MLflow:一种机器学习生命周期管理平台
编者注:文中超链接如果不能访问可以点击“阅读原文”访问本文原页面;查看 2018年9月11日至13日在纽约Strata数据会议上的“模型生命周期管理”议题 。
尽管机器学习(ML)可以产生出色的结果,在实践中使用它仍然是很复杂的。 除了软件研发中的常见挑战外,机器学习开发人员还面临着新的挑战,包括实验管理(跟踪结果是由哪些参数,代码和数据导致的); 可重复性(稍后可以在相同的运行环境中执行相同的代码); 部署模型到生产环境; 以及数据治理(审计在整个机构中使用的模型和数据。)。 围绕ML生命周期的这些关于工作流的挑战,通常是在生产环境中使用机器学习并在机构内部对其扩展的最大障碍。
为了应对这些挑战,许多公司开始构建内部机器学习平台,这些平台可以自动化执行其中的一些步骤。 在典型的机器学习平台中,专门的工程团队构建了一套数据科学家可以调用的算法和管理工具。 例如,Uber和Facebook已经建立了Michelangelo和 FBLearner Flow来管理数据准备、模型训练和部署。 然而,就算是内部平台,也有其自身的限制性:典型的机器学习平台仅支持一小组具有有限定制化的(无论工程团队构建了什么),并且平台与每个公司的基础架构是绑定的。
在2018年的Spark + AI峰会上我在Databricks的团队介绍了MLflow,这是一个新的开源项目,能够构建一个开放的机器学习平台。 除了开源之外,MLflow也是“开放的”,在某种意义上,机构中或者开源社区中的任何人,都能够为MLFlow添加新功能(比如一个新的训练算法或者一个新的部署工具),这些功能可以自动地与MLFlow的其他部分协作。MLflow通过在软件研发中对模型进行跟踪、重现、管理和部署,提供了一种强大的方式在组织机构内部去简化和线性扩展机器学习的部署。 在这篇博文中,我将简要概述MLflow所应对的挑战,以及如何入门的初阶讲解。
机器学习工作流的挑战
在Databricks,我们与数百家在生产环境中使用机器学习的公司合作。 在这些公司中,我们一再听到围绕机器学习的相同的担忧担忧:
存在无数彼此独立的工具。 从数据准备到模型训练,数百种软件工具涵盖了机器学习生命周期的每个阶段。 更有甚者,与传统的软件开发不同,团队为每个阶段选择一个工具,在机器学习中,您通常希望尝试每个可用的工具(例如,算法)来查看它是否会改善结果。 因此,机器学习开发人员需要围绕数十个库进行使用和生产环境部署。
跟踪实验很难。 机器学习算法具有几十种可配置的参数,无论您是单独工作还是在团队中工作,都很难跟踪每个实验中的何种参数、代码和数据造就了某种模型。
实验结果难以重现。 如果没有详细的跟踪,团队使用相同的代码起到同样的效果这一点上往往会遇到困难。 无论您是将训练代码交付给工程师用于生产的数据科学家,还是为了调试一个错误回滚到过去的代码进行修正,重现机器学习工作流程的步骤都至关重要。 我们听过多个恐怖故事,比如生产环境的模型表现无法像训练模型那么好,或者一个团队无法重现另一个团队的结果。
部署机器学习很困难。 由于需要运行大量的部署工具和环境(例如,REST服务,批处理推断,或移动应用程序),将模型迁移到生产环境可能会是极具挑战性的。 没有一种标准方法可以将模型从任何库迁移到任何这些工具上,从而每次进行新的部署时,都在产生新的风险。
MLflow:一个开放的机器学习平台
MLflow是这样被设计的:它旨在通过一组API和工具来解决这些工作流挑战,您可以将它们与任何现有的机器学习库和代码仓库一起使用。 在当前的alpha版本中,MLflow提供了三个主要组件:
MLflow 跟踪模块 :用于记录实验数据的API和UI,其中的数据包括参数,代码版本,评价指标,和使用过的输出文件。
MLflow 项目模块 :用于可重现性运行的一种代码封装格式。 通过将您的代码封装在MLflow项目中,您可以指定其中的依赖关系,并允许任何其他用户稍后再次运行它,并可靠地对结果进行重现。
