安琪拉教妲己分布式限流
安琪拉教妲己分布式限流
在系统设计中,限流是保障系统高可用的一种常规手段,同样的手段还有熔断、服务降级等等,此篇文章作为一个开端,是《安琪拉教妲己分布式系统设计》的第一篇
妲己:听说最近你们系统又对接了几条业务线,而且早上9.10点钟流量非常大,你怎么保证系统不被搞挂的啊?
安琪拉:你算是问对了,最近对接了几家大机构,同时由于疫情的影响,线上渠道的流量也比平常多了很多,我这边系统做了很多系统优化,大致可以归为以下几类:
- 限流:对应用入口流量做控制,瞬时流量向后迁移,对下游请求流量做自适应限流,根据接口响应时间动态调整流量。
- 延迟排队:如果请求量大,按业务线优先级排队,例如优先保障线上渠道实时的请求,优先级提高
- 路由:其实这个是因为业务的特殊性,所有的请求都依赖下游第三方的服务,因为可以将多家下游服务供应商做个动态路由表,将请求优先路由给接口成功率高、耗时低的服务供应商;
- 备份:这基本是所有分布式组件都会做的,能做多机的不做单机,例如:Redis 做三主三备(集群)、MySQL分库分表、MQ 与 Redis 互为备份(安琪拉遇到过MQ事故)等等;
- 降级:这个是最后的逼不得已的措施,如果遇到全线崩溃,使用降级手段保障系统核心功能可用,或让模块达到最小可用。
- 日志:完整的监控和链路日志,日志功能很多,也分很多种,一方面是方便排查问题,另一方面可用来做任务重做、数据恢复、状态持久化等。
妲己:能给我讲讲限流的基础概念吗?
安琪拉:限流,顾名思义,就是限制流量,一般分为限制入口流量和限制出口流量,入口流量是人家来请求我的系统,我在入口处加了一道阀门,出口流量是我调外部系统,我在出口加一道阀门。
妲己:那一般怎么来实现限流呢?
安琪拉:如果是单机,可以通过Semphore 限制统一时间请求接口的量,也可以用 Google Guava 包提供的限流包,如果是分布式环境,可以使用 Redis 实现,也有阿里 Sentinal 或 Spring Cloud Gateway 可以实现限流。我们先来看单机版本的限流,代码如下:
//一共只有 3 个坑位
private static Semaphore semphore = new Semaphore(3);
private static String[] userName = {"妲己", "亚瑟", "鲁班", "甄姬"};
private static Random random = new Random();
//厕所类
public static class Toilet{
public void enter(User user){
try{
semphore.acquire();
if(Thread.interrupted()){
return;
}
System.out.println("时间:" + DateAndTimeUtil.getFormattedDate() + " "+user.getName() + "上厕所");
Thread.sleep(2000);
}catch (InterruptedException ex){
}finally {
semphore.release();
}
}
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Toilet toilet = new Toilet();
for(int i = 0; i < 20; i++){
executorService.submit(()->{
toilet.enter(new User(userName[random.nextInt(3)]));
});
}
}
这个代码很好理解,一共就只有三个坑位,使用 Semaphore 定义,“妲己”, “亚瑟”, “鲁班”, “甄姬” 轮番上总共二十次厕所,Semaphore 就是锁的机制,进了厕所,在门上加锁,看下控制台输出:
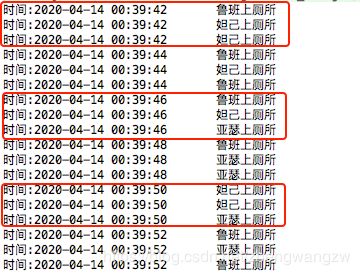
每次只有三个人能同时上厕所。
妲己:我似乎有点明白了,厕所就是资源,我们上测试就好比请求,大家一起上就产生了流量高峰,那分布式环境怎么解决呢?
