多目标跟踪:SORT和Deep SORT
https://zhuanlan.zhihu.com/p/59148865
多目标跟踪,即Multiple Object Tracking(MOT),主要任务中是给定一个图像序列,找到图像序列中运动的物体,并将不同帧的运动物体进行识别,也就是给定一个确定准确的id,当然这些物体可以是任意的,如行人、车辆、各种动物等等,而最多的研究是行人跟踪,由于人是一个非刚体的目标,且实际应用中行人检测跟踪更具有商业价值。
SORT篇(IPIL 2016)
SORT全称为Simple Online And Realtime Tracking, 对于现在的多目标跟踪,更多依赖的是其检测性能的好坏,也就是说通过改变检测器可以提高18.9%,本篇SORT算法尽管只是把普通的算法如卡尔曼滤波(Kalman Filter)和匈牙利算法(Hungarian algorithm)结合到一起,却可以匹配2016年的SOTA算法,且速度可以达到260Hz,比前者快了20倍。
论文地址:
Simple Online and Realtime Trackingarxiv.org
论文代码:
abewley/sortgithub.com
算法总览
多目标跟踪被视为数据关联问题,在视频帧序列中进行跨检测结果的关联,为了解决数据相关的问题,跟踪器使用了多种方法对运动过程和运动目标的外观特征进行建模!但作者发现这些算法并不能在精度和速度之间达到一个tade-off,如下图:
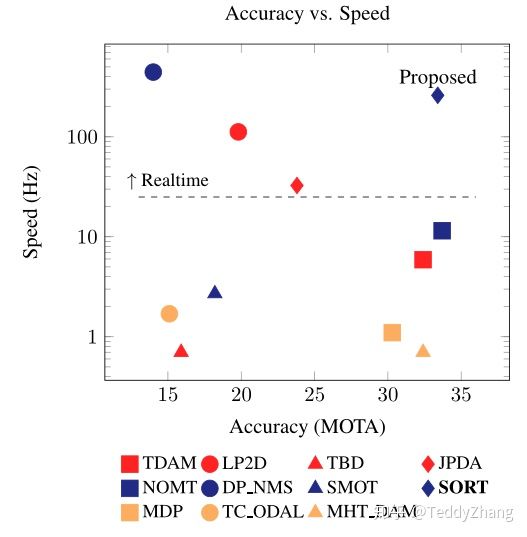
作者为了遵循Occam's Razor,作者在进行目标跟踪时没有使用任何被跟踪目标的外观特征,而仅仅使用了检测框的位置和大小进行目标的运动估计和数据关联,也没有进行任何的重识别的算法,所以当目标跟丢时,就找不回来,只能通过检测去重新更新ID,这就不符合跟踪算法的常理了,需要改进,当然这篇文章主要就是追求速度!而不是过多的关注与检测错误的鲁棒性!
实验中,作者使用了CNN-based的网络Faster RCNN和传统的行人检测ACF两个检测模型,另外,为了解决动作预测和数据关联,使用了两个十分高效的算法卡尔曼滤波和匈牙利算法。
预测模型
这里我们描述对象模型,即表示和用于将目标的标识传播到下一帧。我们近似的框架间位移都有一个线性等速模型独立于其他物体和相机运动。状态每个目标的模型如下:
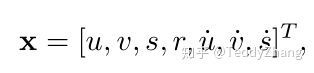
其中u和v分别代表目标的中心横纵坐标,s和r表示目标的BBox的尺寸大小和比例,注意长宽比应该为一个常量。因此后面三个量表示预测的下一帧,当检测与目标关联时,检测到的边界框用于更新目标状态,其中通过卡尔曼方法对速度分量进行了优化求解。如果没有检测与目标关联,则只需使用线性速度模型。
数据关联
作者使用匈牙利指派算法进行数据关联,使用的cost矩阵为原有目标在当前帧中的预测位置和当前帧目标检测框之间的IOU。当然小于指定IOU阈值的指派结果是无效的。作者发现使用IOU能够解决目标的短时被遮挡问题。这是因为目标被遮挡时,检测到了遮挡物,没有检测到原有目标,假设把遮挡物和原有目标进行了关联。那么在遮挡结束后,因为在相近大小的目标IOU往往较大,因此很快就可以恢复正确的关联。这是建立在遮挡物面积大于目标的基础上的
目标丢失的问题
如果连续 帧没有实现已追踪目标预测位置和检测框的IOU匹配,则认为目标消失。实验中设置 ,原因有二,一是匀速运动假设不合理,二是作者主要关注短时目标追踪。另外,尽早删除已丢失的目标有助于提升追踪效率。但是,问题就出现了,这样的话目标的ID一定会频繁的切换,这样就会造成跟踪计数的不准确!
