谷歌三大论文之Google MapReduce 的理解
GFS(分布式存储系统)定义:
GFS(Google File System)文件系统,一个处理大规模数据密集应用的,可伸缩的分布式文件系统。
集群是一组计算机一起工作,提供数组存储,数据处理和资源管理。
应用例子:比如腾讯的QQ需要管理数亿的用户信息,以及很多大公司经常需要处理快速增长的,并且由数亿个对象构成的数亿TB的数据集时都是采用分布式管理。
MapReduce(分布式计算系统)定义:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
顾名思义,把Map和Reduce分开,它实现的主要思想也是依赖于Map(映射)和Reduce(归约)。
Map函数是一个处理key/value键值对的数据集合的过程,Reduce函数则是一个合并的过程。
Map其实就是一个映射函数,我就把它当作JAVA中的HashMap的实现原理那样理解,因为它们都是以键值对(key and value)的形式存储和处理数据。
Reduce(归约),一开始我以为归约就是合并所有具有相同key值的value值(也就是合并重复数据的过程,但并不是去除,而是合并。)
例子:比如统计某文章的出现的单词及个数,每个单词就是一个key,对应个数是一个value。在统计的时候我们不会再一次记录重复的key值,但value会+1)。
百度对归约的解释:归约是使用解题的"黑盒"来解决另一个问题的思维方式。
假如在公司中有非常大的数据集要处理,那么用规约技术得到这些数据集的归约表示,使得数据变小了,但还大致保持原数据的特征。
其实在图形识别和视频识别中也是如此(刚好这周看人工自能高中版教程看到),对上亿的图片做处理是一个浩大的工程,就算对一张图片(一张图片由N多像素点组成)处理也够呛的了,但我们只需要提前图片的特征。所以我们可以归约处理(其实卷积计算时划分矩阵和选取每个小矩阵中的最大值或均值也可以看成是一个这样的过程)。
实现原理:
一台计算机作为客户端(Master)向多台服务端计算机(Slave)发送命令,多台服务器计算机执行该任务然后返回结果给客户端。就是一个主仆模式,也就是一种分而治之的思想。这种算法的思想之所以常见,是因为在生活中也大量存在,boss把工作分配给N个worker,每个worker获得一个任务,然后他们都做完之后都交给boss,boss只要合并一下也就搞定了。
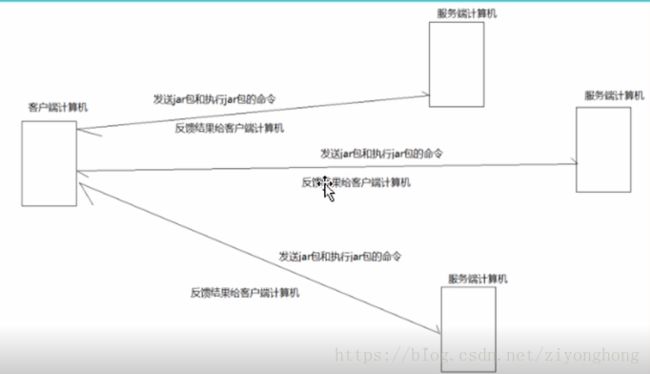
实现过程:
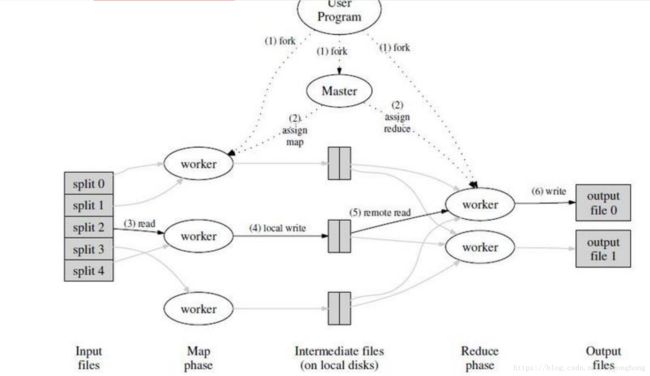
1.数据文件在加载时拆分成块(默认128MB)并进行分布,而且每个块被复制到多个数据节点中(默认3份)。
2.然后Master将任务(任务也被分成M个Map任务和R个Reduce任务)分配给空闲的worker
3.worker读取相关的输入数据片段,数据片段会被解析成键值对。然后做Map函数(用户自定义的)处理。
4.通过图中的local write过程键值对被写入到本地磁盘上。(其实键值对是通过分区函数分成R个区域,再周期性的写入到本地磁盘的。)
5.Master将数据存储位置(这个本地磁盘上的存储位置是由上一步返回的)发送给worker,worker读取数据。(这个过程还涉及到排序,因为很多不同的key值会映射到相同的Reduce任务)
6.对上一步的数据做Reduce函数(用户自定义的)处理。
实际应用:(引自百度)
如果想统计下过去10年计算机论文出现最多的几个单词,看看大家都在研究些什么,那收集好论文后,该怎么办呢?
方法一:我可以写一个小程序,把所有论文按顺序遍历一遍,统计每一个遇到的单词的出现次数,最后就可以知道哪几个单词最热门了。
这种方法实现最简单,但在数据集比较耗时。
方法二:写一个多线程程序,并发遍历论文。
这个问题理论上是可以高度并发的,因为统计一个文件时不会影响统计另一个文件。当我们的机器是多核或者多处理器,方法二肯定比方法一高效。但是写一个多线程程序要比方法一困难多了,我们必须自己同步共享数据,比如要防止两个线程重复统计文件。
方法三:把作业交给多个计算机去完成。
我们可以使用方法一的程序,部署到N台机器上去,然后把论文集分成N份,一台机器跑一个作业。这个方法跑得足够快,但是部署起来很麻烦,我们要人工把程序copy到别的机器,要人工把论文集分开,最痛苦的是还要把N个运行结果进行整合(当然我们也可以再写一个程序)。
方法四:让MapReduce来帮帮我们吧!
MapReduce本质上就是方法三,但是如何拆分文件集,如何copy程序,如何整合结果这些都是框架定义好的。我们只要定义好这个任务(用户程序),其它都交给MapReduce。
其实在电脑中的磁盘分区,阿里云等更多涉及大量数据存储和处理的地方都应用到。