人体行为识别特征点提取 综述很全面
转自:http://www.cnblogs.com/tornadomeet/archive/2012/06/22/2558548.html
行为识别特征提取综述
摘要
人体行为识别目前处在动作识别阶段,而动作识别可以看成是特征提取和分类器设计相结合的过程。特征提取过程受到遮挡,动态背景,移动摄像头,视角和光照变化等因素的影响而具有很大的挑战性。本文将较全面的总结了目前行为识别中特征提取的方法,并将其特征划分为全局特征和局部特征,且分开介绍了其优缺点。
关键字: 行为识别 特征提取 全局特征 局部特征
1. 前言
如今人体行为识别是计算机视觉研究的一个热点,人体行为识别的目标是从一个未知的视频或者是图像序列中自动分析其中正在进行的行为。简单的行为识别即动作分类,给定一段视频,只需将其正确分类到已知的几个动作类别,复杂点的识别是视频中不仅仅只包含一个动作类别,而是有多个,系统需自动的识别出动作的类别以及动作的起始时刻。行为识别的最终目标是分析视频中哪些人在什么时刻什么地方,在干什么事情,即所谓的“W4系统”。
下面将4个方面对行为识别做初步介绍。
1.1 行为识别应用背景
人体行为识别应用背景很广泛,主要集中在智能视频监控,病人监护系统,人机交互,虚拟现实,智能家居,智能安防,运动员辅助训练,另外基于内容的视频检索和智能图像压缩等有着广阔的应用前景和潜在的经济价值和社会价值,其中也用到了不少行为识别的方法。
1.2 行为识别研究历史
行为识别分析的相关研究可以追溯到1975年Johansson[1]的一个实验,作者提出了12点人体模型,这种描述行为的点模型方法对后来基于人体结构的行为描述算法起到了重要的指导作用。从那以后,行为识别的研历史究进展大致可以分为以下3个阶段,第1个是20世纪70年代行为分析的初步研究阶段,第2个是20世纪90年代行为分析的逐步发展阶段,第3个是最近几年来行为分析的快速发展阶段。从文献[2]~[7]这6篇较有名的行为识别综述论文可以看出, 研究行为识别的人数在不断增加,论文数量也是猛增,并且产生了许多种重要的算法和思想。
1.3 行为识别方法分类体系
关于视觉上人体运动分析和识别的方法论体系有很多种。Forsyth[8]等人侧重与将动作从视频序列中人的姿态和运动信息恢复过来,这属于一个回归问题,而人体行为识别是一个分类问题,这2个问题有很多类似点,比如说其特征的提取和描述很多是通用的。Turaga[5]等人将人体行为识别分为3部分,即移动识别(movement),动作识别(action)和行为识别(activity),这3种分类分别于低层视觉,中层视觉,高层视觉相对应。Gavrila[9]采用2D和3D的方法来分别研究人体的行为。
对于行为识别方法论的划分中,最近出现了一种新的划分[7], Aggarwal将人体行为研究分为2大类,其一是基于单个层次来实现,其二是基于等级体系来实现。单层实现由分为时空特征和序列特征2种,等级体系实现分为统计方法,句法分析法和基于描述的方法3种。图1 Aggarwal对行为识别方法论体系的层次结构图。

图1 行为识别方法层次结构
该分类体系比较完善,也能很好的体现目前的研究进展。按照Turaga的3个层次划分理论,目前关于行为识别基本上还停留在第二个阶段,即action识别。而action识别比现实生活中的行为较简单,所以我们识别这些行为只需对这些行为进行正确的分类即可。这样一个行为识别系统就分成了行为特征提取和分类器的设计两个方面,通过对训练数据提取某种特征,采用有监督或无监督来训练一个分类模型,对新来的数据同样提取特征并送入该模型,得出分类结果。基于这个思想,本文主要是从行为识别的特征提取方面做了一个较为全面的介绍。
1.4 行为识别研究难点
行为识别发展至今,取得了很大的进展,在低层,中层和高层都取得了一定的突破,但是行为识别算法并不成熟,目前不存在一个算法适合所有的行为分类,3个视觉层次中都还有很多严峻的问题有待解决。其研究的难点主要体现在以下几个方面:
1.4.1 动作类内类间的变化太大
对于大多数的动作,即使是同一动作都有不同的表现形式。比如说走路,可以在不同的背景环境中完成,走路的速度也可以从慢到快,走路的步长亦有长有短。其它的动作也有类似的结果,特别是一些非周期的运动,比如过马路时候的走路,这与平时周期性的走路步伐明显不同。由此可见,动作的种类本身就很多,再加上每一种类又有很多个变种,所以给行为识别的研究带来了不少麻烦。