算法总结
作者使用了Faster RCNN来进行模型的检测,并使用Kalman滤波预测状态,基于检测框位置和IOU的匈牙利算法,使得算法有很高的效率,但是这么频繁的ID切换,在实际应用中就失去了跟踪的价值了!
视频效果
YOLOV3+SORT
Deep SORT篇(ICIP2017)
论文地址:
Simple Online and Realtime Tracking with a Deep Association Metricarxiv.org
代码地址:
nwojke/deep_sortgithub.com
随着近年来目标检测领域的发展,这种tracking-by-detection方式的算法在MOT中越来越成为主流了,之前的算法如流网络公式和概率图形模型,是处理整个过程的全局优化问题,但是不适用于在线场景,其目标标识必须可用在每个时间步长。更为传统的是假设跟踪(MHT)和联合概率数据相关滤波器(JPDAF),这些方法执行基于逐帧的数据关联,最近,这些方法都被重新认识,由于检测问题的成功!
之前的SORT算法使用简单的卡尔曼滤波处理逐帧数据的关联性以及使用匈牙利算法进行关联度量,这种简单的算法在高帧速率下获得了良好的性能。但由于SORT忽略了被检测物体的表面特征,因此只有在物体状态估计不确定性较低是才会准确,在Deep SORT中,我们使用更加可靠的度量来代替关联度量,并使用CNN网络在大规模行人数据集进行训练,并提取特征,已增加网络对遗失和障碍的鲁棒性。
Track Handle and State Estimation
状态估计: 使用一个8维空间去刻画轨迹在某时刻的状态
分别表示bounding box中心的位置、纵横比、高度、以及在图像坐标中对应的速度信息。然后使用一个kalman滤波器预测更新轨迹,该卡尔曼滤波器采用匀速模型和线性观测模型。其观测变量为
轨迹处理:这个主要说轨迹什么时候终止、什么时候产生新的轨迹。首先对于每条轨迹都有一个阈值a用于记录轨迹从上一次成功匹配到当前时刻的时间。当该值大于提前设定的阈值 则认为改轨迹终止,直观上说就是长时间匹配不上的轨迹认为已经结束。然后在匹配时,对于没有匹配成功的检测都认为可能产生新的轨迹。但由于这些检测结果可能是一些错误警告,所以对这种情形新生成的轨迹标注状态'tentative' ,然后观查在接下来的连续若干帧(论文中是3帧)中是否连续匹配成功,是的话则认为是新轨迹产生,标注为'confirmed',否则则认为是假性轨迹,状态标注为'deleted'
Assignment Problem
在SORT中,我们直接使用匈牙利算法去解决预测的Kalman状态和新来的状态之间的关联度,现在我们需要将目标运动和表面特征信息相结合,通过融合这两个相似的测量指标。
Motion Metric
使用马氏距离来评测预测的Kalman状态和新来的状态:
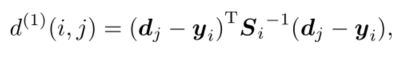
表示第j个detection和第i条轨迹之间的运动匹配度,其中 是轨迹由kalman滤波器预测得到的在当前时刻观测空间的协方差矩阵, 是轨迹在当前时刻的预测观测量, 时第j个detection的状态
考虑到运动的连续性,可以通过该马氏距离对detections进行筛选,文中使用卡方分布的0.95分位点作为阈值 =0.4877,我们可以定义一个门限函数
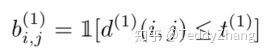
Appearance Metric
当目标运动不确定性较低时,马氏距离是一个很好的关联度量,但在实际中,如相机运动时会造成马氏距离大量不能匹配,也就会使这个度量失效,因此,我们整合第二个度量标准,对每一个BBox检测框 我们计算一个表面特征描述子 , 我们会创建一个gallery用来存放最新的 个轨迹的描述子,即 ,然后我们使用第i个轨迹和第j个轨迹的最小余弦距离作为第二个衡量尺度!
