前端面试--JavaScript深入理解
文章目录
- 深入之原型到原型链
- prototype
- `__proto__`
- constructor
- 原型的原型
- 原型链
- 深入之词法作用域和动态作用域
- 静态作用域与动态作用域
- 深入之执行上下文栈
- 顺序执行???
- 可执行代码
- 执行上下文栈
- 深入之变量对象
博客笔记: 直达.
深入之原型到原型链
prototype
每个函数都有一个 prototype 属性
function Person() {
}
Person.prototype.name = 'Kevin';
var person1 = new Person();
var person2 = new Person();
console.log(person1.name) // Kevin
console.log(person2.name) // Kevin
函数的 prototype 属性指向了一个对象,这个对象正是调用该构造函数而创建的实例的原型,也就是这个例子中的 person1 和 person2实例的原型。
那什么是原型呢?你可以这样理解:每一个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型"继承"属性。
__proto__
这是每一个JavaScript对象(除了 null )都具有的一个属性,叫__proto__,这个属性会指向该对象的原型。
function Person() {
}
var person = new Person();
console.log(person.__proto__ === Person.prototype); // true
constructor
既然实例对象和构造函数都可以指向原型,那么原型是否有属性指向构造函数或者实例呢?
指向实例倒是没有,因为一个构造函数可以生成多个实例,但是原型指向构造函数倒是有的,这就要讲到第三个属性:constructor,每个原型都有一个 constructor 属性指向关联的构造函数。
function Person() {
}
console.log(Person === Person.prototype.constructor); // true
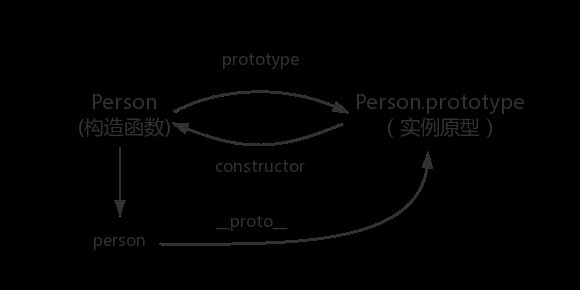
综上我们已经得出:
function Person() {
}
var person = new Person();
console.log(person.__proto__ == Person.prototype) // true
console.log(Person.prototype.constructor == Person) // true
// 顺便学习一个ES5的方法,可以获得对象的原型
console.log(Object.getPrototypeOf(person) === Person.prototype) // true
原型的原型
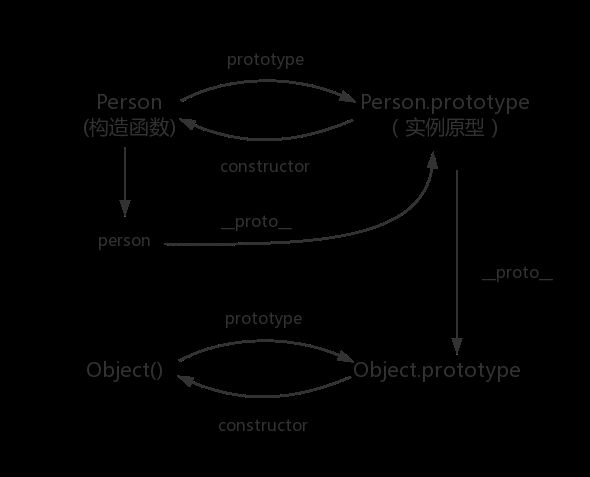
原型链
那 Object.prototype 的原型呢?
console.log(Object.prototype.__proto__ === null) // true
Object.prototype.proto 的值为 null 跟 Object.prototype 没有原型,其实表达了一个意思。
所以查找属性的时候查到 Object.prototype 就可以停止查找了。
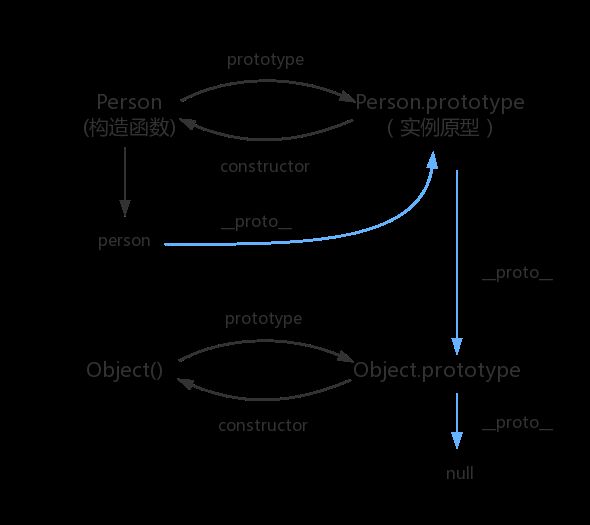
图中由相互关联的原型组成的链状结构就是原型链,也就是蓝色的这条线。
深入之词法作用域和动态作用域
静态作用域与动态作用域
因为 JavaScript 采用的是词法作用域,函数的作用域在函数定义的时候就决定了。
而与词法作用域相对的是动态作用域,函数的作用域是在函数调用的时候才决定的。
让我们认真看个例子就能明白之间的区别:
var value = 1;
function foo() {
console.log(value);
}
function bar() {
var value = 2;
foo();
}
bar(); // 结果是 ???