1.4.2 环境背景等影响
环境问背景等因素的影响可谓是计算机视觉各个领域的最大难点。主要有视角的多样性,同样的动作从不同的视角来观察会得到不同的二维图像;人与人之间,人与背景之间的相互遮挡也使计算机对动作的分类前期特征提取带来了困难,目前解决多视觉和遮挡问题,有学者提出了多摄像机融合通过3维重建来处理;另外其影响因素还包括动态变化和杂乱的背景,环境光照的变化,图像视频的低分辨率等。
1.4.3 时间变化的影响
总所周知,人体的行为离不开时间这个因素。而我们拍摄的视频其存放格式有可能不同,其播放速度有慢有快,这就导致了我们提出的系统需对视频的播放速率不敏感。
1.4.4 数据的获取和标注
既然把行为识别问题当成一个分类问题,就需要大量的数据来训练分类模型。而这些数据是视频数据,每一个动作在视频中出现的位置和时间都不确定,同时要考虑同一种动作的不同表现形式以及不同动作之间的区分度,即数据的多样性和全面性。这一收集过程的工作量不小,网上已经有一些公开的数据库供大家用来实验,这将在本文的第3部分进行介绍。
另外,手动对视频数据标注非常困难。当然,有学者也提出了一些自动标注的方法,比如说利用网页图片搜索引擎[10],利用视频的字幕[11],以及利用电影描述的文本进行匹配[12][13][14]。
1.4.5 高层视觉的理解
上面一提到,目前对行为识别的研究尚处在动作识别这一层(action recognition)。其处理的行为可以分为2类,一类是有限制类别的简单规则行为,比如说走、跑、挥手、弯腰、跳等。另一类是在具体的场景中特定的行为[15]~[19],如检测恐怖分子异常行为,丢包后突然离开等。在这种场景下对行为的描述有严格的限制,此时其描述一般采用了运动或者轨迹。这2种行为识别的研究都还不算完善,遇到了不少问题,且离高层的行为识别要求还相差很远。因此高层视觉的理解表示和识别是一个巨大的难题。
2. 行为识别特征提取
这一节中,将主要讨论怎样从图片序列中提取特征。本文将行为识别的特征分为2大类:全局特征和局部特征。
全局特征是把一对象当做成一个整体,这是一种从上到下的研究思维。这种情况下,视频中的人必须先被定位出来,这个可以采用背景减图或者目标跟踪算法。然后对定位出来的目标进行某种编码,这样就形成了其全局特征。这种全局特征是有效的,因为它包含了人体非常多的信息。然而它又太依赖而底层视觉的处理,比如说精确的背景减图,人体定位和跟踪。而这些处理过程本身也是计算机视觉中的难点之处。另外这些全局特征对噪声,视角变化,遮挡等非常敏感。
局部特征提取是收集人体的相对独立的图像块,是一种从下到上的研究思维。一般的做法是先提取视频中的一些时空兴趣点,然后在这些点的周围提取相应的图像块,最后将这些图像块组合成一起来描述一个特定的动作。局部特征的优点是其不依赖而底层的人体分割定位和跟踪,且对噪声和遮挡问题不是很敏感。但是它需要提取足够数量的稳定的且与动作类别相关的兴趣点,因此需要不少预处理过程。
2.1 全局特征提取
全局特征是对检测出来的整个感兴趣的人体进行描述,一般是通过背景减图或者跟踪的方法来得到,通常采用的是人体的边缘,剪影轮廓,光流等信息。而这些特征对噪声,部分遮挡,视角的变化比较敏感。下面分别从其二维特征和三维特征做介绍。
2.1.1 二维全局特征提取
Davis[20]等人最早采用轮廓来描述人体的运动信息,其用MEI和MHI 2个模板来保存对应的一个动作信息,然后用马氏距离分类器来进行识别。MEI为运动能量图,用来指示运动在哪些部位发生过,MHI为运动历史图,除了体现运动发生的空间位置外还体现了运动的时间先后顺序。这2种特征都是从背景减图中获取的。图2是坐下,挥手,蹲伏这3个动作的运动历史图MHI。

图2 三种动作对应的MHI
为了提前剪影信息,Wang[21]等人利用r变换获取了人体的剪影。Hsuan-Shen[22]则提取了人体的轮廓,这些轮廓信息是用星型骨架描述基线之间夹角的,这些基线是从人体的手,脚,头等中心延长到人体的轮廓。而Wang[23]同时利用了剪影信息和轮廓信息来描述动作,即用基于轮廓的平均运动形状(MMS)和基于运动前景的平均能量(AME)两个模板来进行描述。当把轮廓和剪影模板保存下来后,新提取出的特征要与其进行比较,Daniel[24]采用欧式距离来测量其相似度,随后他又改为用倒角距离来度量[25],这样就消除了背景减图这一预处理步骤。