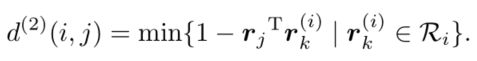
当然,我们也可以用一个门限函数来表示
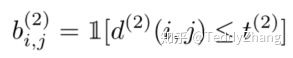
如何使用CNN网络来计算这个描述子,我们接下来会讲到!
接着,我们把这两个尺度相融合为:
![]()
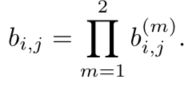
总之,距离度量对于短期的预测和匹配效果很好,而表观信息对于长时间丢失的轨迹而言,匹配度度量的比较有效。超参数的选择要看具体的数据集,比如文中说对于相机运动幅度较大的数据集,直接不考虑运动匹配程度。
匹配级联

本文还提出了一种级联匹配的策略来提高匹配精度,主要由于当一个目标被遮挡很长时间,Kalman滤波的不确定性就会大大增加,并会导致连续预测的概率弥散,假设本来协方差矩阵是一个正态分布,那么连续的预测不更新就会导致这个正态分布的方差越来越大,那么离均值欧氏距离远的点可能和之前分布中离得较近的点获得同样的马氏距离值。
上述图片描述了级联匹配的算法!!!
在最后阶段,作者使用之前SORT算法中的IOU关联去匹配n=1的unconfirmed和unmatched的轨迹。这可以缓解因为表观突变或者部分遮挡导致的较大变化。当然有好处就有坏处,这样做也有可能导致一些新产生的轨迹被连接到了一些旧的轨迹上。
Deep Appearance Descriptor
作者建立了一个深度卷积神经网络去提取目标的特征信息,并使用L2标准化吧特征投影到一个统一的超球面!模型结构为:
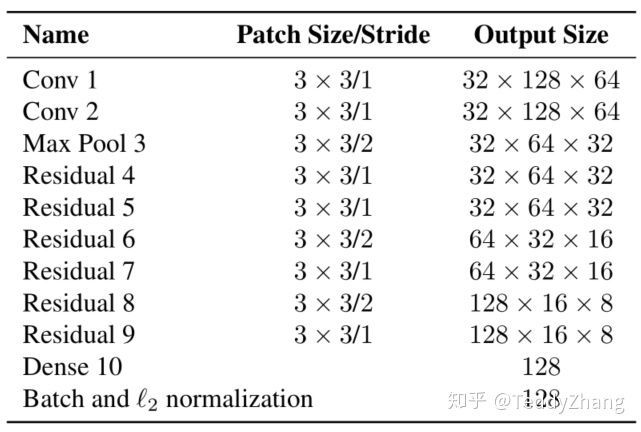
算法总结
总的来说,效果还是很明显的,使用CNN提取的特征进行匹配,大大减少了SORT中的ID switches, 经作者实验证明减少了大约45%, 在高速率视频流中也达到了很好的水准!
效果视频:
YOLOV3+Deep SORT
参考链接
【1】https://blog.csdn.net/XSYYMY/article/details/81747134
【2】ZQPei/deep_sort_pytorch