文本生成:基于GPT-2的中文新闻文本生成
文本生成一直是NLP领域内研究特别活跃的一个任务,应用前景特别广泛。BERT类预训练模型基于MLM,融合了双向上下文信息,不是天然匹配文本生成类任务(也有针对BERT模型进行改进的多种方式完善了BERT的这个缺点,如UniLM)。openAI的GPT-2模型天然适合文本生成类任务,因此使用GPT-2模型来完成中文新闻文本生成任务。
代码及数据、模型下载链接:网盘链接,提取码:8goz
数据集
数据集是THUCnews的,清华大学根据新浪新闻RSS订阅频道2005-2011年间的历史数据筛选过滤生成。总共有体育、财经等共10个类别新闻,筛选出其中的财经类新闻作为训练语料。使用BERT的tokenizer,可以分词也可以不分词。选择分词的话最好根据训练语料提取一份词表,不分词的话可以直接使用原BERT模型提供的词表。GPT-2模型训练要求语料连续,最好是段落或者大文档类不能太短,否则影响模型表现。训练前将语料预处理切分。勾选raw,自动处理语料。
def build_files(data_path, tokenized_data_path, num_pieces, full_tokenizer, min_length):
with open(data_path, 'r', encoding='utf8') as f:
print('reading lines')
lines = json.load(f)
lines = [line.replace('\n', ' [SEP] ') for line in lines] # 用[SEP]表示换行, 段落之间使用SEP表示段落结束
all_len = len(lines)
if not os.path.exists(tokenized_data_path):
os.makedirs(tokenized_data_path)
for i in tqdm(range(num_pieces)):
sublines = lines[all_len // num_pieces * i: all_len // num_pieces * (i + 1)]
if i == num_pieces - 1:
sublines.extend(lines[all_len // num_pieces * (i + 1):]) # 把尾部例子添加到最后一个piece
sublines = [full_tokenizer.tokenize(line) for line in sublines if
len(line) > min_length] # 只考虑长度超过min_length的句子
sublines = [full_tokenizer.convert_tokens_to_ids(line) for line in sublines]
full_line = []
for subline in sublines:
full_line.append(full_tokenizer.convert_tokens_to_ids('[MASK]')) # 文章开头添加MASK表示文章开始
full_line.extend(subline)
full_line.append(full_tokenizer.convert_tokens_to_ids('[CLS]')) # 文章之间添加CLS表示文章结束
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'w') as f:
for id in full_line:
f.write(str(id) + ' ')
print('finish')
模型训练
模型代码使用huggingface提供的GPT-2 model,使用AdamW优化器,warmup2000个step,使用线性衰减,初始学习率设置为1.5e-4,总共训练了5个epoch,大概35K个iteration。
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0,1,2,3', type=str, required=False, help='设置使用哪些显卡')
parser.add_argument('--model_config', default='models/model_config.json', type=str, required=False,
help='选择模型参数')
parser.add_argument('--tokenizer_path', default='models/vocab.txt', type=str, required=False, help='选择词库')
parser.add_argument('--raw_data_path', default='./data/cnews.json', type=str, required=False, help='原始训练语料')
parser.add_argument('--tokenized_data_path', default='data/tokenized/', type=str, required=False,
help='tokenized语料存放位置')
parser.add_argument('--raw', action='store_true', help='是否先做tokenize')
parser.add_argument('--epochs', default=5, type=int, required=False, help='训练循环')
parser.add_argument('--batch_size', default=1, type=int, required=False, help='训练batch size')
parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='学习率')
parser.add_argument('--warmup_steps', default=2000, type=int, required=False, help='warm up步数')
parser.add_argument('--log_step', default=10, type=int, required=False, help='多少步汇报一次loss,设置为gradient accumulation的整数倍')
parser.add_argument('--stride', default=768, type=int, required=False, help='训练时取训练数据的窗口步长')
parser.add_argument('--gradient_accumulation', default=1, type=int, required=False, help='梯度积累')
parser.add_argument('--fp16', action='store_true', help='混合精度')
parser.add_argument('--fp16_opt_level', default='O1', type=str, required=False)
parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False)
parser.add_argument('--num_pieces', default=50, type=int, required=False, help='将训练语料分成多少份')
parser.add_argument('--min_length', default=128, type=int, required=False, help='最短收录文章长度')
parser.add_argument('--output_dir', default='models/cnews', type=str, required=False, help='模型输出路径')
parser.add_argument('--pretrained_model', default='', type=str, required=False, help='模型训练起点路径')
parser.add_argument('--writer_dir', default='runs/', type=str, required=False, help='Tensorboard路径')
parser.add_argument('--segment', action='store_true', help='中文以词为单位')
args = parser.parse_args()
print('args:\n' + args.__repr__())
if args.segment:
from tokenization import tokenization_bert_word_level as tokenization_bert
else:
from tokenization import tokenization_bert
os.environ["CUDA_VISIBLE_DEVICES"] = args.device # 此处设置程序使用哪些显卡
model_config = GPT2Config.from_json_file(args.model_config)
print('config:\n' + model_config.to_json_string())
n_ctx = model_config.n_ctx
full_tokenizer = tokenization_bert.BertTokenizer(vocab_file=args.tokenizer_path)
full_tokenizer.max_len = 999999
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('using device:', device)
raw_data_path = args.raw_data_path
tokenized_data_path = args.tokenized_data_path
raw = args.raw # 选择是否从零开始构建数据集
epochs = args.epochs
batch_size = args.batch_size
lr = args.lr
warmup_steps = args.warmup_steps
log_step = args.log_step
