词向量——ELMo
ELMo( Embeddings from Language Models )词向量模型,2018年3月在Deep contextualized word representations(语境化的词向量)这篇论文中被提出,下面就几个方面来介绍ELMo模型。
1.产生场景(为什么产生)
word2vec、glove等词向量模型有以下缺点:
(1)没有捕捉到词性等语法信息,比如glove中
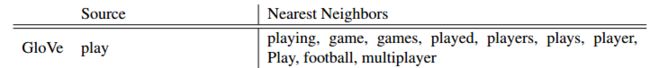
(2)每个词对应一个词向量,没有解决一词多义问题。
文章提到,以前论文提出的方法解决一词多义是通过用子词信息丰富它们或者为每个词义学习单独的向量。ELMo也通过使用字符卷积从子词单元中受益,并且在没有明确训练来预测预定义的感知词义情况下,无缝地融合多义信息进入下游任务。
2.特征
(1)ELMo是一种是基于特征的语言模型,用预训练好的语言模型,生成更好的特征。
(2)较高层的LSTM学习到了不同上下文情况下的词汇多义性(在WSD task上表现很好),而较低层捕捉了到了语法方面信息(可用作词性标注任务中)。
(3)与传统的每个token被分配一个词向量表示不同,ELMo中每一个词语的表征都是整个输入句子的函数。
(4)基于字符的,所以具有更好的鲁棒性
(5)词向量不是一成不变的,而是根据上下文而随时变化。对于一句话进入到language model获得不同的词向量。参见
3.训练
(1)语料库:a corpus with approximately 30 million sentences (Chelba et al., 2014) 【GitHub传送门】
(2)训练方法:双向LSTM在大文本语料库上用耦合语言模型(LM)目标训练。



其中:![]() 是softmax-normalized权重,标量参数
是softmax-normalized权重,标量参数![]() 允许任务模型来缩放整个ELMo向量。
允许任务模型来缩放整个ELMo向量。
(3)预训练与下游任务
ELMo词向量表示是深层的,因为它们是biLM的所有内部层的函数。 更具体地说,在预训练阶段,ELMo只需运行biLM并记录每个单词的所有层的向量表示,然后在不同下游任务中学习每个输入token上方堆叠的矢量的线性组合(学习上面的权重参数),这比仅使用顶部LSTM层有显著的性能提高。
文章中提到的Pre-trained的language model是用了两层的biLM, 对token进行上下文无关的编码是通过CNN对字符进行编码, 然后将三层的输出scale到1024维, 最后对每个token输出3个1024维的向量表示. 这里之所以将3层的输出都作为token的embedding表示是因为实验已经证实不同层的LM输出的信息对于不同的任务作用是不同的。
要将ELMo添加到监督模型,我们首先冻结biLM的权重,然后将ELMo向量ELMo task_k与xk连接为[xk; ELMotask k]进入任务RNN。 对于某些任务(例如,SNLI,SQuAD),我们通过在任务RNN的输出处添加ELMo,通过引入另一组输出特定线性权重并用[hk;ELMotask k]替换hk,来观察进一步的改进。
4.评估
把ELMo预训练的表示作为特征加入到model中,表上baseline为不加,ELMo+baseline为添加ELMo为特征,最右格给出了performance的绝对和相对提高。
文章第五部分还比较了adding position,正则化参数等的不同选择给性能提升带来的差异

评估用到的task主要是以下六种类型的NLP任务
(1)QA
dataset:The Stanford Question Answering Dataset (SQuAD),contains 100K+ crowd sourced questionanswer pairs where the answer is a span in a given Wikipedia paragraph
(2)Textual entailment(考虑到前提,假设是否属实)
dataset:The Stanford Natural Language Inference (SNLI) corpus ,provides approximately 550K hypothesis/premise pairs.
(3)Semantic role labeling(模拟句子的谓词 - 参数结构,通常被描述为回答“谁对谁做了什么”)
dataset:the OntoNotes benchmark (Pradhan et al., 2013)
(4)Coreference resolution(clustering mentions in text that refer to the same underlying real world entities)
dataset:the OntoNotes coreference annotations from the CoNLL 2012 shared task (Pradhan et al., 2012)
(5)Named entity extraction
dataset:The CoNLL 2003 NER task (Sang and Meulder, 2003),consists of newswire from the Reuters RCV1 corpus tagged
with four different entity types (PER, LOC, ORG,MISC)
(6)Sentiment analysis
dataset:Stanford Sentiment Treebank (SST-5) involves selecting one of five labels (from very negative to very positive) to describe a sentence from a movie review.
另外,为了说明此模型很好的捕捉到了词性和词义,文章给出了两个实验,分别是WSD和POS tagging,用到的dataset分别是
SemCor 3.0和Wall Street Journal portion of the Penn Treebank (PTB)

5.代码实验
主要参照GitHub上源码
pre-train:可参考
应用到downstream task中:可参考