opencv3 图像检索以及基于图像描述符的搜索
本章主要介绍如何检测图像特征以及如何为描述符提取特征
特征检测算法
图像特征就是有意义的图像区域,该区域具有独特性或易于识别性。因此,角点及高密度区域是很好的特征,而大量重复的模式或低密度区域则不是好的特征。边缘可以将图像分为两个区域,因此也可以看作好的特征。斑点(与周围有很大差点别的图像区域)也是有意义的特征。
大多数特征检测算法都会涉及图像的角点,边和斑点的识别,也有涉及脊向的概念,可以认为脊向的概念,可以认为脊向是细长物体的对称轴(例如:图像识别中的一条路)
检测国际象棋角点特征:
import cv2
import numpy as np
import sys
img = cv2.imread('chess_board.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 23, 0.04)
img[dst>0.01 * dst.max()] = [0, 0, 255]
#while (True):
cv2.imshow('corners', img)
# if cv2.waitKey(int(1000 / 12)) & 0xff == ord("q"):
# break
cv2.waitKey(0)
cv2.destroyAllWindows()cornerHarris函数中最重要的参数是第三个,该参数限定了sobel算子的中孔,sobel算子通过对图像行列的变化来检测边缘,sobel算子会通过核kernel来完成检测。该参数定义了角点检测的敏感度,其取值必须介于3和31之间的奇数。如果将参数设置为3,当检测到方块的边界时,棋盘中褐色方块的所有对角线都会被认为时角点。它的第二个参数被设置可以改变标记焦点的记号大小
输出:
参数=23时:

参数=3时:

通过sift得到充满角点和特征的图像:
import cv2
import sys
import numpy as np
imgpath = 'varese.jpg'
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#创建一个sift对象
sift = cv2.xfeatures2d.SIFT_create()
keypoints, descriptor = sift.detectAndCompute(gray,None)
"""
这里的标志4穿个drawKeypoints函数,标志值4其实是下面这个cv2模块的属性值
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINT
这个代码对图像的每个关键点都绘制了圆圈和方向
"""
img = cv2.drawKeypoints(image=img, outImage=img, keypoints = keypoints, flags = 4, color = (51, 163, 236))
cv2.imshow('sift_keypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

SIFT对象会使用DoG检测关键点,并且对每个关键点周围的区域计算特征向量,由方法名称我们就可以知道,它主要包括两个操作:检测和计算,操作的返回值是关键点信息和描述符,最后在图像上绘制关键点
SURF采用快速Hessian算法检测关键点
SURF会提取特征
import cv2
import sys
import numpy as np
#imgpath = sys.argv[1]
imgpath = 'varese.jpg'
img = cv2.imread(imgpath)
#alg = sys.argv[2]
alg = 'SURF'
def fd(algorithm):
algorithms = {
"SIFT": cv2.xfeatures2d.SIFT_create(),
"SURF": cv2.xfeatures2d.SURF_create(float(sys.argv[3]) if len(sys.argv) == 4 else 8000),
"ORB": cv2.ORB_create()
}
return algorithms[algorithm]
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
fd_alg = fd(alg)
keypoints, descriptor = fd_alg.detectAndCompute(gray,None)
img = cv2.drawKeypoints(image=img, outImage=img, keypoints = keypoints, flags = 4, color = (51, 163, 236))
cv2.imshow('keypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()这幅图像是由SURF算法处理出来的,所采用的hessian阈值为8000,阈值越高,能识别的特征就越少
输出:

基于ORB的特征检测和特征匹配:
SIFT(1999年提出)是一种新算法,SURF(2006年提出)是一种更加新的算法,ORB(2011)是刚起步 用来代替前两者的,ORB是将基于FAST关键点检测技术和基于BRIEF描述符的技术相结合
下面分别介绍一下
FAST算法:
其中匹配算法用的是暴力匹配Brute-Force
import numpy as np
import cv2
from matplotlib import pyplot as plt
# query and test images
img1 = cv2.imread('manowar_logo.png',0)
img2 = cv2.imread('manowar_single.jpg',0)
# create the ORB detector
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# brute force matching
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1,des2)
