C++学习之深入理解虚函数--虚函数表解析
C++学习之深入理解虚函数--虚函数表解析
目录(?)[+]
转自:http://blog.csdn.net/haoel/article/details/1948051/
前言
C++中的虚函数的作用主要是实现了多态的机制。关于多态,简而言之就是用父类型别的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数。这种技术可以让父类的指针有“多种形态”,这是一种泛型技术。所谓泛型技术,说白了就是试图使用不变的代码来实现可变的算法。比如:模板技术,RTTI技术,虚函数技术,要么是试图做到在编译时决议,要么试图做到运行时决议。
关于虚函数的使用方法,我在这里不做过多的阐述。大家可以看看相关的C++的书籍。在这篇文章中,我只想从虚函数的实现机制上面为大家 一个清晰的剖析。
当然,相同的文章在网上也出现过一些了,但我总感觉这些文章不是很容易阅读,大段大段的代码,没有图片,没有详细的说明,没有比较,没有举一反三。不利于学习和阅读,所以这是我想写下这篇文章的原因。也希望大家多给我提意见。
言归正传,让我们一起进入虚函数的世界。
虚函数表
对C++ 了解的人都应该知道虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的。简称为V-Table。在这个表中,主是要一个类的虚函数的地址表,这张表解决了继承、覆盖的问题,保证其容真实反应实际的函数。这样,在有虚函数的类的实例中这个表被分配在了这个实例的内存中,所以,当我们用父类的指针来操作一个子类的时候,这张虚函数表就显得由为重要了,它就像一个地图一样,指明了实际所应该调用的函数。
这里我们着重看一下这张虚函数表。C++的编译器应该是保证虚函数表的指针存在于对象实例中最前面的位置(这是为了保证取到虚函数表的有最高的性能——如果有多层继承或是多重继承的情况下)。 这意味着我们通过对象实例的地址得到这张虚函数表,然后就可以遍历其中函数指针,并调用相应的函数。
听我扯了那么多,我可以感觉出来你现在可能比以前更加晕头转向了。 没关系,下面就是实际的例子,相信聪明的你一看就明白了。
假设我们有这样的一个类:
class Base {
public:
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
virtual void h() { cout << "Base::h" << endl; }
};
按照上面的说法,我们可以通过Base的实例来得到虚函数表。 下面是实际例程:
typedef void(*Fun)(void);
Base b;
Fun pFun = NULL;
cout << "虚函数表地址:" << (int*)(&b) << endl;
/*我认为 (int*)(&b) 为虚函数表地址 存放的地址,因为对象内存放的是虚函数表的地址
 */
*/
cout << "虚函数表 — 第一个函数地址:" << (int*)*(int*)(&b) << endl;
// Invoke the first virtual function
pFun = (Fun)*((int*)*(int*)(&b));
pFun();
实际运行经果如下:(Windows XP+VS2003, Linux 2.6.22 + GCC 4.1.3)
虚函数表地址:0012FED4
虚函数表 — 第一个函数地址:0044F148
Base::f
通过这个示例,我们可以看到,我们可以通过强行把&b转成int *,取得虚函数表的地址,然后,再次取址就可以得到第一个虚函数的地址了,也就是Base::f(),这在上面的程序中得到了验证(把int*强制转成了函数指针)。通过这个示例,我们就可以知道如果要调用Base::g()和Base::h(),其代码如下:
(Fun)*((int*)*(int*)(&b)+0); // Base::f()
(Fun)*((int*)*(int*)(&b)+1); // Base::g()
(Fun)*((int*)*(int*)(&b)+2); // Base::h()
这个时候你应该懂了吧。什么?还是有点晕。也是,这样的代码看着太乱了。没问题,让我画个图解释一下。如下所示:
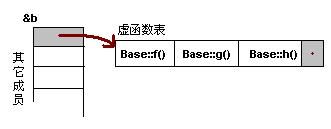
注意:在上面这个图中,我在虚函数表的最后多加了一个结点,这是虚函数表的结束结点,就像字符串的结束符“/0”一样,其标志了虚函数表的结束。这个结束标志的值在不同的编译器下是不同的。在WinXP+VS2003下,这个值是NULL。而在Ubuntu 7.10 + Linux 2.6.22 + GCC 4.1.3下,这个值是如果1,表示还有下一个虚函数表,如果值是0,表示是最后一个虚函数表。