除了利用轮廓剪影信息外,人体的运动信息也经常被采用。比如说基于像素级的背景差法,光流信息等。当背景差法不能很好的工作时,我们往往可以采用光流法,但是这样经常会引入运动噪声,Effos[26]只计算以人体中心点处的光流,这在一定程度上减少了噪声的影响。
2.1.2 三维全局特征提取
在三维空间中,通过给定视频中的数据可以得到3D时空体(STV),STV的计算需要精确的定位,目标对齐,有时还需背景减图。Blank[27][28]等人首次从视频序列中的剪影信息得到STV。如图3所示。然后用泊松方程导出局部时空显著点及其方向特征,其全局特征是通过对这些局部特征加权得到的,为了处理不同动作的持续时间不同的问题,Achard[29]对每一个视频采用了一系列的STV ,并且每个STV只是覆盖时间维上的一部分信息。
还有一种途径是从STV中提取相应的局部描述子,这一部分将在局部特征提取一节中介绍,在这里,我们还是先把STV特征当做是全局特征。Batra[30]存储了STV的剪影,并且用很小的3D二进制空间块来采样STV。Yilmaz[31]提取了STV表面的不同几何特征,比如说其极大值点和极小值点。当然,也有学者Keel[32]将剪影的STV和光流信息结合起来,作为行为识别的全局特征。

图3 跳跃,走,跑3个动作的STV图
2.2 局部特征提取
人体行为识别局部特征提取是指提取人体中感兴趣的点或者块。因此不需要精确的人体定位和跟踪,并且局部特征对人体的表观变化,视觉变化和部分遮挡问题也不是很敏感。因此在行为识别中采用这种特征的分类器比较多。下面从局部特征点检测和局部特征点描述2部分来做介绍。
2.2.1 局部特征点的检测
行为识别中的局部特征点是视频中时间和空间中的点,这些点的检测发生在视频运动的突变中。因为在运动突变时产生的点包含了对人体行为分析的大部分信息。因此当人体进行平移直线运动或者匀速运动时,这些特征点就很难被检测出来。
Laptev[33]将Harris角点扩展到3D Harris,这是时空兴趣点(STIP)族中的一个。这些时空特征点邻域的像素值在时间和空间都有显著的变化。在该算法中,邻域块的尺度大小能够自适应时间维和空间维。该时空特征点如图4所示。
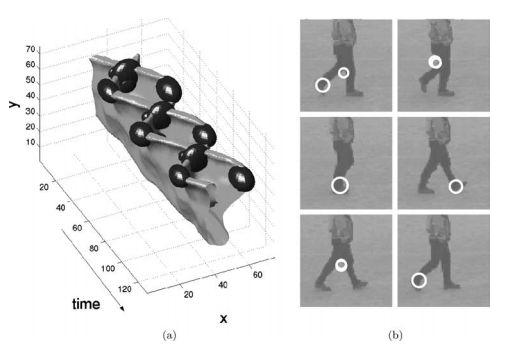
图4 时空特征点检测图
Dollar[34]指出上述那种方法存在一个缺点,即检测出来稳定的兴趣点的数量太少,因此Dollar单独的在时间维和空间维先采用gabor滤波器进行滤波,这样的话检测出来兴趣点的数目就会随着时间和空间的局部邻域尺寸的改变而改变。类似的,Rapantzikos[35]在3个维度上分别应用离散小波变换,通过每一维的低通和高通的滤波响应来选择时空显著点。同时,为了整合颜色和运动信息,Rapantzikos[36]加入了彩色和运动信息来计算其显著点。
与检测整个人体中兴趣点的出发思路不同,Wong[37]首先检测与运动相关的子空间中的兴趣点,这些子空间对应着一部分的运动,比如说手臂摆动,在这些子空间中,一些稀疏的兴趣点就被检测出来了。类似的方法,Bregonzio[38]首先通过计算后面帧的不同来估计视觉注意的焦点,然后利用gabor滤波在这些区域来检测显著点。
2.2.2 局部特征点的描述
局部特征描述是对图像或者视频中的一个块进行描述,其描述子应该对背景的杂乱程度,尺度和方向变化等均不敏感。一个图像块的空间和时间尺寸大小通常取决于检测到的兴趣点的尺寸。图5显示的是cuboids描述子[34]。
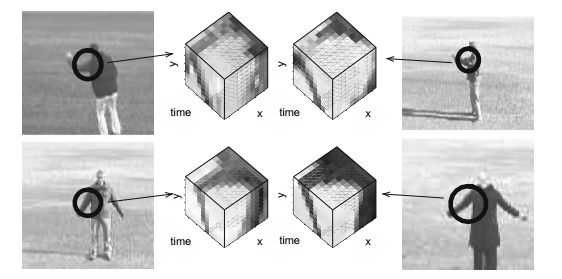
图5 cuboids描述子
特征块也可以用基于局部特征的网格来描述,因为一个网格包括了局部观察到的领域像素,将其看成一个块,这样就减少了时间和空间的局部变化的影响。二维的SURF特征[39]被Willems[40]扩展到了3维,这些eSURF特征的每个cell都包含了全部Harr-wavelet特征。Laotev[14]使用了局部HOG(梯度直方图)和HOF(光流直方图)。Klaser[41]将HOG特征扩展到3维,即形成了3D-HOG。3D-HOG的每个bin都是由规则的多面体构成,3D-HOG允许 在多尺度下对cuboids进行快速密度采样。这种将二维特征点检测的算法扩展到3维特征点类似的工作还有是将SIFT算法[42]扩展到3维SIFT Scovanner[43]。在Wang[44]的文章中,他比较了各种局部描述算子,并发现在大多数情况下整合了梯度和光流信息的描述算子其效果最好。
