大数据学习笔记(二)
一、HDFS
1.1 HDFS介绍
HDFS(Hadoop Distributed File System,全称为“分布式文件系统”) 是Apache Hadoop下的一个分布式文件系统项目。Hadoop底层就是使用HDFS来存储大型的数据 。HDFS 使用多台计算机存储文件,并且提供统一的访问接口。HDFS对数据文件的访问通过流的方式进行处理,这意味着通过命令和 MapReduce 程序的方式可以直接使用 HDFS。HDFS 提供了高吞吐量的访问,并且降低了对并发控制的要求,简化了数据的聚合性,而吞吐量是大数据系统的一个非常重要的指标。吞吐量越大,就意味着能处理的数据量也就越大。
- 使用HDFS的好处:
1)可以通过跨多个计算机集群存储数据来节约成本;
2)通过自动维护多个数据副本和在故障发生时来提高数据存储的可靠性;
3)它们为大数据的存储和处理提供了所需的扩展能力;
1.2 HDFS的执行流程
HDFS集群分为两大角色:NameNode、DataNode。NameNode负责整个文件系统的元数据管理。DataNode负责管理用户的数据文件。
1.2.1 HDFS文件的写入过程

当客户端向HDFS发送上传文件请求时,会通过RPC方式与NameNode建立通讯。NameNode会对上传的文件和目录进行检查(比如目录文件是否已经存在,父目录是否存在等),并将检查结果反馈给客户端程序。如果检查通过,那么客户端根据配置文件信息(如分块大小、文件副本数等),向NameNode请求上传第一个数据块。NameNode会按照配置文件中指定的备份数量,以及“机架感知”策略查询可用的DataNode地址,返回一个DataNode列表。客户端开始上传之前,会先把数据缓存在本地。当缓存大小超过了一个数据块大小的时候,客户端就会从NameNode中获取DataNode列表,然后在客户端和DataNode之间建立连接后,以流式方式一块一块地向DataNode传输数据。DataNode每接收到一块数据后,就会把接收到的数据以流水线的方式复制到其他DataNode上,并且保存在DataNode本地仓库中。当DataNode接收完数据后,会通知NameNode更新元数据信息并记录日志中。当第一个数据块发送 完成后,客户端会再次请求NameNode上传第二个数据块,直到所有数据块上传完完为止。
什么是机架感知?
Hadoop 在设计时考虑到数据的安全与高效, 数据文件默认在HDFS上存放三份副本:本地一份, 同机架内某一节点上一份, 不同机架的某一节点上一份。当从HDFS读取数据时候,HDFS会尽量让程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也会先从本地数据中心里面读取副本数据。通过机架感知策略,HDFS能够确定任意两个节点是否在同一个机架中。
1.2.2 HDFS文件的读取过程
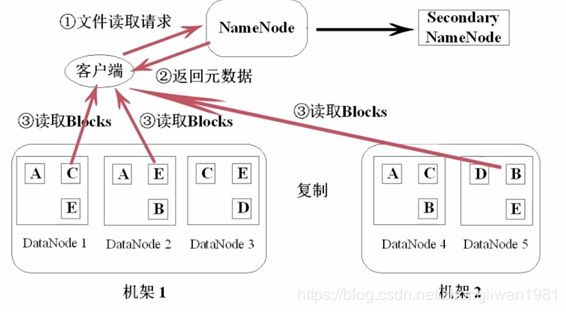
- 执行过程分析:
1)当客户端向NameNode发起RPC请求来确定请求文件block所在的位置;
2)NameNode得到该文件的block列表。对于每个block,NameNode都会返回含有该 block 副本的DataNode 地址。NameNode会按照集群拓扑结构计算出DataNode与客户端的距离,然后对block进行排序,并把排序后的block列表返回给客户端;
3)客户端选取排序靠前的DataNode来读取block。读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读;
4)当读完列表的block后,若文件读取还没有结束,客户端会继续向NameNode获取下一批的block列表;
5)当文件数据读取完成后,客户端会把最终读取来所有block合并成一个完整的最终文件;
1.3 HDFS命令
| 命令 | 功能 |
|---|---|
| hdfs dfs -ls / | 查看根路径下面的文件或者文件夹 |
| hdfs dfs -mkdir -p /xxx/xxx | 在hdfs上面递归的创建文件夹 |
| hdfs dfs -moveFromLocal sourceDir hdfsDir | 从本地磁盘上文件移动到hdfs上 |
| hdfs dfs -mv sourceHdfsDir destHdfsDir | 在hdfs上移动文件 |
| hdfs dfs -put localDir hdfsDir | 将本地文件系统的文件或者文件夹放到hdfs上面去 |
| hdfs dfs -appendToFile fileName hdfsDir | 将本地文件内容追加到hdfs文件的末尾 |
| hdfs dfs -cat hdfsDir | 查看hdfs的文件内容 |
| hdfs dfs -cp sourceHdfsDir destHdfsDir | 拷贝hdfs文件到指定文件夹下 |
| hdfs dfs -rm [-r] hdfsDir | 删除文件或者文件夹 |
| hdfs dfs -chmod -R 777 /xxx | 修改文件或目录的访问权限 |
| hdfs dfs -chown -R hadoop:hadoop /xxx | 修改文件或目录的拥有者 |
| hdfs dfs -getmerge hdfsFile localDir | 将多个文件合并后下载到本地 |
1.4 Java中操作HDFS
1.4.1 准备工作
第一步:创建一个Maven工程;
第二步:添加Maven依赖;
