Spark RDD coalesce()方法和repartition()方法
在Spark的RDD中,RDD是分区的。
有时候需要重新设置RDD的分区数量,比如RDD的分区中,RDD分区比较多,但是每个RDD的数量比较小,需要设置一个比较合理的分区。或者需要把RDD的分区数量调大。还有就是通过设置一个RDD的分区来达到设置生成的文件的数量。
有这两种方法是可以重设RDD分区:分别是coalesce()方法和repartition()。
这两个方法有什么区别,看看源码就知道了:
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = (new Random(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}coalesce()方法的作用是返回指定一个新的指定分区的RDD
如果是生成一个窄依赖的结果,那么不会发生shuffle。比如:1000个分区被重新设置成10个分区,这样不会发生shuffle。
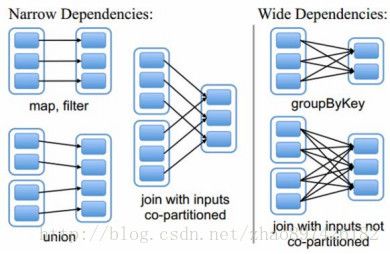
关于RDD的依赖,这里提一下。RDD的依赖分为两种:窄依赖和宽依赖
窄依赖是指父Rdd的分区最多只能被一个子Rdd的分区所引用,即一个父Rdd的分区对应一个子Rdd的分区,或者多个父Rdd的分区对应一个子Rdd的分区。
而宽依赖就是宽依赖是指子RDD的分区依赖于父RDD的多个分区或所有分区,即存在一个父RDD的一个分区对应一个子RDD的多个分区。1个父RDD分区对应多个子RDD分区,这其中又分两种情况:1个父RDD对应所有子RDD分区(未经协同划分的Join)或者1个父RDD对应非全部的多个RDD分区(如groupByKey)。
如下图所示:map就是一种窄依赖,而join则会导致宽依赖
回到刚才的分区,如果分区的数量发生激烈的变化,如设置numPartitions=1,这可能会造成运行计算的节点比你想象的要少,为了避免这个情况,可以设置shuffle=true,从而提高并行度,但这会增加shuffle操作。
关于这个分区的激烈的变化情况,比如分区数量从父RDD的几千个分区设置成几个,有可能会遇到这么一个错误。
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 77.0 failed 4 times, most recent failure: Lost task 1.3 in stage 77.0 (TID 6334, 192.168.8.61): java.io.IOException: Unable to acquire 16777216 bytes of memory
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.acquireNewPage(UnsafeExternalSorter.java:351)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.acquireNewPageIfNecessary(UnsafeExternalSorter.java:332)
at org.apache.spark.util.collection.unsafe.sort.UnsafeExternalSorter.insertKVRecord(UnsafeExternalSorter.java:461)
at org.apache.spark.sql.execution.UnsafeKVExternalSorter.insertKV(UnsafeKVExternalSorter.java:139)
at org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator.switchToSortBasedAggregation(TungstenAggregationIterator.scala:489)
at org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator.processInputs(TungstenAggregationIterator.scala:379)
at org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator.start(TungstenAggregationIterator.scala:622)
at org.apache.spark.sql.execution.aggregate.TungstenAggregate$$anonfun$doExecute$1.org$apache$spark$sql$execution$aggregate$TungstenAggregate
anonfun
executePartition$1(TungstenAggregate.scala:110)
at org.apache.spark.sql.execution.aggregate.TungstenAggregate$$anonfun$doExecute$1$$anonfun$2.apply(TungstenAggregate.scala:119)
at org.apache.spark.sql.execution.aggregate.TungstenAggregate$$anonfun$doExecute$1$$anonfun$2.apply(TungstenAggregate.scala:119)
at org.apache.spark.rdd.MapPartitionsWithPreparationRDD.compute(MapPartitionsWithPreparationRDD.scala:64)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsWithPreparationRDD.compute(MapPartitionsWithPreparationRDD.scala:63)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsWithPreparationRDD.compute(MapPartitionsWithPreparationRDD.scala:63)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.ZippedPartitionsRDD2.compute(ZippedPartitionsRDD.scala:99)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.UnionRDD.compute(UnionRDD.scala:87)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:300)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:264)
at org.apache.spark.rdd.CoalescedRDD$$anonfun$compute$1.apply(CoalescedRDD.scala:96)
at org.apache.spark.rdd.CoalescedRDD$$anonfun$compute$1.apply(CoalescedRDD.scala:95)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:371)
at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:209)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:88)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744) 这个错误只要把shuffle设置成true即可解决。
当把父RDD的分区数量增大是,比如RDD的分区是100,设置成1000,如果shuffle为false,那就不会起作用。这时候就需要设置shuffle为true了,那么RDD将在shuffle之后返回一个1000个分区的RDD,数据分区方式默认是采用hashpartitioner。
最后来看看repartition()方法的源码:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}从源码可以看出,repartition()方法就是coalesce()方法shuffle为true的情况。