# Sort by distance.
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1,kp1,img2,kp2, matches[:25], img2,flags=2)
plt.imshow(img3),
plt.show()输出:
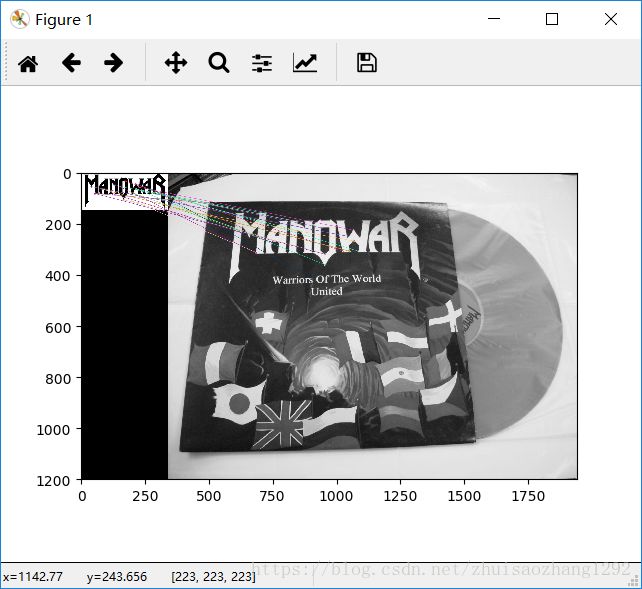
KNN匹配
与上面那个例子不同的是,这边用knn来进行匹配,
import cv2
import numpy as np
import matplotlib.pyplot as plt
p1 = cv2.imread('manowar_logo.png')
p2 = cv2.imread('manowar_single.jpg')
grayp1 = cv2.cvtColor(p1, cv2.IMREAD_GRAYSCALE)
grayp2 = cv2.cvtColor(p2, cv2.IMREAD_GRAYSCALE)
orb = cv2.ORB_create()
keyp1 ,desp1= orb.detectAndCompute(grayp1, None)
keyp2 ,desp2= orb.detectAndCompute(grayp2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
KnnMatches = bf.knnMatch(desp1, desp2, k=1)
KnnMatchImg = cv2.drawMatchesKnn(p1, keyp1, p2, keyp2, KnnMatches[:50],
p2, flags=2)
plt.figure(figsize=(15,8))
plt.imshow(KnnMatchImg)
plt.show()输出:
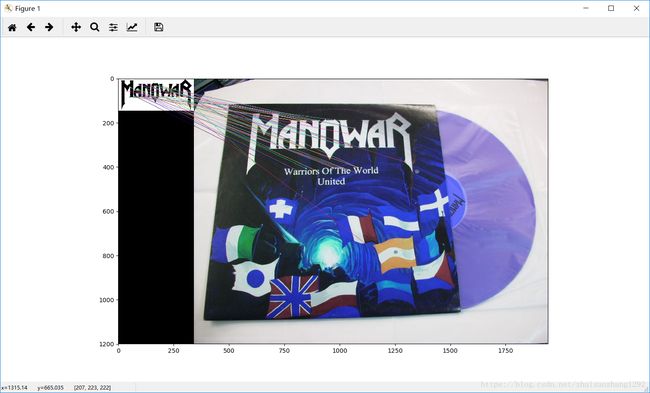
FLANN匹配
FLANN具有一种内部机制,该机制可以根据数据本身选择最合适的算法来处理数据,经验证,FLANN比其他的最近邻搜索软件快10倍。
FLANN内部可以选择LinearIndex、KTreeIndex、KMeansIndex、CompositeIndex和AutotuneIndex用来配置索引,这里选择KTreeIndex配置索引(只需指定待处理密度书的数量、最理想的数量在1~16之间),并且KtreeIndex非常灵活(kd-trees)可被并行处理,searchParams字典只包含一个字段checks,用来指定索引树要被遍历的次数,该值越高,计算匹配花费的时间就越长,但也会越准确。
实际上 匹配效果很大程度取决于输入,5 kd-trees和50 checks总能取得具有合理精度的结果,而且在很短时间内就能完成
import numpy as np
import cv2
from matplotlib import pyplot as plt
queryImage = cv2.imread('bathory_album.jpg',0)
trainingImage = cv2.imread('bathory_vinyls.jpg',0)
# create SIFT and detect/compute
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(queryImage,None)
kp2, des2 = sift.detectAndCompute(trainingImage,None)
# FLANN matcher parameters
#FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm = 0, trees = 5)
searchParams = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(indexParams,searchParams)
matches = flann.knnMatch(des1,des2,k=2)
# prepare an empty mask to draw good matches
matchesMask = [[0,0] for i in range(len(matches))]
# David G. Lowe's ratio test, populate the mask
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i]=[1,0]
drawParams = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = 0)
resultImage = cv2.drawMatchesKnn(queryImage,kp1,trainingImage,kp2,matches,None,**drawParams)
plt.imshow(resultImage,),plt.show()
输出:
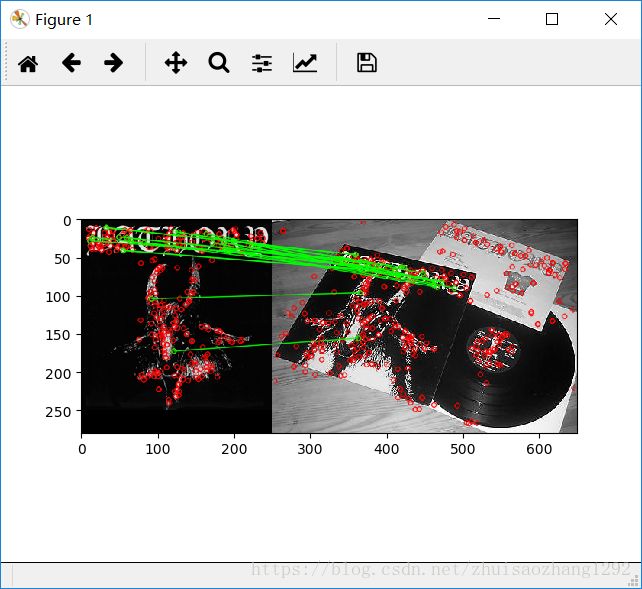
FLANN的单应性匹配:
正确识别出右侧图像,画出了关键点的匹配线段,而且还花了一个白色边框,用来展示图像seed目标在右侧发生投影畸变的效果
import numpy as np
import cv2
from matplotlib import pyplot as plt
MIN_MATCH_COUNT = 10
img1 = cv2.imread('bb.jpg',0)
img2 = cv2.imread('color2.jpg',0)
# Initiate SIFT detector
sift = cv2.xfeatures2d.SIFT_create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1,des2,k=2)