MLflow 模型模块 :一种简单的模型封装格式,允许您将模型部署到许多工具。 例如,如果您能将模型封装为一个Python函数,MLflow模型就可以将其部署到Docker或Azure ML进行线上服务,部署到Apache Spark进行批量打分,等等。
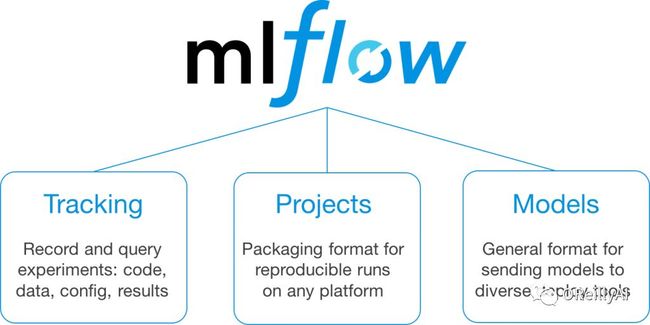
图1. MLflow组件。 图片由Matei Zaharia提供
MLflow是模块化设计的,因此您不仅可以在现有机器学习流程中单独使用这些组件,也可以将它们组合使用。 让我们依次深入研究这些组件中的每一个,看看如何使用它们,以及它们能如何简化机器学习研发。
MLflow入门
MLflow是开源的,使用pip install mlflow 能够很方便的安装。要开始使用MLflow,请按照MLflow文档中的说明进行操作,或查看GitHub上的代码。
MLflow 跟踪模块
MLflow跟踪模块是一种API和UI,它被用于在执行机器学习代码时,记录参数、代码版本、性能评估和输出文件,以便日后对其进行可视化。 通过使用简单的几行代码,您就可以跟踪参数,性能指标和“工件”(您要存储的任意输出文件):
import mlflow
# Log parameters (key-value pairs)
mlflow.log_param(“num_dimensions”, 8)
mlflow.log_param(“regularization”, 0.1)
# Log a metric; metrics can also be updated throughout the run
mlflow.log_metric(“accuracy”, model.accuracy)
# Log artifacts (output files)
mlflow.log_artifact(“roc.png”)
mlflow.log_artifact(“model.pkl”)
您可以在任何可以运行代码(例如,独立的脚本或notebook中的代码)的环境中使用MLflow跟踪模块将结果记录到本地文件或服务器,然后比较多次运行结果。 使用Web UI,您可以查看和比较多次运行的输出:

图2. MLflow跟踪UI。 图片由Matei Zaharia提供
MLflow项目模块
跟踪结果固然有用,但您也经常需要重现结果。 MLflow 项目模块为封装可重用的数据科学代码提供了一种标准格式。 每个项目可以只是一个包含代码的文件夹,也可以是Git仓库,通过使用一个描述文件来指定其依赖关系以及如何运行代码。 一个MLflow项目由一个名为MLproject的简单YAML文件来定义 。
name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: “python train.py -r {regularization} {data_file}”
validate:
parameters:
data_file: path
command: “python validate.py {data_file}”
项目可以通过Conda环境指定其依赖项。 一个项目也可以有多个入口点,用于调用含有带命名参数的运行。 您可以使用mlflow run命令行工具,从本地文件或Git仓库运行项目:
mlflow run example/project -P alpha=0.5
mlflow run [email protected]:databricks/mlflow-example.git -P alpha=0.5
MLflow会自动为项目设置正确的环境,并加以运行。 额外要提到的是,如果您在项目中使用MLflow Tracking API,MLflow将记住执行的项目版本(即Git commit)和任何参数。 然后,您可以轻松地重新运行完全相同的代码。 因此,无论是在公司内部还是在开源社区中,使用项目模块提供的格式,都可以轻松共享可重现的数据科学代码。
MLflow模型模块
