AI取代人类?这4种工作仍将是从业者的“铁饭碗” | 未来

导读:围棋人机大战、人脸识别、自动驾驶、智能控制、语言和图像理解……这些年,人工智能的威力,我们已经见识过太多。“人工智能”甚至入选“2017年度中国媒体十大流行语”。
如今,深度学习结合大数据,让人工智能学习“知识”成为可能。人工智能正在试图拥有一个人类的大脑。那么,在人工智能横行的时代,人类的工作甚至生存的空间又在哪里?
以下观点和案例会告诉你,人类在未来在4个工作领域仍然不可替代,这4项工作也将成为业内的“铁饭碗”。希望本文能够为你的职业规划及发展方向提供帮助。

将从大数据中提取“知识”的工作交给人工智能,但这绝不意味着人类将变得无关紧要。人类需要承担“选择合适方法”等新的任务。让我们来看看人类应发挥的4点作用。
01 进行深层神经网络的内部设计,为人工智能选择合适的机器学习方法
深层学习(Deep Learning)也有缺点,绝不是万能的方法。而且在很多情况下我们使用传统的方法会更加见效。东京大学的原田达也教授作为图像识别技术的研究人员指出:“其中的一个难题就是,关于如何进行深层神经网络的内部设计,目前还没有人能够提出一个明确的设计指南。”
所以人类应该发挥的第一个作用,就是选择合适的机器学习方法。
除了深层学习之外,机器学习的方法还有很多。对很多企业来说,与其一下子就尝试难以驾驭的深层学习,不如引入现有的机器学习方法更具实际意义。
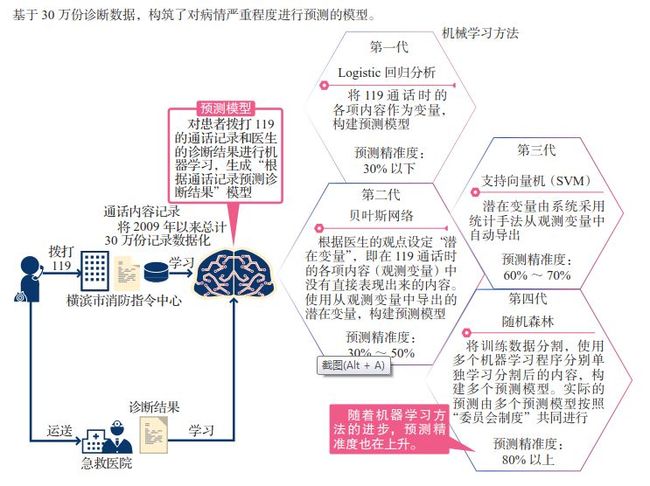
在方法的选择上,我们可以参考横滨国立大学滨上知树教授的做法。横滨市从2008年起开始构建“119紧急电话对紧急程度/病情严重程度的识别(call triage)”预测模型系统,而滨上教授正是负责该项目机器学习的研究人员。
横滨市的call triage指的是从通话内容中预测拨打119电话的患者病情的严重程度,根据具体症状来调整急救人员的种类和规模。因为现在急救人员的人手增加存在困难,如何有效安排就显得非常重要。
这时候最重要的一点就是“不能把重症的患者判断为轻症”(滨上教授)。哪怕允许“把轻症的患者判断为重症”,也绝不允许系统把重症患者判断为轻症。也正因为如此,系统最初的预测精准度还不到30%。
▲横滨市“call triage支援系统”
滨上教授为了提高准确度,始终在更新机器学习的方法。从最初的“logistic回归”分析到“贝叶斯网络”“支持向量机(SVM)”,再到现在的“随机森林”,随着每一次方法的改进,系统的预测精准度都有所提升,现在已经在80%以上。
有意思的一点是,比起在构建预测模型时参考了医生意见的贝叶斯网络,没有参考医生意见的SVM及随机森林的预测精确度反而更高。滨上教授指出:“电脑竟然能比医生更准确地判断患者病情的严重程度,这对一般人来说可能在感情上很难接受。消除这种误解,也是人工智能研究人员的重要任务之一。”