# store all the good matches as per Lowe's ratio test.
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
if len(good)>MIN_MATCH_COUNT:
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0)
matchesMask = mask.ravel().tolist()
h,w = img1.shape
pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts,M)
img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA)
else:
print ("Not enough matches are found - %d/%d" % (len(good),MIN_MATCH_COUNT))
matchesMask = None
draw_params = dict(matchColor = (0,255,0), # draw matches in green color
singlePointColor = None,
matchesMask = matchesMask, # draw only inliers
flags = 2)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params)
plt.imshow(img3, 'gray'),plt.show()输出:
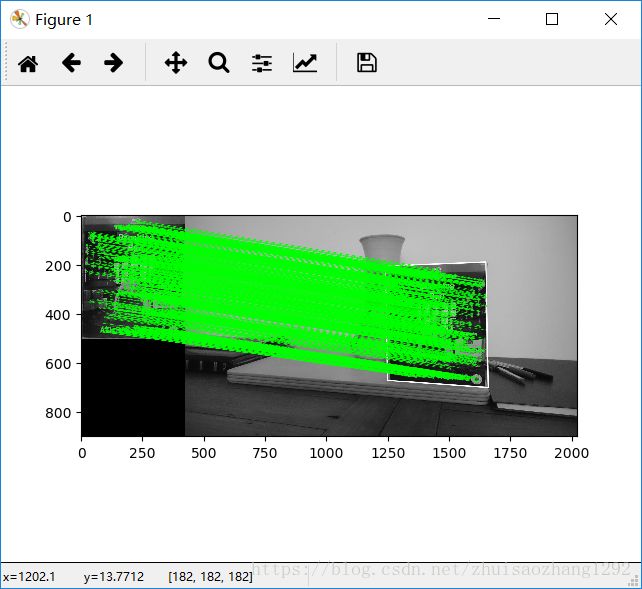
基于纹身取证的应用程序示例:
首先得将图像描述符保存到文件中,好处是,当两幅图像进行匹配和单应性分析时,不用每次都重建描述符,应用程序每次都会扫描保存图像的文件夹,并创建相应的描述符文件,可供后面搜索时使用,
文件存放:
from os.path import join
from os import walk
import numpy as np
import cv2
from sys import argv
# create an array of filenames
folder = './image'
query = cv2.imread(join(folder, "tattoo_seed.jpg"), 0)
# create files, images, descriptors globals
files = []
images = []
descriptors = []
for (dirpath, dirnames, filenames) in walk(folder):
files.extend(filenames)
for f in files:
if f.endswith("npy") and f != "tattoo_seed.npy":
descriptors.append(f)
print (descriptors)
# create the sift detector
sift = cv2.xfeatures2d.SIFT_create()
query_kp, query_ds = sift.detectAndCompute(query, None)
# create FLANN matcher
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# minimum number of matches
MIN_MATCH_COUNT = 10
potential_culprits = {}
print (">> Initiating picture scan...")
for d in descriptors:
print ("--------- analyzing %s for matches ------------" % d)
matches = flann.knnMatch(query_ds, np.load(join(folder, d)), k =2)
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
if len(good) > MIN_MATCH_COUNT:
print ("%s is a match! (%d)" % (d, len(good)))
else:
print ("%s is not a match" % d)
potential_culprits[d] = len(good)
max_matches = None
potential_suspect = None
for culprit, matches in potential_culprits.items():
if max_matches == None or matches > max_matches:
max_matches = matches
potential_suspect = culprit
print ("potential suspect is %s" % potential_suspect.replace("npy", "").upper())输出:
['bane.npy', 'dr-hurt.npy', 'hush.npy', 'penguin.npy', 'posion-ivy.npy', 'riddler.npy', 'two-face.npy']
>> Initiating picture scan...
--------- analyzing bane.npy for matches ------------
bane.npy is not a match
--------- analyzing dr-hurt.npy for matches ------------
dr-hurt.npy is a match! (298)
--------- analyzing hush.npy for matches ------------
hush.npy is a match! (301)
--------- analyzing penguin.npy for matches ------------
penguin.npy is not a match
--------- analyzing posion-ivy.npy for matches ------------
posion-ivy.npy is not a match
--------- analyzing riddler.npy for matches ------------
riddler.npy is not a match
--------- analyzing two-face.npy for matches ------------
two-face.npy is not a match
potential suspect is HUSH.