下面,我将分别说明“无覆盖”和“有覆盖”时的虚函数表的样子。没有覆盖父类的虚函数是毫无意义的。我之所以要讲述没有覆盖的情况,主要目的是为了给一个对比。在比较之下,我们可以更加清楚地知道其内部的具体实现。
一般继承(无虚函数覆盖)
下面,再让我们来看看继承时的虚函数表是什么样的。假设有如下所示的一个继承关系:
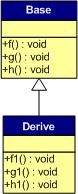
请注意,在这个继承关系中,子类没有重载任何父类的函数。那么,在派生类的实例中,其虚函数表如下所示:
对于实例:Derive d; 的虚函数表如下:
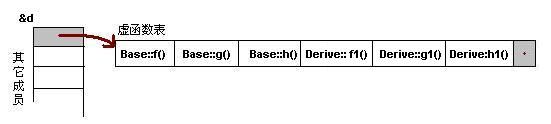
我们可以看到下面几点:
1)虚函数按照其声明顺序放于表中。
2)父类的虚函数在子类的虚函数前面。
(当然没父类时有虚函数 和父类中没虚函数时也会有个虚表)
我相信聪明的你一定可以参考前面的那个程序,来编写一段程序来验证。
一般继承(有虚函数覆盖)
覆盖父类的虚函数是很显然的事情,不然,虚函数就变得毫无意义。下面,我们来看一下,如果子类中有虚函数重载了父类的虚函数,会是一个什么样子?假设,我们有下面这样的一个继承关系。

为了让大家看到被继承过后的效果,在这个类的设计中,我只覆盖了父类的一个函数:f()。那么,对于派生类的实例,其虚函数表会是下面的一个样子:
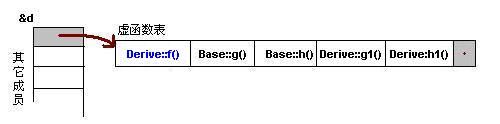
我们从表中可以看到下面几点,
1)覆盖的f()函数被放到了虚表中原来父类虚函数的位置。
2)没有被覆盖的函数依旧。
这样,我们就可以看到对于下面这样的程序,
Base *b = new Derive();
b->f();
由b所指的内存中的虚函数表的f()的位置已经被Derive::f()函数地址所取代,于是在实际调用发生时,是Derive::f()被调用了。这就实现了多态。
多重继承(无虚函数覆盖)
下面,再让我们来看看多重继承中的情况,假设有下面这样一个类的继承关系。注意:子类并没有覆盖父类的函数。
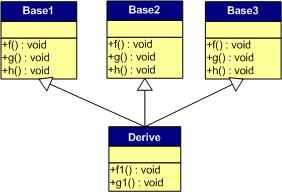
对于子类实例中的虚函数表,是下面这个样子:

我们可以看到:
1) 每个父类都有自己的虚表(所以对应每个基类,子类对象中就多一个指针所占的空间)。
2) 子类的成员函数被放到了第一个父类的表中。(所谓的第一个父类是按照声明顺序来判断的)
这样做就是为了解决不同的父类类型的指针指向同一个子类实例,而能够调用到实际的函数。
多重继承(有虚函数覆盖)
下面我们再来看看,如果发生虚函数覆盖的情况。
下图中,我们在子类中覆盖了父类的f()函数。
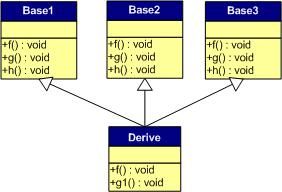
下面是对于子类实例中的虚函数表的图:

我们可以看见,三个父类虚函数表中的f()的位置被替换成了子类的函数指针。这样,我们就可以任一静态类型的父类来指向子类,并调用子类的f()了。如:
Derive d;
Base1 *b1 = &d;
Base2 *b2 = &d;
Base3 *b3 = &d;
b1->f(); //Derive::f()
b2->f(); //Derive::f()
b3->f(); //Derive::f()
b1->g(); //Base1::g()
b2->g(); //Base2::g()
b3->g(); //Base3::g()
安全性
每次写C++的文章,总免不了要批判一下C++。这篇文章也不例外。通过上面的讲述,相信我们对虚函数表有一个比较细致的了解了。水可载舟,亦可覆舟。下面,让我们来看看我们可以用虚函数表来干点什么坏事吧。
一、通过父类型的指针访问子类自己的虚函数
我们知道,子类没有重载父类的虚函数是一件毫无意义的事情。因为多态也是要基于函数重载的。虽然在上面的图中我们可以看到Base1的虚表中有Derive的虚函数,但我们根本不可能使用下面的语句来调用子类的自有虚函数:
Base1 *b1 = new Derive();
b1->f1(); //编译出错
任何妄图使用父类指针想调用子类中的未覆盖父类的成员函数的行为都会被编译器视为非法,所以,这样的程序根本无法编译通过。但在运行时,我们可以通过指针的方式访问虚函数表来达到违反C++语义的行为。(关于这方面的尝试,通过阅读后面附录的代码,相信你可以做到这一点)
二、访问non-public的虚函数