<repositories>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.1.1version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfs-clientartifactId>
<version>3.1.1version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.junit.jupitergroupId>
<artifactId>junit-jupiter-apiartifactId>
<version>RELEASEversion>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<minimizeJar>trueminimizeJar>
configuration>
execution>
executions>
plugin>
plugins>
build>
1.4.2 获取FileSystem对象
FileSystem代表HDFS文件系统类,该类提供了一些操作HDFS文件的方法,如上传文件、查询文件、删除文件等。
- Hadoop提供了获取FileSystem对象的四种方式:
方式一:
@Test
public void getFileSystem1() throws IOException {
// Configuration对象中存储了文件系统的配置信息
Configuration configuration = new Configuration();
// 指定使用的文件系统的类型
configuration.set("fs.defaultFS", "hdfs://node01:8020/");
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem);
}
方式二:
@Test
public void getFileSystem2() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
System.out.println(fileSystem);
}
方式三:
@Test
public void getFileSystem3() throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem));
}
方式四:
@Test
public void getFileSystem4() throws Exception{
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://node01:8020") ,new Configuration());
System.out.println(fileSystem);
}
1.4.3 遍历HDFS文件
第一步:创建FileSystem对象;
第二步:
@Test
public void testListFiles()throws Exception{
//获取fileSystem类
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
//获取RemoteIterator对象,该对象是一个迭代器,用于遍历所有文件或者文件夹
//第一个参数指定遍历的路径,第二个参数表示是否要递归遍历
RemoteIterator<LocatedFileStatus> itr = fileSystem.listFiles(new Path("/"), true);
while (itr .hasNext()){
LocatedFileStatus next = itr .next();
System.out.println(next.getPath());
}
fileSystem.close();
}
1.4.4 创建文件夹
@Test
public void mkdirs() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
boolean mkdirs = fileSystem.mkdirs(new Path("/aa/bb/cc"));
fileSystem.close();
}
1.4.5 文件上传
@Test
public void testPutData() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
fileSystem.copyFromLocalFile(new Path("file:///d:\\zhong.jpg"),new Path("/aa/bb/cc"));
fileSystem.close();
}
1.4.6 文件下载
@Test
public void testGetFileToLocal()throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
FSDataInputStream inputStream = fileSystem.open(new Path("/aa/bb/cc/zhong.jpg"));
FileOutputStream outputStream = new FileOutputStream(new File("e:\\zhong.jpg"));
IOUtils.copy(inputStream, outputStream );
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
fileSystem.close();
}