安琪拉:分布式环境的思想和单机的思想是一样的,也是控制资源的访问频率,一般主流的设计思想有二种:
-
漏洞算法
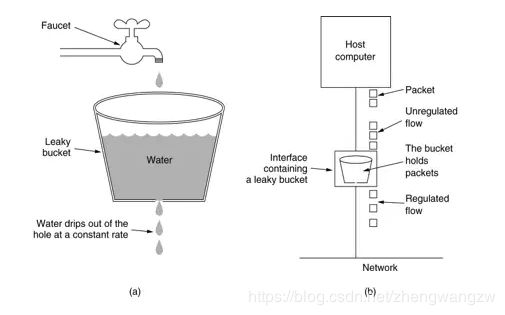
把请求比作水,在请求入口和响应请求的服务之间加一个漏桶,桶中的水以恒定的速度流出,这样保证了服务接收到的流量速度是稳定的,如果桶里的水满了,再进来的水就直接溢出(请求直接拒绝)。
漏桶是网络环境中流量整形(Traffic Shaping)或速率限制(Rate Limiting)时经常使用的一种算法,它的主要目的是控制数据进入到网络的速率,平滑网络上的突发流量。
-
令牌桶算法
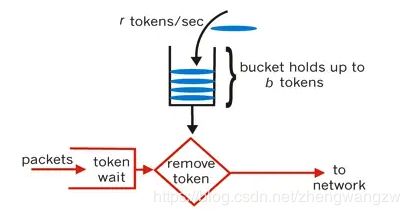
令牌桶算法有点类似于生产者消费者模式,专门有一个生产者往令牌桶中以恒定速率放入令牌,而请求处理器(消费者)在处理请求时必须先从桶中获得令牌,如果没有拿到令牌,有二种策略:一种是直接返回拒绝请求,一种是等待一段时间,再次尝试获取令牌。
令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送
Google的Guava包中的RateLimiter类就是令牌桶算法的解决方案。
对比一下这二种算法,其实无非是一个在出口处是以恒定的速率出水,一个是以恒定速率放令牌,安琪拉看来区分度不大,只是令牌桶算法更加灵活,往往实际工作中,可以实现动态调整令牌的放入速度、以及令牌桶的总大小。
妲己: 为什么我看完觉得二种算法差不多?
安琪拉:令牌桶相比漏桶有个优势,能够满足突发流量的请求。打个比方:如果线上环境资源很空闲,因为漏洞水流出的速度恒定,请求因为速度受限不会及时得到响应。比如现在漏洞出水速度是 3个/秒,现在线上来了5个请求,全部进漏桶,漏桶里面现在一共只有5个请求,但是也只能一秒处理 3 个(出水速度限制)。但是如果是令牌桶算法,放入令牌的速度是 3个/秒,假设令牌桶中已经有二个令牌了,这时来了5个请求,都能拿到令牌完成请求,因此令牌桶算法是面向请求的(请求主动拿令牌,按需分配),而漏洞则是面向令牌,我以恒定的速度出水,才不管你有多少请求。
妲己:我明白了,那你给我讲讲 Google Guava怎么实现令牌桶算法的?
安琪拉:明白了思想之后,很容易理解实现,我们来看一下源代码:
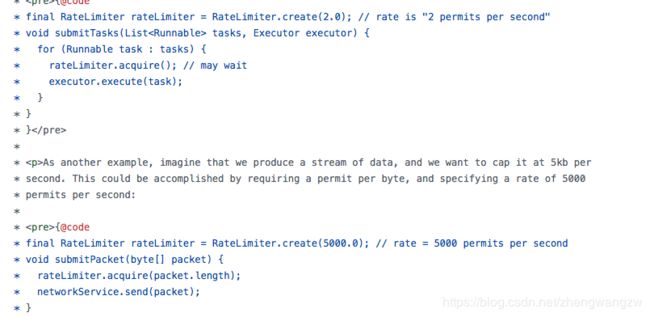
API 很简单,只需要指定限流的速度,例如第一个, 速度是每秒钟2个,如果是分钟级限流,你也可以设置为 0.2,代表1秒钟生成0.2 个令牌,1分钟限流为 12个。第二个例子是每秒钟5000,这个例子演示了如何通过限流器限制网络处理流量为每秒钟 5kb。5000个byte。
Guava 还有很多方法,如下:
| 返回值和方法修饰符 | 方法和描述 |
|---|---|
| double | acquire() 从RateLimiter获取一个许可,方法会被阻塞直到获取到请求 |
| double | acquire(int permits) 从RateLimiter获取指定许可数,方法会被阻塞直到获取到请求 |
| static RateLimiter | create(double permitsPerSecond) 根据每秒放到令牌桶数量创建RateLimiter,这里的令牌桶数量是指每秒生成令牌数(通常是指QPS,每秒多少查询) |
| static RateLimiter | create(double permitsPerSecond, long warmupPeriod, TimeUnit unit) 根据每秒放到令牌桶数量和预热期来创建RateLimiter,意思是不会一下生成全部的令牌,把令牌桶塞满,而是会渐进式的增加令牌,这里的每秒放到令牌桶数量是指每秒生成令牌数(通常是指QPS,每秒多少个请求量),在这段预热时间内,RateLimiter每秒分配的许可数会平稳地增长直到预热期结束时达到最大。 |
| double | getRate() 返回RateLimiter 配置中的稳定速率,该速率单位是每秒生成多少令牌数 |
| void | setRate(double permitsPerSecond) 更新RateLimite的稳定速率,参数permitsPerSecond 由构造RateLimiter的工厂方法提供。 |
| boolean | tryAcquire() 从RateLimiter 获取许可,如果该许可可以在无延迟下的情况下立即获取得到的话 |
| boolean | tryAcquire(int permits) 从RateLimiter 获取许可数,如果该许可数可以在无延迟下的情况下立即获取得到的话 |