另外,如果父类的虚函数是private或是protected的,但这些非public的虚函数同样会存在于虚函数表中,所以,我们同样可以使用访问虚函数表的方式来访问这些non-public的虚函数,这是很容易做到的。
如:
class Base {
private:
virtual void f() { cout << "Base::f" << endl; }
};
class Derive : public Base{
};
typedef void(*Fun)(void);
void main() {
Derive d;
Fun pFun = (Fun)*((int*)*(int*)(&d)+0);
pFun();
}
结束语
C++这门语言是一门Magic的语言,对于程序员来说,我们似乎永远摸不清楚这门语言背着我们在干了什么。需要熟悉这门语言,我们就必需要了解C++里面的那些东西,需要去了解C++中那些危险的东西。不然,这是一种搬起石头砸自己脚的编程语言。
在文章束之前还是介绍一下自己吧。我从事软件研发有十个年头了,目前是软件开发技术主管,技术方面,主攻Unix/C/C++,比较喜欢网络上的技术,比如分布式计算,网格计算,P2P,Ajax等一切和互联网相关的东西。管理方面比较擅长于团队建设,技术趋势分析,项目管理。欢迎大家和我交流,我的MSN和Email是:[email protected]
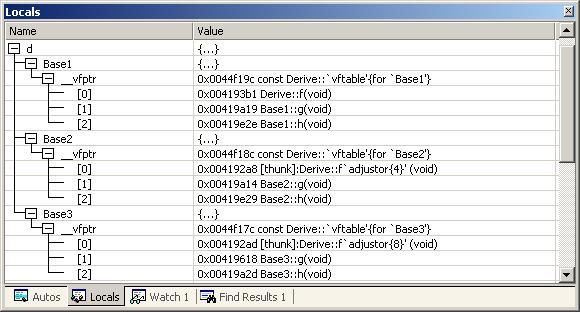
附录一:VC中查看虚函数表
我们可以在VC的IDE环境中的Debug状态下展开类的实例就可以看到虚函数表了(并不是很完整的)
附录 二:例程
下面是一个关于多重继承的虚函数表访问的例程:
- #include
- using namespace std;
- class Base1 {
- public:
- virtual void f() { cout << "Base1::f" << endl; }
- virtual void g() { cout << "Base1::g" << endl; }
- virtual void h() { cout << "Base1::h" << endl; }
- };
- class Base2 {
- public:
- virtual void f() { cout << "Base2::f" << endl; }
- virtual void g() { cout << "Base2::g" << endl; }
- virtual void h() { cout << "Base2::h" << endl; }
- };
- class Base3 {
- public:
- virtual void f() { cout << "Base3::f" << endl; }
- virtual void g() { cout << "Base3::g" << endl; }
- virtual void h() { cout << "Base3::h" << endl; }
- };
- class Derive : public Base1, public Base2, public Base3 {
- public:
- virtual void f() { cout << "Derive::f" << endl; }
- virtual void g1() { cout << "Derive::g1" << endl; }
- };
- typedef void(*Fun)(void);
- int main()
- {
- Fun pFun = NULL;
- Derive d;
- int** pVtab = (int**)&d;
- //Base1's vtable
- //pFun = (Fun)*((int*)*(int*)((int*)&d+0)+0);
- pFun = (Fun)pVtab[0][0];
- pFun();
- //pFun = (Fun)*((int*)*(int*)((int*)&d+0)+1);
- pFun = (Fun)pVtab[0][1];
- pFun();
- //pFun = (Fun)*((int*)*(int*)((int*)&d+0)+2);
- pFun = (Fun)pVtab[0][2];
- pFun();
- //Derive's vtable
- //pFun = (Fun)*((int*)*(int*)((int*)&d+0)+3);
- pFun = (Fun)pVtab[0][3];
