag == Link)
InThreading(p->r_child);
}
}
void InOrderThreading(BiTree &H,BiTree T) //创建线索二叉树,以及头结点,对pre初始化
{
H = (BiTree)malloc(sizeof(BiTNode)); //头结点
H->r_child = H; //头节点右孩子指向自己
H->rtag = Link;
if(!T) //如果二叉树只有一片叶子,头结点左右孩子都指向自己
{
H->l_child = H;
H->ltag = Link;
}
else
{
pre = H; //上一个节点指向头结点
H->l_child = T; //当前节点为T
printf("pre: %c\n",pre->data);
H->ltag = Link;
InThreading(T); //前序遍历进行中序线索化
pre->r_child = H;
pre->rtag = Thread;
H->r_child = pre;
}
}
void InOrder(BiTree H)
{
BiTree P = H->l_child;
while(P != H)
{
Visit(P);
if(P->ltag == Link)
P = P->l_child;
else
P = P->r_child;
}
printf("\n");
}
void PreOrder(BiTree T)
{
if(T != NULL)
{
PreOrder(T->l_child);
Visit(T);
PreOrder(T->r_child);
}
}
int main()
{
BiTree T,H;
CreatBiTree(T);
printf("\n");
InOrderThreading(H,T);
InOrder(H);
return 0;
}
因为我们输出方式有前序、中序、后序。所以线索化也有前序线索二叉树、中序线索化二叉树、后序线索化二叉树。BUT,有没有看到,我们一般采用的是中序线索话,我们一般不用前序/后序线索化,因为这两个都有缺点:
前序线索化找不到前驱结点,后序线索化找不到后继结点:

就拿这个图来说,前序遍历结果是:ABDEFHGC
我们可以看到B的前驱是A,但是因为B有左孩子,所以就不能把B的左孩子置为他的前驱,所以B不能快速的找到前驱~
后序遍历结果是:DHFGEBCA,我们可以看到E的后继是B,但是E有右孩子,所以不能把E的右孩子置为他的后继,所以E不能快速的找到后继~
为什么前序线索化二叉树有些结点找不到其前驱?
因为前序输出下,一个结点X的前驱一定不是其左孩子或者右孩子(可能是父亲,也可能是长兄)(头结点除外),如果这时候,X有左孩子的话,他就找不到其前驱了
为什么前序线索化二叉结点就一定能找到后继?
因为前序输出下,输出顺序是NLR,所以一个结点X的后继一定在他的孩子里面,所以,如果其有孩子,那么后继肯定在孩子里面,如果其没有孩子,那么就会有右孩子的空链域让其指到后继。
后续线索化的局限性也是类似~