| boolean | tryAcquire(int permits, long timeout, TimeUnit unit) 从RateLimiter 获取指定许可数如果该许可数可以在不超过timeout的时间内获取得到的话,或者如果无法在timeout 过期之前获取得到许可数的话,那么立即返回false (无需等待) |
妲己:那我们来看一下分布式限流吧。
安琪拉:分布式其实就是把本地令牌桶放到一个所有主机都可以访问的地方。
妲己:一般放哪里比较合适。
安琪拉:分布式中间件,例如 Redis,分布式缓存,生成令牌和获取令牌都可以用redis指令实现,而且速度还快。
妲己:那你快给我讲讲怎么实现。
安琪拉:那我说下我的实现步骤和背景吧。在令牌桶算法中,有一个单独的生产者以恒定的速率向令牌桶中放入令牌,如果通过redis实现,一个生产者线程不断往redis添加令牌(写),其他请求线程每次请求读redis获取令牌,这样会有很大的性能损耗,好的解决办法是延迟放令牌的操作,获取令牌的时候才放入令牌,将二个操作合并。
妲己:那获取令牌的时候怎么计算应该放桶中放入多少令牌呢?
安琪拉:嗯,这是个好问题,filledTokens 为这一次需要放入令牌的数量,计算逻辑为:
f i l l e d T o k e n s = m a t h . m i n ( l a s t T o k e n s + ( d e l t a ∗ r a t e ) , c a p a c i t y ) filledTokens = math.min(lastTokens+(delta*rate), capacity) filledTokens=math.min(lastTokens+(delta∗rate),capacity)
此刻应填充令牌数 = min((令牌桶剩余令牌数 + 当前时间与上一次令牌生成时间间隔 * 令牌生成速度), 令牌总容量)
根据上面的思路,写一个分布式限流的Redis脚本,redis提供lua支持,脚本如下:
--打印日志到reids
--注意,这里的打印日志级别,需要和redis server启动配置文件 redis.conf中的日志设置级别一致才行
redis.log(redis.LOG_DEBUG, "start_ratelimit")
redis.log(redis.LOG_DEBUG, KEYS[1])
redis.log(redis.LOG_DEBUG, KEYS[2])
redis.log(redis.LOG_DEBUG, ARGV[1])
redis.log(redis.LOG_DEBUG, ARGV[2])
redis.log(redis.LOG_DEBUG, ARGV[3])
redis.log(redis.LOG_DEBUG, ARGV[4])
local tokens_key = KEYS[1] -- request_rate_limiter.${id}.tokens 令牌桶剩余令牌数的KEY值
local timestamp_key = KEYS[2] -- 令牌桶最后填充令牌时间的KEY值
local rate = tonumber(ARGV[1]) -- replenishRate 令令牌桶填充平均速率 多长时间生成1个 6秒一个,秒为单位
local capacity = tonumber(ARGV[2]) -- burstCapacity 令牌桶上限
local now = tonumber(ARGV[3]) -- 得到从 1970-01-01 00:00:00 开始的秒数
local requested = tonumber(ARGV[4]) -- 消耗令牌数量,默认 1
local fill_time = capacity/rate -- 计算令牌桶填充满令牌需要多久时间 10个
redis.log(redis.LOG_DEBUG, "--fill_time--")
redis.log(redis.LOG_DEBUG, fill_time)
local ttl = math.floor(fill_time*2) -- *2 保证时间充足
redis.log(redis.LOG_DEBUG, "--fill_time--")
redis.log(redis.LOG_DEBUG, ttl)
local last_tokens = tonumber(redis.call("get", tokens_key))
-- 获得令牌桶剩余令牌数
if last_tokens == nil then -- 第一次时,没有数值,所以桶时满的
last_tokens = capacity
end
local last_refreshed = tonumber(redis.call("get", timestamp_key))