- pFun();
- //The tail of the vtable
- pFun = (Fun)pVtab[0][4];
- cout<
- //Base2's vtable
- //pFun = (Fun)*((int*)*(int*)((int*)&d+1)+0);
- pFun = (Fun)pVtab[1][0];
- pFun();
- //pFun = (Fun)*((int*)*(int*)((int*)&d+1)+1);
- pFun = (Fun)pVtab[1][1];
- pFun();
- pFun = (Fun)pVtab[1][2];
- pFun();
- //The tail of the vtable
- pFun = (Fun)pVtab[1][3];
- cout<
- //Base3's vtable
- //pFun = (Fun)*((int*)*(int*)((int*)&d+1)+0);
- pFun = (Fun)pVtab[2][0];
- pFun();
- //pFun = (Fun)*((int*)*(int*)((int*)&d+1)+1);
- pFun = (Fun)pVtab[2][1];
- pFun();
- pFun = (Fun)pVtab[2][2];
- pFun();
- //The tail of the vtable
- pFun = (Fun)pVtab[2][3];
- cout<
- return 0;
- }
参考: VC++对象模型
浅谈C++多态性
版权声明:本文为博主原创文章,未经博主允许不得转载。
多态性可以简单地概括为“一个接口,多种方法”,程序在运行时才决定调用的函数,它是面向对象编程领域的核心概念。多态(polymorphism),字面意思多种形状。
C++多态性是通过虚函数来实现的,虚函数允许子类重新定义成员函数,而子类重新定义父类的做法称为覆盖(override),或者称为重写。(这里我觉得要补充,重写的话可以有两种,直接重写成员函数和重写虚函数,只有重写了虚函数的才能算作是体现了C++多态性)而重载则是允许有多个同名的函数,而这些函数的参数列表不同,允许参数个数不同,参数类型不同,或者两者都不同。编译器会根据这些函数的不同列表,将同名的函数的名称做修饰,从而生成一些不同名称的预处理函数,来实现同名函数调用时的重载问题。但这并没有体现多态性。
多态与非多态的实质区别就是函数地址是早绑定还是晚绑定。如果函数的调用,在编译器编译期间就可以确定函数的调用地址,并生产代码,是静态的,就是说地址是早绑定的。而如果函数调用的地址不能在编译器期间确定,需要在运行时才确定,这就属于晚绑定。
那么多态的作用是什么呢,封装可以使得代码模块化,继承可以扩展已存在的代码,他们的目的都是为了代码重用。而多态的目的则是为了接口重用。也就是说,不论传递过来的究竟是那个类的对象,函数都能够通过同一个接口调用到适应各自对象的实现方法。
最常见的用法就是声明基类的指针,利用该指针指向任意一个子类对象,调用相应的虚函数,可以根据指向的子类的不同而实现不同的方法。如果没有使用虚函数的话,即没有利用C++多态性,则利用基类指针调用相应的函数的时候,将总被限制在基类函数本身,而无法调用到子类中被重写过的函数。因为没有多态性,函数调用的地址将是一定的,而固定的地址将始终调用到同一个函数,这就无法实现一个接口,多种方法的目的了。
笔试题目:
- #include
- using namespace std;
- class A
- {
- public:
- void foo()
- {
- printf("1\n");
- }
- virtual void fun()
- {
- printf("2\n");
- }
- };
- class B : public A
- {
- public:
- void foo()
- {
- printf("3\n");
- }
- void fun()
- {
- printf("4\n");
- }
- };
- int main(void)
- {
- A a;
- B b;
- A *p = &a;
- p->foo();
- p->fun();
- p = &b;
- p->foo();
- p->fun();
- return 0;
- }