MLflow的第三个组件是MLflow Models,这是一种简单但功能强大的封装模型的方法。 虽然已经存在许多模型存储格式(例如ONNX和PMML),但MLflow模型模块的目标是不同的:其目标是表示模型应该如何被调用,以便许多不同类型的下游部署工具可以使用它。 为了实现这一点,MLflow模型模块可以围绕一个模型存储被称为“风格”的多种格式。这些风格可以是特定针对某些库的(例如TensorFlow计算图),也可以是非常通用的,如“Python函数”,任何能够理解Python代码的部署工具都可以加以使用。
每个MLflow模型简单地保存为包含任意文件的目录和一个叫MLmodel 的YAML文件,这个文件列出了它可以在哪些风格里使用。这里有一个从SciKit-Learn导出的示例模型:
time_created: 2018-02-21T13:21:34.12
flavors:
sklearn:
sklearn_version: 0.19.1
pickled_model: model.pkl
python_function:
loader_module: mlflow.sklearn
pickled_model: model.pkl
MLflow提供了将许多常见模型类型部署到不同平台的工具。 例如,支持python_function 风格的任何模型,都可以部署到基于Docker的REST服务器,云服务平台(如Azure ML和AWS SageMaker),以及Spark SQL中的用户自定义函数,用于批处理和流式处理进行模型推断。 如果使用MLflow Tracking API将MLflow模型输出为工件,MLflow还将自动记住哪个项目、在哪运行它们,以便您日后进行重现。
将这些工具组合在一起
虽然MLflow的各个组件很简单,但无论您是单独使用机器学习还是在大型团队中与人协作,您都可以以强大的方式将它们组合在一起。 例如,您可以将MLflow用于:
在您的笔记本电脑上开发模型时,对代码,数据,参数和性能指标进行记录并可视化。
将代码封装为MLflow项目,以便在云环境中大规模运行它们,以进行超参数搜索。
构建一个排行榜,以比较团队内针对同一任务的不同模型的性能。
将算法,提取特征的步骤和模型共享为MLflow项目或者MLflow模型,使得组织机构中的其他用户能够把这些整合到某个工作流中。
将相同的模型部署到批处理和实时处理,而无需针对两个不同工具分别开发代码。
下一步是什么?
我们刚刚开始使用MLflow,因此还有很多其他内容即将到来。 除了对项目的更新外,我们还计划引入主要的新组件(如监控),库集成,和语言绑定。 例如,几周前,我们发布了MLflow 0.2,内置对TensorFlow的支持和其他一些新功能。
我们很期待看到您可以使用MLflow做些什么,以及我们很乐意听取您的反馈。
相关资源:
“将机器学习模型转化为真实的产品和服务时得到的经验教训”
“管理机器学习模型中的风险”:Andrew Burt和Steven Touw分享关于公司如何管理那些他们无法完全解释的模型
“什么是机器学习工程师?”:考察一种新角色,其专注于创建数据产品,并且使得数据科学的成果在生产环境中工作
“我们需要建立机器学习工具来强化机器学习工程师的能力”
当模型变得流氓时:David Talby关于在生产环境中使用机器学习得到的深刻教训
This article originally appeared in English: "MLflow: A platform for managing the machine learning lifecycle".

Matei Zaharia
Matei Zaharia是斯坦福大学计算机科学系助理教授,以及Databricks首席技术专家。 他于2009年在加州大学伯克利分校攻读博士期间,创建了Spark项目。 在此之前,Matei在数据中心系统中广泛开展工作,与他人共同启动了Apache Mesos项目,并作为Apache Hadoop的提交者做出持续的贡献。 Matei的研究在2014年获得ACM计算机科学最佳博士论文奖。