-- 令牌桶最后填充令牌时间
if last_refreshed == nil then
last_refreshed = 0
end
local delta = math.max(0, now-last_refreshed)
redis.log(redis.LOG_DEBUG, "--获取距离上一次刷新的时间间隔 delta--")
redis.log(redis.LOG_DEBUG, delta)
-- 获取距离上一次刷新的时间间隔
local filled_tokens = math.min(capacity, last_tokens+(delta*rate))
-- 填充令牌,计算新的令牌桶剩余令牌数 填充不超过令牌桶令牌上限。
redis.log(redis.LOG_DEBUG, "**填充令牌 filled_tokens**")
redis.log(redis.LOG_DEBUG, filled_tokens)
local allowed = filled_tokens >= requested
local new_tokens = filled_tokens
local allowed_num = 0
if allowed then
-- 若成功,令牌桶剩余令牌数(new_tokens) 减消耗令牌数( requested ),并设置获取成功( allowed_num = 1 ) 。
new_tokens = filled_tokens - requested
allowed_num = 1
end
-- 设置令牌桶剩余令牌数( new_tokens ) ,令牌桶最后填充令牌时间(now) ttl是超时时间
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, now)
redis.log(redis.LOG_DEBUG, "**当前拥有令牌数量 new_tokens**")
redis.log(redis.LOG_DEBUG, new_tokens)
redis.log(redis.LOG_DEBUG, "**最后更新令牌时间 now**")
redis.log(redis.LOG_DEBUG, now)
-- 返回数组结果
redis.log(redis.LOG_DEBUG, "end_ratelimit")
return { allowed_num, new_tokens }
妲己:这个写好之后怎么测试 ?
安琪拉:关注Wx 公众号:安琪拉的博客, 我教你! Redis 提供了客户端加载工具可以方便lua 脚本的调试,如下所示:
//开启调试模式 参数分别为redis剩余令牌数 key、 上次生成时间key、 生成速率、令牌桶数量、当前时间、这次获取令牌数
redis-cli --ldb --eval ratelimit.lua remain.${1}.tokens last_fill_time , 0.2 12 `gdate +%s%3N` 1
如下图所示:可以输入help 查看完整命令,常用n和print,分别为下一行和打印当前局部变量

另外也可以直接通过script load 命令加载redis lua脚本,得到sha1 之后直接运行(这个是模型真实程序运行模式,可以暂时跳过)。
// 1. 在redis服务端load 脚本 拿到sha
redis-cli script load "$(cat ratelimit.lua)"
//sha1: ebbcd2ed99990afaca6d2ba61a0f2d5bdd907e59
// 2. 通过脚本 sha1 值运行脚本
redis-cli evalsha ebbcd2ed99990afaca6d2ba61a0f2d5bdd907e59 2 remain.${0}.tokens last_fill_time 0.2 12 `gdate +%s%3N` 1

妲己:lua 脚本的执行会不会有性能上的损耗,比较redis是单线程的?
安琪拉:redis 使用 epoll 实现I/O多路复用的事件驱动模型,对于每一个读取和写入操作都尽量要快速,所以我们需要对编写的lua 脚本做个压测,redis 提供了压测指令 redis-benchmark, 测试10万 脚本的执行,命令如下:
redis-benchmark -n 100000 evalsha ebbcd2ed99990afaca6d2ba61a0f2d5bdd907e59 2 remain.${1}.tokens last_fill_time 0.2 12 `gdate +%s%3N` 1
实际效果如下:

99.9%都在 2ms以内完成,每秒钟执行4万5千多次,因此损耗可以接受。
妲己: 怎么把分布式限流lua 放到Spring boot工程中呢?