第二个输出结果就是1、4。p->foo()和p->fuu()则是基类指针指向子类对象,正式体现多态的用法,p->foo()由于指针是个基类指针,指向是一个固定偏移量的函数,因此此时指向的就只能是基类的foo()函数的代码了,因此输出的结果还是1。而p->fun()指针是基类指针,指向的fun是一个虚函数,由于每个虚函数都有一个虚函数列表,此时p调用fun()并不是直接调用函数,而是通过虚函数列表找到相应的函数的地址,因此根据指向的对象不同,函数地址也将不同,这里将找到对应的子类的fun()函数的地址,因此输出的结果也会是子类的结果4。
笔试的题目中还有一个另类测试方法。即
B *ptr = (B *)&a; ptr->foo(); ptr->fun();
问这两调用的输出结果。这是一个用子类的指针去指向一个强制转换为子类地址的基类对象。结果,这两句调用的输出结果是3,2。
并不是很理解这种用法,从原理上来解释,由于B是子类指针,虽然被赋予了基类对象地址,但是ptr->foo()在调用的时候,由于地址偏移量固定,偏移量是子类对象的偏移量,于是即使在指向了一个基类对象的情况下,还是调用到了子类的函数,虽然可能从始到终都没有子类对象的实例化出现。
而ptr->fun()的调用,可能还是因为C++多态性的原因,由于指向的是一个基类对象,通过虚函数列表的引用,找到了基类中fun()函数的地址,因此调用了基类的函数。由此可见多态性的强大,可以适应各种变化,不论指针是基类的还是子类的,都能找到正确的实现方法。
- //小结:1、有virtual才可能发生多态现象
- // 2、不发生多态(无virtual)调用就按原类型调用
- #include
- using namespace std;
- class Base
- {
- public:
- virtual void f(float x)
- {
- cout<<"Base::f(float)"<< x <
- }
- void g(float x)
- {
- cout<<"Base::g(float)"<< x <
- }
- void h(float x)
- {
- cout<<"Base::h(float)"<< x <
- }
- };
- class Derived : public Base
- {
- public:
- virtual void f(float x)
- {
- cout<<"Derived::f(float)"<< x <
- }
- void g(int x)
- {
- cout<<"Derived::g(int)"<< x <
- }
- void h(float x)
- {
- cout<<"Derived::h(float)"<< x <
- }
- };
- int main(void)
- {
- Derived d;
- Base *pb = &d;
- Derived *pd = &d;
- // Good : behavior depends solely on type of the object
- pb->f(3.14f); // Derived::f(float) 3.14
- pd->f(3.14f); // Derived::f(float) 3.14
- // Bad : behavior depends on type of the pointer
- pb->g(3.14f); // Base::g(float) 3.14
- pd->g(3.14f); // Derived::g(int) 3
- // Bad : behavior depends on type of the pointer
- pb->h(3.14f); // Base::h(float) 3.14
- pd->h(3.14f); // Derived::h(float) 3.14
- return 0;
- }
本来仅仅区别重载与覆盖并不算困难,但是C++的隐藏规则使问题复杂性陡然增加。
这里“隐藏”是指派生类的函数屏蔽了与其同名的基类函数,规则如下:
(1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual
关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual
关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)。
上面的程序中:
(1)函数Derived::f(float)覆盖了Base::f(float)。
(2)函数Derived::g(int)隐藏了Base::g(float),而不是重载。
(3)函数Derived::h(float)隐藏了Base::h(float),而不是覆盖。
C++纯虚函数
一、定义
