十大经典数据挖掘算法之Apriori算法
1、算法简介
Apriori algorithm是关联规则里一项基本算法。其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集,是由Rakesh Agrawal和Ramakrishnan Srikant两位博士在1994年提出的关联规则挖掘算法。关联规则的目的就是在一个数据集中找出项与项之间的关系,也被称为购物蓝分析 (Market Basket analysis),“购物蓝分析”很贴切的表达了适用该算法情景中的一个子集。关于这个算法有一个非常有名的故事:"尿布和啤酒"。故事是这样的:美国的妇女们经常会嘱咐她们的丈夫下班后为孩子买尿布,而丈夫在买完尿布后又要顺 手买回自己爱喝的啤酒,因此啤酒和尿布在一起被购买的机会很多。这个举措使尿布和啤酒的销量双双增加,并一直为众商家所津津乐道。
2、算法的一些基本概念和定义
资料库(Transaction Database):存储着二维结构的记录集。定义为:D
所有项集(Items):所有项目的集合。定义为:I。
记录 (Transaction ):在资料库里的一笔记录。定义为:T,T ∈ D
项集(Itemset):同时出现的项的集合。定义为:k-itemset(k项集),k均表示项数。
支持度(support):定义为 supp(X) = occur(X) / count(D) = P(X)。P(A ∩ B)表示既有A又有B的概率,例如购物篮分析:牛奶 ⇒ 面包,支持度3%:意味着3%顾客同时购买牛奶和面包
置信度(Confidence):定义为 conf(X->Y) = supp(X ∪ Y) / supp(X) = P(Y|X)。 P(B|A),在A发生的事件中同时发生B的概率 p(AB)/P(A) 例如购物篮分析:牛奶 ⇒ 面包,置信度40%:意味着购买牛奶的顾客40%也购买面包
候选集(Candidate itemset):通过向下合并得出的项集。定义为C[k]。
频繁k项集:如果事件A中包含k个元素,那么称这个事件A为k项集事件A满足最小支持度阈值的事件称为频繁k项集。即支持度大于等于特定的最小支持度(Minimum Support/minsup)的项集,表示为L[k]。注意,频繁集的子集一定是频繁集。
强规则:同时满足最小支持度阈值和最小置信度阈值的规则称为强规则。即lift(X -> Y) = lift(Y -> X) = conf(X -> Y)/supp(Y) = conf(Y -> X)/supp(X) = P(X and Y)/(P(X)P(Y))
3、实现步骤:
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,正如我们之前所提到的,我们希望置信度和支持度要满足我们的阈值范围才算是有效的规则,实际过程中我们往往会面临大量的数据,如果只是简单的搜索,会出现很多的规则,相当大的一部分是无效的规则,效率很低,那么Apriori就是通过产生频繁项集,然后再依据频繁项集产生规则,进而提升效率。以上所说的代表了Apriori算法的两个步骤:产生频繁项集和依据频繁项集产生规则。