另外还有一种描述子比较流行,即单词袋[45][46],这是利用的单词频率直方图特征。
2.3 全局、局部特征融合
全局和局部特征的融合,结合了全局特征的足够信息量和局部特征的对视角变化,部分遮挡问题不敏感,抗干扰性强的优点。这样的文章比较多,其主要思想结合从2.1和2.2的方法。Thi[47]就将这2种特征结合得很好,其全局特征是采用前面介绍的MHI算子,并且采用AIFT算法[48]进一步选择更好的MHI。局部特征也是采用前面提到的STIP特征,并且采用SBFC(稀疏贝叶斯特征选择)[49]算法过滤掉一些噪声比较大的特征点。最后将2种特征送入到扩展的3维ISM模型中,其ISM[50]是一种目标识别常用算法,即训练出目标的隐式形状模型。Thi[47]的方法结构如图6所示。

图6 局部特征和全局特征结合
3. 行为识别常见数据库
3.1 Weizmann
Weizmann[27]数据库包含了10个动作分别是走,跑,跳,飞跳,向一侧移动,单只手挥动,2只手挥动,单跳,2只手臂挥动起跳,每个动作有10个人执行。在这个视频集中,其背景是静止的,且前景提供了剪影信息。该数据集较为简单。
3.2 KTH
KTH[45]行人数据库包含了6种动作,分别为走,慢跑,跑挥手和鼓掌。每种动作由25个不同的人完成。每个人在完成这些动作时又是在4个不同的场景中完成的,4个场景分别为室外,室内,室外放大,室外且穿不同颜色的衣服。
3.3 PETS
PETS[51],其全称为跟踪与监控性能评估会议,它的数据库是从现实生活中获取的,主要来源于直接从视频监控系统拍摄的视频,比如说超市的监控系统。从2000年以后,基本上每年都会组织召开这个会议。
3.4 UCF
UCF包含个数据集,这里是指UCF的运动数据库[52],该视频数据包括了150个视频序列,共有13个动作。因为是现实生活中的视频数据,所以其背景比较复杂,这些种类的动作识别起来有些困难。
3.5 INRIA XMAS
INRIA XMAS数据库[53]是从5个视角拍摄的,室内的4个方向和头顶的1个方向。总共有11个人完成14种不同的动作,动作可以沿着任意方向执行。摄像机是静止的,环境的光照条件也基本不变。另外该数据集还提供有人体轮廓和体积元等信息。
3.6 Hollywood
Hollywood电影的数据库包含有几个,其一[14]的视频集有8种动作,分别是接电话,下轿车,握手,拥抱,接吻,坐下,起立,站立。这些动作都是从电影中直接抽取的,由不同的演员在不同的环境下演的。其二[54]在上面的基础上又增加了4个动作,骑车,吃饭,打架,跑。并且其训练集给出了电影的自动描述文本标注,另外一些是由人工标注的。因为有遮挡,移动摄像机,动态背景等因素,所以这个数据集非常有挑战。
4. 总结
本文较全面的介绍了行为识别中特征提取的方法,并将其分为全局特征提取和局部特征提取2个部分介绍,虽然自行为识别研究以来已经取得了不少成果,但是由于视觉中的动态环境,遮挡等问题存在,其挑战非常大,需要提取出鲁棒性更好,适应性更强,效果更好的特征,而这仍是后面几年甚至几十年不断追求努力才能达到的目标。
参考文献:
- Johansson, G. (1975). "Visual motion perception." Scientific American.
- Aggarwal, J. K. and Q. Cai (1997). Human motion analysis: A review, IEEE.
- Moeslund, T. B. and E. Granum (2001). "A survey of computer vision-based human motion capture." Computer vision and image understanding 81(3): 231-268.
- Moeslund, T. B., A. Hilton, et al. (2006). "A survey of advances in vision-based human motion capture and analysis." Computer vision and image understanding 104(2): 90-126.