纯虚函数是在基类中声明的虚函数,它在基类中没有定义,但要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加“=0”
virtual void funtion()=0
二、引入原因
1、为了方便使用多态特性,我们常常需要在基类中定义虚拟函数。
2、在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。
为了解决上述问题,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:virtual ReturnType Function()= 0;),则编译器要求在派生类中必须予以重写以实现多态性。同时含有纯虚拟函数的类称为抽象类,它不能生成对象。这样就很好地解决了上述两个问题。
三、相似概念
1、多态性
指相同对象收到不同消息或不同对象收到相同消息时产生不同的实现动作。C++支持两种多态性:编译时多态性,运行时多态性。
a、编译时多态性:通过重载函数实现
b、运行时多态性:通过虚函数实现。
2、虚函数
虚函数是在基类中被声明为virtual,并在派生类中重新定义的成员函数,可实现成员函数的动态覆盖(Override)
3、抽象类
包含纯虚函数的类称为抽象类。由于抽象类包含了没有定义的纯虚函数,所以不能定义抽象类的对象。
重写、覆盖、重载、多态几个概念的区别分析
版权声明:本文为博主原创文章,未经博主允许不得转载。
重写(覆盖)的规则:
1、重写方法的参数列表必须完全与被重写的方法的相同,否则不能称其为重写而是重载.
2、重写方法的访问修饰符一定要大于被重写方法的访问修饰符(public>protected>default>private)。
3、重写的方法的返回值必须和被重写的方法的返回一致;
4、重写的方法所抛出的异常必须和被重写方法的所抛出的异常一致,或者是其子类;
5、被重写的方法不能为private,否则在其子类中只是新定义了一个方法,并没有对其进行重写。
重载的规则:
1、在使用重载时只能通过相同的方法名、不同的参数形式实现。不同的参数类型可以是不同的参数类型,不同的参数个数,不同的参数顺序(参数类型必须不一样);
2、不能通过访问权限、返回类型、抛出的异常进行重载;
3、方法的异常类型和数目不会对重载造成影响;
一般,我们使用多态是为了避免在父类里大量重载引起代码臃肿且难于维护。
public class Shape
{
public static void main(String[] args){
Triangle tri = new Triangle();
System.out.println("Triangle is a type of shape? " + tri.isShape());// 继承
System.out.println("My shape has " + shape.getSides() + " sides."); // 多态
Shape shape2 = Rec;
System.out.println("My shape has " + shape2.getSides(Rec) + " sides."); //重载
}
public boolean isShape(){
return true;
}
public int getSides(){
return 0 ;
}
public int getSides(Triangle tri){ //重载
return 3 ;
}
public int getSides(Rectangle rec){ //重载
return 4 ;
}
}
{
public int getSides() { //重写,实现多态
return 3;
}
}
class Rectangle extends Shape
{
public int getSides(int i) { //重载
return i;
}
}
如果用重载,则在父类里要对应每一个子类都重载一个取得边数的方法;
如果用多态,则父类只提供取得边数的接口,至于取得哪个形状的边数,怎样取得,在子类里各自实现(重写)。
分类:
三大基石之一 封装
1.什么是封装?
封装(encapsulation)又叫隐藏实现(Hiding the implementation)。就是只公开代码单元的对外接口,而隐藏其具体实现。
比如你的手机,手机的键盘,屏幕,听筒等,就是其对外接口。你只需要知道如何按键就可以使用手机,而不需要了解手机内部的电路是如何工作的。封装机制就像手机一样只将对外接口暴露,而不需要用户去了解其内部实现。细心观察,现实中很多东西都具有这样的特点。
2.如何实现封装?