安琪拉:下面我们就开始工程化之路,
首先
-
手写一个
lua脚本(上面的脚本直接拷贝),在Spring 工程目录中放好,如下图;

-
程序启动时加载
lua脚本, 根据lua的 SHA1值判断脚本是否已经加载到redis( redis 不能存太多的script),程序如下:@Configuration public class LuaConfiguration { private Logger logger = LoggerFactory.getLogger(LuaConfiguration.class); public static final String RATE_LIMIT_SCRIPT_LOCATION = "scripts/ratelimit.lua"; @Bean(name = "rateLimitRedisScript") public DefaultRedisScript<List> redisScript(LettuceConnectionFactory lettuceConnectionFactory) { DefaultRedisScript<List> redisScript = new DefaultRedisScript<>(); redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(RATE_LIMIT_SCRIPT_LOCATION))); redisScript.setResultType(List.class); String rateLimitSha1 = redisScript.getSha1(); logger.info("分布式限流 lua 脚本 sha1 : {}", rateLimitSha1); logger.info("lua 脚本 scriptStr : {}", redisScript.getScriptAsString()); List<Boolean> luaScriptsExists = null; RedisClusterConnection clusterConnection = lettuceConnectionFactory.getClusterConnection(); //预加载脚本 if((luaScriptsExists = clusterConnection.scriptExists(redisScript.getSha1())) != null && luaScriptsExists.size() > 0){ logger.info("redis 已经存在 redis lua脚本 sha1 : {}", rateLimitSha1); }else { String scriptLuaSha1 = clusterConnection.scriptLoad(redisScript.getScriptAsString().getBytes(UTF_8)); logger.info("加载redis lua 成功 sha1 : {}", scriptLuaSha1); } return redisScript; } }这里程序启动,加载脚本,检查脚本在redis中是否存在,脚本如果没有重新编辑更新,sha1是一致的,不会重复加载,另外注意一点,如果是集群模式,Jedis 3.*版本以前不支持lua脚本,建议使用Lettuce。
关于Lettuce 和 Jedis 客户端的对比,大家可以网上看一下,Spring Boot最新默认客户端已经改成Lettuce了。
EvalSha is not supported in cluster environment
-
配置限流器
@Component public class RateLimiter implements IRateLimit{ private Logger logger = LoggerFactory.getLogger(RateLimiter.class); @Autowired RedisTemplate redisTemplate; @Autowired @Qualifier("rateLimitRedisScript") DefaultRedisScript<List> rateLimitRedisScript; private static final String REDIS_KEY_REMAIN_TOKENS = "{1}remain_tokens"; private static final String REDIS_KEY_LAST_FILL_TIME = "{1}last_fill_time"; @Override public boolean achieveDistributeToken(String keySuffix, int tokenCapacity, float tokenGenerateRate, int achiveTokenPer) { String remainTokenKey = REDIS_KEY_REMAIN_TOKENS + "_" + keySuffix; String lastFillTimeKey = REDIS_KEY_LAST_FILL_TIME + "_" + keySuffix; List<String> keys = Arrays.asList(remainTokenKey, lastFillTimeKey); String now = String.valueOf(System.currentTimeMillis()/1000); List<String> result = (List<String>) redisTemplate.execute(rateLimitRedisScript, keys, String.valueOf(tokenGenerateRate), String.valueOf(tokenCapacity), now, String.valueOf(achiveTokenPer)); if(result != null && result.size() > 0){ logger.info(" 获取分布式令牌是否成功 {} 接口 :{}, 剩余令牌数量: {}", result.get(0), "yuntrustQuery", result.get(1)); return true; } return false; } }这里有一点需要注意一下,key 都带了 {1} 的前缀,这个用于所有key 在集群模式都hash 命中同一个slot (槽),因为lua 脚本不能跨集群节点执行。
看一下效果,舒服…:
其实还有一部分内容,关于动态调整令牌桶大小和生成令牌速率的部分,鉴于文章篇幅,下次再补上。
关注Wx 公众号:安琪拉的博客