- Turaga, P., R. Chellappa, et al. (2008). "Machine recognition of human activities: A survey." Circuits and Systems for Video Technology, IEEE Transactions on 18(11): 1473-1488.
- Poppe, R. (2010). "A survey on vision-based human action recognition." Image and Vision Computing 28(6): 976-990.
- Aggarwal, J. and M. S. Ryoo (2011). "Human activity analysis: A review." ACM Computing Surveys (CSUR) 43(3): 16.
- Forsyth, D. A., O. Arikan, et al. (2006). Computational studies of human motion: Tracking and motion synthesis, Now Pub.
- Gavrila, D. M. (1999). "The visual analysis of human movement: A survey." Computer vision and image understanding 73(1): 82-98.
10. Ikizler-Cinbis, N., R. G. Cinbis, et al. (2009). Learning actions from the web, IEEE.
11. Gupta, S. and R. J. Mooney (2009). Using closed captions to train activity recognizers that improve video retrieval, IEEE.
12. Cour, T., C. Jordan, et al. (2008). Movie/script: Alignment and parsing of video and text transcription.
13. Duchenne, O., I. Laptev, et al. (2009). Automatic annotation of human actions in video, IEEE.
14. Laptev, I., M. Marszalek, et al. (2008). Learning realistic human actions from movies, IEEE.
15. Haritaoglu, I., D. Harwood, et al. (1998). "W 4 S: A real-time system for detecting and tracking people in 2 1/2D." Computer Vision—ECCV'98: 877-892.
16. Tao, D., X. Li, et al. (2006). Human carrying status in visual surveillance, IEEE.
17. Davis, J. W. and S. R. Taylor (2002). Analysis and recognition of walking movements, IEEE.
18. Lv, F., X. Song, et al. (2006). Left luggage detection using bayesian inference.
19. Auvinet, E., E. Grossmann, et al. (2006). Left-luggage detection using homographies and simple heuristics.
20. Bobick, A. F. and J. W. Davis (2001). "The recognition of human movement using temporal templates." Pattern Analysis and Machine Intelligence, IEEE Transactions on 23(3): 257-267.