在程序设计里,封装往往是通过访问控制实现的。C++,Java,AS3中都有 Public, Protected, Private 等访问控制符。通过用Public将信息暴露,Private,Protected将信息隐藏,来实现封装。
一个优秀的OOP程序员会尽量不对外公开代码,即最喜欢用Private关键字。因为在OOP中,对代码访问控制得越严格,日后你对代码修改的自由就越大。
--摘自《AS3殿堂之路》。这一点会在下面给出更详细的解释。
3.为什么要封装?封装带来的好处。
a.封装使得对代码的修改更加安全和容易。将代码分成了一个个相对独立的单元。
只要电话的外部接口(键盘,屏幕,使用方法等)不发生改变,那么不管电话内部电路,技术如何改进,你都不需要重新学习就可以使用新一代的电话。同样,只要汽车的方向盘,刹车等外部接口不变,那么,不论如何改造它的发动机,你也一样会驾驶这类汽车。
封装所带来的好处是:明确的指出了那些属性和方法是外部可以访问的。这样当你需要调整这个类的代码时,只要保证公有(Public:)属性不变,公有方法的参数和返回值类型不变,那么你就可以尽情的修改这个类,而不会影响到程序的其他部分,或者是使用到这个类的其他程序。这就是为什么刚刚说的“在OOP中,对代码访问控制得越严格,日后你对代码修改的自由就越大”。
b.封装使整个软件开发复杂度大大降低。
能很好的使用别人的类(class),而不必关心其内部逻辑是如何实现的。你能很容易学会使用别人写好的代码,这就让软件协同开发的难度大大降低。
c.封装还避免了命名冲突的问题。
封装有隔离作用。电话上的按键和电视遥控器上的按键肯定用处不同。但它们都可以叫做按键,为什么你没有弄混呢?很显然一个属于电话类一个属于遥控器类。不同的类中可以有相同名称的方法和属性,但不会混淆。
三大基石之二 继承与复合
核心思想不仅仅是重用现有的代码,用一些已有的类去创建新的类。
1.继承
继承,Inheritance,是一种看起来很神奇的代码重用方式。
除了这一点,继承(这里只限于公有继承,私有继承和保护继承方式会破坏向上转换这一特性)还产生了另一种奇妙的东西叫做向上转换或向上映射(Upcasting)。就是说在代码中可以将子类对象作为父类对象来使用。
其实,这里所提到的继承思想在人类的生活中并不常见(程序设计中继承也较难掌握),多出现在人类对自然界的分类。我们观察周围的世界发现,人们更喜欢用的是复合和一种特殊形式的继承(对抽象类的继承,会在多态中讲到。如汽车继承于交通工具这个抽象类)。
2.复合
复合,Composition,即将各个部分组合在一起。程序设计中就是用已有类的对象来产生新的类。
桌子由木板和钉子组合而成,台灯使用灯座,灯管,电线,接头等拼起来的。我们发现自己周围的很多东西都是由更小的其它东西拼凑构成的,就像积木一样。相信你小的时候也曾拆开过许多你觉得好奇的东西,去一看究竟。去看看这个新的类(class)到底是由那些其他的类构成的。其实在你很小的时候你已经理解了复合。
程序设计中,复合体现在生成的新类里用到了现有类的实例,具体的代码例子在这里也不给出了,相信你一看就能明白。
复合使生成新类更加简便和直观,实现也非常容易,相比继承这种通过已有类构造新类的方法,大多数人(包括在现实生活中)更喜欢复合。
3.何时用继承,何时用复合?