stride = args.stride
gradient_accumulation = args.gradient_accumulation
fp16 = args.fp16 # 不支持半精度的显卡请勿打开
fp16_opt_level = args.fp16_opt_level
max_grad_norm = args.max_grad_norm
num_pieces = args.num_pieces
min_length = args.min_length
output_dir = args.output_dir
assert log_step % gradient_accumulation == 0
if not os.path.exists(output_dir):
os.mkdir(output_dir)
if raw:
print('building files')
build_files(data_path=raw_data_path, tokenized_data_path=tokenized_data_path, num_pieces=num_pieces,
full_tokenizer=full_tokenizer, min_length=min_length)
print('files built')
if not args.pretrained_model:
model = GPT2LMHeadModel(config=model_config)
else:
model = GPT2LMHeadModel.from_pretrained(args.pretrained_model)
model.train()
model.to(device)
num_parameters = 0
parameters = model.parameters()
for parameter in parameters:
num_parameters += parameter.numel()
print('number of parameters: {}'.format(num_parameters))
multi_gpu = False
full_len = 0
print('calculating total steps')
for i in tqdm(range(num_pieces)):
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f:
full_len += len([int(item) for item in f.read().strip().split()])
total_steps = int(full_len / stride * epochs / batch_size / gradient_accumulation)
print('total steps = {}'.format(total_steps))
optimizer = AdamW(model.parameters(), lr=lr, correct_bias=True)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps,
num_training_steps=total_steps)
if fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=fp16_opt_level)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = DataParallel(model, device_ids=[int(i) for i in args.device.split(',')])
multi_gpu = True
print('starting training')
overall_step = 0
total_loss = 0
logging_loss = 0
tb_writer = SummaryWriter(log_dir=args.writer_dir)
for epoch in trange(epochs):
print('epoch {}'.format(epoch + 1))
now = datetime.now()
print('time: {}'.format(now))
x = np.linspace(0, num_pieces - 1, num_pieces, dtype=np.int32)
random.shuffle(x)
for i in x:
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f:
line = f.read().strip()
tokens = line.split()
tokens = [int(token) for token in tokens]
start_point = 0
samples = []
while start_point < len(tokens) - n_ctx:
samples.append(tokens[start_point: start_point + n_ctx])
start_point += stride
if start_point < len(tokens):
samples.append(tokens[len(tokens)-n_ctx:])
random.shuffle(samples)
for step in range(len(samples) // batch_size): # drop last
# prepare data
batch = samples[step * batch_size: (step + 1) * batch_size]
batch_inputs = []
for ids in batch:
int_ids = [int(x) for x in ids]
batch_inputs.append(int_ids)
batch_inputs = torch.tensor(batch_inputs).long().to(device)
# forward pass
outputs = model.forward(input_ids=batch_inputs, labels=batch_inputs)
loss, logits = outputs[:2]
# get loss
if multi_gpu:
loss = loss.mean()
if gradient_accumulation > 1:
loss = loss / gradient_accumulation
# loss backward
if fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
total_loss += loss.item()
# optimizer step
if (overall_step + 1) % gradient_accumulation == 0:
optimizer.step()
optimizer.zero_grad()
scheduler.step()
if (overall_step + 1) % log_step == 0:
scale_loss = (total_loss - logging_loss) / log_step
tb_writer.add_scalar('loss', scale_loss, overall_step)
tb_writer.add_scalar('lr',scheduler.get_lr()[0],overall_step)
print('Step {} epoch {}, loss {}'.format(
overall_step + 1,
epoch + 1,
scale_loss))
logging_loss = total_loss
overall_step += 1
print('saving model for epoch {}'.format(epoch + 1))
if not os.path.exists(os.path.join(output_dir, 'model_epoch{}'.format(epoch + 1))):
os.makedirs(os.path.join(output_dir, 'model_epoch{}'.format(epoch + 1)))
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(os.path.join(output_dir, 'model_epoch{}'.format(epoch + 1)))
# torch.save(scheduler.state_dict(), output_dir + 'model_epoch{}/scheduler.pt'.format(epoch + 1))
# torch.save(optimizer.state_dict(), output_dir + 'model_epoch{}/optimizer.pt'.format(epoch + 1))
print('epoch {} finished'.format(epoch + 1))
then = datetime.now()
print('time: {}'.format(then))
print('time for one epoch: {}'.format(then - now))
print('training finished')
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(output_dir)
模型结果评估
模型loss曲线如下:
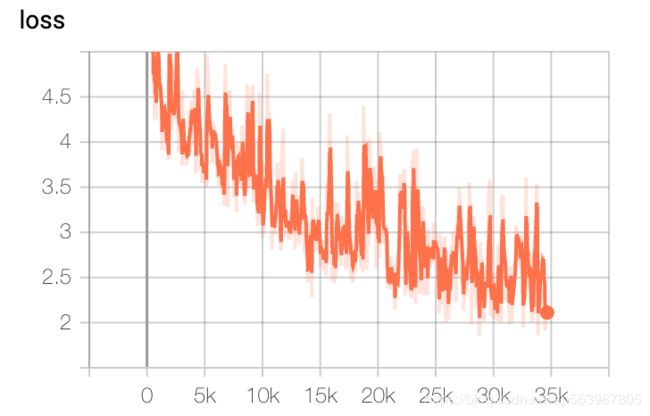 模型生成时提供了top-k以及top-p选择,temperature可调以及repetition_penalty,针对生成时解码较慢的情况,huggingface还贴心的提供了past回传。运行generation.py文件,即可查看模型生成效果:
模型生成时提供了top-k以及top-p选择,temperature可调以及repetition_penalty,针对生成时解码较慢的情况,huggingface还贴心的提供了past回传。运行generation.py文件,即可查看模型生成效果:



分析
基于GPT-2的中文文本生成还有很大很广阔的发展研究空间以及很多任务待解决,其应用领域也很多。