假设JavaScript采用静态作用域,让我们分析下执行过程:
执行 foo 函数,先从 foo 函数内部查找是否有局部变量 value,如果没有,就根据书写的位置,查找上面一层的代码,也就是 value 等于 1,所以结果会打印 1。
假设JavaScript采用动态作用域,让我们分析下执行过程:
执行 foo 函数,依然是从 foo 函数内部查找是否有局部变量 value。如果没有,就从调用函数的作用域,也就是 bar 函数内部查找 value 变量,所以结果会打印 2。
前面我们已经说了,JavaScript采用的是静态作用域,所以这个例子的结果是 1。
深入之执行上下文栈
顺序执行???
如果要问到 JavaScript 代码执行顺序的话,想必写过 JavaScript 的开发者都会有个直观的印象,那就是顺序执行,毕竟:
var foo = function () {
console.log('foo1');
}
foo(); // foo1
var foo = function () {
console.log('foo2');
}
foo(); // foo2
然而去看这段代码:
function foo() {
console.log('foo1');
}
foo(); // foo2
function foo() {
console.log('foo2');
}
foo(); // foo2
打印的结果却是两个 foo2。
刷过面试题的都知道这是因为 JavaScript 引擎并非一行一行地分析和执行程序,而是一段一段地分析执行。当执行一段代码的时候,会进行一个“准备工作”,比如第一个例子中的变量提升,和第二个例子中的函数提升。
但是本文真正想让大家思考的是:这个“一段一段”中的“段”究竟是怎么划分的呢?
到底JavaScript引擎遇到一段怎样的代码时才会做“准备工作”呢?
可执行代码
这就要说到 JavaScript 的可执行代码(executable code)的类型有哪些了?
其实很简单,就三种,全局代码、函数代码、eval代码。
举个例子,当执行到一个函数的时候,就会进行准备工作,这里的“准备工作”,让我们用个更专业一点的说法,就叫做"执行上下文(execution context)"。
执行上下文栈
接下来问题来了,我们写的函数多了去了,如何管理创建的那么多执行上下文呢?
所以 JavaScript 引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文
为了模拟执行上下文栈的行为,让我们定义执行上下文栈是一个数组:
ECStack = [];
试想当 JavaScript 开始要解释执行代码的时候,最先遇到的就是全局代码,所以初始化的时候首先就会向执行上下文栈压入一个全局执行上下文,我们用 globalContext 表示它,并且只有当整个应用程序结束的时候,ECStack 才会被清空,所以程序结束之前, ECStack 最底部永远有个 globalContext:
ECStack = [
globalContext
];
现在 JavaScript 遇到下面的这段代码了:
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();
当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。知道了这样的工作原理,让我们来看看如何处理上面这段代码:
// 伪代码
// fun1()
ECStack.push( functionContext);
// fun1中竟然调用了fun2,还要创建fun2的执行上下文
ECStack.push( functionContext);
// 擦,fun2还调用了fun3!
ECStack.push( functionContext);
// fun3执行完毕
ECStack.pop();
// fun2执行完毕
ECStack.pop();
// fun1执行完毕
ECStack.pop();
// javascript接着执行下面的代码,但是ECStack底层永远有个globalContext
深入之变量对象
变量对象的创建过程:
- 全局上下文的变量对象初始化是全局对象
- 函数上下文的变量对象初始化只包括 Arguments 对象
- 在进入执行上下文时会给变量对象添加形参、函数声明、变量声明等初始的属性值
- 在代码执行阶段,会再次修改变量对象的属性值
console.log(foo);
function foo(){
console.log("foo");
}
var foo = 1;
会打印函数,而不是 undefined 。
这是因为在进入执行上下文时,首先会处理函数声明,其次会处理变量声明,如果如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性。