在实际编程中,使用复合的频率要远远超过继承,对于OOP新手而言,要慎用继承,勤用复合。有些极端的OOP人士推崇复合憎恨继承,声称继承是“邪恶”的,一切都是复合。虽然是极端之言,博大家一笑,但实际应用中复合确实比继承灵活,而且更加直白。
虽然继承号称面向对象的三大基石之一,但不正确的使用继承不仅仅是代码维护的灾难,也是真是逻辑的扭曲。因此,在看完了下面的一段后,你还是暂时不明白何时用复合何时用继承的话,请优先考虑复合。
a.需要用到向上转换时请考虑继承。
b.用“has a”和“is a”来区分复合和继承。即考虑新类是有一个(has a)现有类的对象(如新类为汽车,现有类为轮胎,请考虑复合),或是新类是一个(is a)现有类的特殊情况(如蝴蝶和昆虫,考虑继承)。
三大基石之三 多态
多态,Polymorphism,意思是多种形态。
广义上的多态包括以下几个例子:
a.家里的保险丝坏了,你用铁丝代替,这就实行了强制类型转换,强制把铁丝当做保险丝使用。这叫做强制多态。在代码中的体现是强制类型转换,就像用铁丝去代替保险丝可能产生危险,强制类型转换也可能造成精度丢失等后果。
b.另一种多态叫重载多态,运算符重载和函数(方法)重载就是重载多态。
c. 还有参数多态,代码中的表现是类模板和函数模板。
d.下面,重点介绍下包含多态。下面解释一下抽象类和接口。
抽象类(Abstract Class)
人们将一类东西所共同具有的某种功能整合形成了一个抽象类。交通工具表明,这个抽象类的子类汽车,火车等都具有运送人或货物的功能。药物都具有治疗作用。能够用来喝茶的叫做茶具...
接口(Interface)
再说接口,Interface,接口仅仅包含一组方法声明没有具体的代码实现。只要是实现同一个接口的类都具有这个接口的特征。接口如同协议描述了实现接口的对象向外部的承诺。这样其他的对象就可以根据这个协议来和实现接口的对象交流。
其实,抽象类就实现了接口的功能,如果你暂时不理解接口的话,可以把抽象类理解为接口。
为什么要用抽象类或是接口?
抽象类作为一个父类中和了子类的一些共同的行为。重要的是在使用时可以作为子类的共同类型而存在,同时给与了子类最大的灵活性。
OOP编程中有一条重要的法则,即依赖倒转原则(Dependence Inversion Principle), 其含义是:要做任何具体代码实现,首先要依赖于抽象类的实现。这个原则有多种表述,其中的一种广为人知的解释为:要根据接口编程,而不是根据实现编程。在具体的代码中要尽量使用抽象类,而不使用具体类(这当然只是理想化的境界)。
下面举一个代码例子,实际上就是《C++面向对象编程基础》里的例子。有一个抽象类Shape,具有draw和erase方法,当然,draw和erase都是空方法,在C++中用纯虚函数实现。Round类继承于Shape类重写了Shape的draw和erase方法用来画圆和清除图形。Line类继承于Shape类重写了Shape的draw和erase方法用来画直线和清除图形。Triangle类继承于Shape类重写了Shape的draw和erase方法用来画三角形和清除图形。它们的UML表述为:
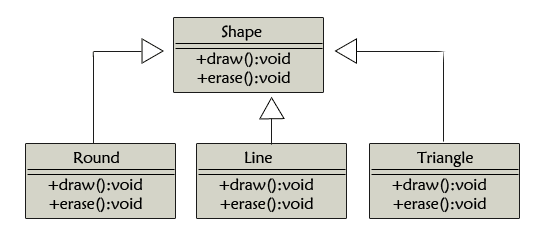
这样的话我们可以写这样一个drawshape的函数:
void drawShape( Shape& s ){ s.draw(); }
注意这个函数的参数类型是Shape ,就意味着这里可以放 Round, Line, 或 Triangle 类的实例,当:
Round r;
drawShape(r);
即可以画出一个圆, 当:
Line l;
drawShape(l);
画出的就是一条线。现在你大概能体会到抽象类(接口)给代码带来的灵活性了吧。而且我们还可以随时向Shape父类中添加子类。