频繁项集就是对包含项目A的项目集C,其支持度大于等于指定的支持度,则C(A)为频繁项集,包含一个项目的频繁项集称为频繁1-项集,即L1。
如何寻找频繁项集?Apriori使用一种称作逐层搜索的迭代方法,即“K-1项集”用于搜索“K项集”。首先,找出频繁“1项集”的集合,该集合记作L1。L1用于找频繁“2项集”的集合L2,而L2用于找L3。如此下去,直到不能找到“K项集”。找每个Lk都需要一次数据库扫描。核心思想是:连接步和剪枝步。连接步是自连接,原则是保证前k-2项相同,并按照字典顺序连接。剪枝步,是使任一频繁项集的所有非空子集也必须是频繁的。反之,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从CK中删除。简单的讲,1、发现频繁项集,过程为:(1)扫描(2)计数(3)比较(4)产生频繁项集(5)连接、剪枝,产生候选项集 重复步骤(1)~(5)直到不能发现更大的频集。这里不再讲述,直接说一个例子大家就都明白了。Apriori寻找频繁项集的过程是一个不断迭代的过程,每次都是两个步骤,产生候选集Ck(可能成为频繁项集的项目组合);基于候选集Ck计算支持度,确定Lk。Apriori的寻找策略就是从包含少量的项目开始逐渐向多个项目的项目集搜索。
数据如下:
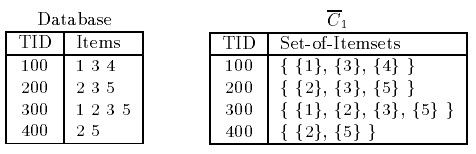
我们看到,数据库存储的数据格式,会员100购买了 1 3 4三种商品,那么对应的集合形式如右边的图所示。那么基于候选集C1,我们得到频繁项集L1,如下图所示,在此表格中{4}的支持度为1,而我们设定的支持度为2。支持度大于或者等于指定的支持度的最小阈值就成为L1了,这里{4}没有成为L1的一员。因此,我们认定包含4的其他项集都不可能是频繁项集,后续就不再对其进行判断了。
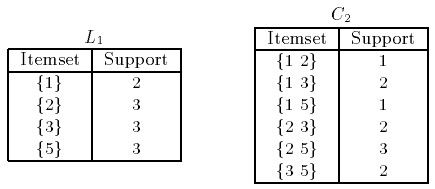
此时我们看到L1是符合最低支持度的标准的,那么下一次迭代我们依据L1产生C2(4就不再被考虑了),此时的候选集如右图所示C2(依据L1*L1的组合方式)确立。C2的每个集合得到的支持度对应在我们原始数据组合的计数,如下图左所示。

此时,第二次迭代发现了{1 2} {1 5}的支持度只有1,低于阈值,故而舍弃,那么在随后的迭代中,如果出现{1 2} {1 5}的组合形式将不被考虑。

如上图,由L2得到候选集C3,那么这次迭代中的{1 2 3} { 1 3 5}哪去了?如刚才所言,{1 2} {1 5}的组合形式将不被考虑,因为这两个项集不可能成为频繁项集L3,此时L4不能构成候选集L4,即停止。
如果用一句化解释上述的过程,就是不断通过Lk的自身连接,形成候选集,然后在进行剪枝,除掉无用的部分。
第二个例子更容易理解,如下图过程:
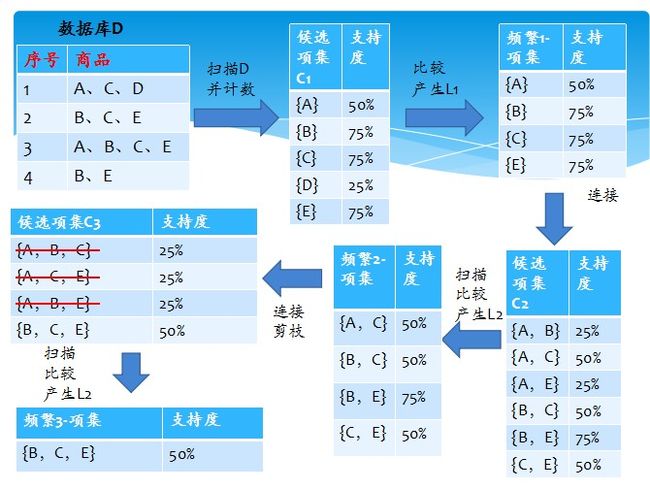
得到了频繁项集,就可以根据频繁项集产生简单关联规则
4、算法的优缺点:
Apriori算法的优点:Apriori的关联规则是在频繁项集基础上产生的,进而这可以保证这些规则的支持度达到指定的水平,具有普遍性和令人信服的水平。
Apriori算法的缺点:需要多次扫描数据库;生成大量备选项集;计数工作量太大。