21. Wang, Y., K. Huang, et al. (2007). Human activity recognition based on r transform, IEEE.
22. Chen, H. S., H. T. Chen, et al. (2006). Human action recognition using star skeleton, ACM.
23. Wang, L. and D. Suter (2006). Informative shape representations for human action recognition, Ieee.
24. Weinland, D., E. Boyer, et al. (2007). Action recognition from arbitrary views using 3d exemplars, IEEE.
25. Weinland, D. and E. Boyer (2008). Action recognition using exemplar-based embedding, Ieee.
26. Efros, A. A., A. C. Berg, et al. (2003). Recognizing action at a distance, IEEE.
27. Blank, M., L. Gorelick, et al. (2005). Actions as space-time shapes, IEEE.
28. Gorelick, L., M. Blank, et al. (2007). "Actions as space-time shapes." Pattern Analysis and Machine Intelligence, IEEE Transactions on 29(12): 2247-2253.
29. Achard, C., X. Qu, et al. (2008). "A novel approach for recognition of human actions with semi-global features." Machine Vision and Applications 19(1): 27-34.
30. Batra, D., T. Chen, et al. (2008). Space-time shapelets for action recognition, IEEE.
31. Yilmaz, A. and M. Shah (2008). "A differential geometric approach to representing the human actions." Computer vision and image understanding 109(3): 335-351.
32. Ke, Y., R. Sukthankar, et al. (2007). Spatio-temporal shape and flow correlation for action recognition, IEEE.
33. Laptev, I. (2005). "On space-time interest points." International journal of computer vision 64(2): 107-123.
34. Dollár, P., V. Rabaud, et al. (2005). Behavior recognition via sparse spatio-temporal features, IEEE.
35. Rapantzikos, K., Y. Avrithis, et al. (2007). Spatiotemporal saliency for event detection and representation in the 3D wavelet domain: potential in human action recognition, ACM.
36. Rapantzikos, K., Y. Avrithis, et al. (2009). Dense saliency-based spatiotemporal feature points for action recognition, Ieee.
37. Wong, S. F. and R. Cipolla (2007). Extracting spatiotemporal interest points using global information, IEEE.
38. Bregonzio, M., S. Gong, et al. (2009). Recognising action as clouds of space-time interest points, IEEE.
39. Bay, H., T. Tuytelaars, et al. (2006). "Surf: Speeded up robust features." Computer Vision–ECCV 2006: 404-417.
40. Willems, G., T. Tuytelaars, et al. (2008). "An efficient dense and scale-invariant spatio-temporal interest point detector." Computer Vision–ECCV 2008: 650-663.
41. Klaser, A. and M. Marszalek (2008). "A spatio-temporal descriptor based on 3D-gradients."
42. Mikolajczyk, K. and C. Schmid (2004). "Scale & affine invariant interest point detectors." International journal of computer vision 60(1): 63-86.
43. Scovanner, P., S. Ali, et al. (2007). A 3-dimensional sift descriptor and its application to action recognition, ACM.
44. Wang, H., M. M. Ullah, et al. (2009). "Evaluation of local spatio-temporal features for action recognition."
45. Niebles, J. C., H. Wang, et al. (2008). "Unsupervised learning of human action categories using spatial-temporal words." International journal of computer vision 79(3): 299-318.
46. Schuldt, C., I. Laptev, et al. (2004). Recognizing human actions: A local SVM approach, IEEE.
47. Thi, T. H., L. Cheng, et al. (2011). "Integrating local action elements for action analysis." Computer vision and image understanding.
48. Liu, G., Z. Lin, et al. (2009). "Radon representation-based feature descriptor for texture classification." Image Processing, IEEE Transactions on 18(5): 921-928.
49. Carbonetto, P., G. Dorkó, et al. (2008). "Learning to recognize objects with little supervision." International journal of computer vision 77(1): 219- 237.
50. Leibe, B., A. Leonardis, et al. (2008). "Robust object detection with interleaved categorization and segmentation." International journal of
computer vision 77(1): 259-289.
51. http://www.cvg.rdg.ac.uk/slides/pets.html.
52. Rodriguez, M. D. (2008). "Action mach a spatio-temporal maximum average correlation height filter for action recognition." CVPR.
53. Weinland, D., R. Ronfard, et al. (2006). "Free viewpoint action recognition using motion history volumes." Computer vision and image
understanding 104(2): 249-257.
54. Marszalek, M., I. Laptev, et al. (2009). Actions in context, IEEE.