02 找出机器学习和深层学习的适用领域
找出机器学习和深层学习的适用领域,这是人类的第二个作用。通过在各个领域不断尝试机器学习并评估其成效,寻找可以应用的新领域,这种态度是非常重要的。
制药公司过去依靠的是实验和建模方式,而现在它们开始利用机器学习进行新药研发。
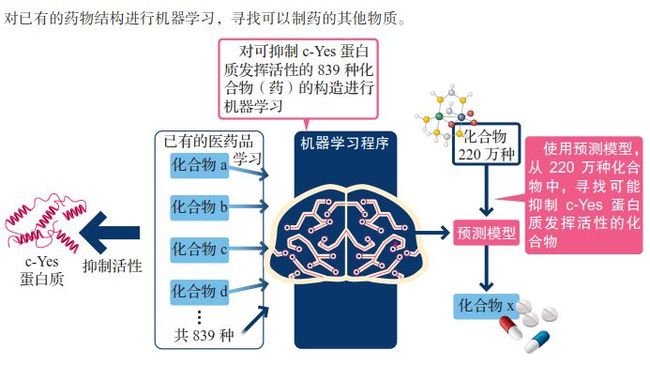
2014年,日本的非营利组织(NPO)“并列生物信息处理Initiative”举办了“用电脑创造制药原料”大赛。在这场大赛中,引进了机器学习的风险企业“信息数理生物”公司拔得了头筹。比赛的主题是从220万种化合物中寻找出拥有某种疗效的、可用于制药的化合物。
▲“信息数理生物”公司研发的“虚拟筛选”系统
在这里需要找出损伤蛋白质活性的化合物,这是造成疾病的原因。目前共有两种方法可以找出这种化合物:①进行真实的实验。②通过电脑建模的方式再现蛋白质和化合物的构造,并据此进行模拟实验。
但是,化合物共有220万种,如果对每一种都进行实验或建模,从成本到时间上都很难做到。该公司根据“结构相似的化合物,其作用也相似”这一生物规则为线索,让电脑“针对现有医药品的结构进行机器学习,寻找结构相似的化合物”(望月正弘)。实践证明,利用这种方法确实找到了有望作为药品发挥作用的化合物。
在素材和材料领域也能看到同样的探索。在“信息材料学”方面,现在正通过机器学习寻找可用于制造超导体及太阳能电池材料、锂离子电池材料的化合物。
03 验证机器提出的假设,思考这些模式和规律产生的原因
人工智能可以从大量数据中找到模式和规律,而思考这些模式和规律产生的原因,从中发现新知识,则是只有人类才能完成的工作。这也是人类的第三个作用。
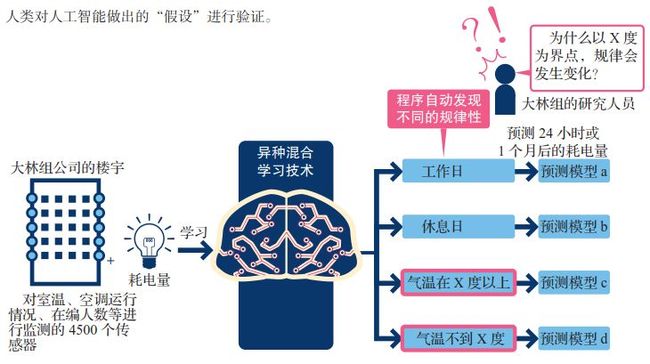
日本大型综合建设公司大林组计划从2014年11月开始启用系统,采用NEC的“异种混合学习”机器学习技术,根据楼宇里安装的4500个传感器提供的数据,对24小时或1个月后楼宇的能源消耗量进行预测。
楼宇的能源消耗模式根据平日、周末和时间段等不同而有所不同。对于具体在什么时间点模式会发生改变这一点,一直以来都是靠人工根据专业知识分出几种不同的情况,再制作出合适的模型进行判断的。
▲大林组公司的楼宇能源消耗预测系统
NEC的异种混合学习则是通过机器学习的方法观察到模式的转换,再根据不同的模式生成模型。传统的预测模型的失误率超过10%,预计导入异种混合学习之后,失误率会降到5%以下。
大林组公司环境解决方案部小野岛一部长说:“今后我们要做的工作就是,了解异种混合学习在什么节点对模式进行切换,找到其背后的原因。”比如异种混合学习分析出以某户外温度值为节点,预测模型会发生切换。“我们要弄明白在超过这个温度时楼宇中的哪些内容会发生改变。通过理清这些因果关系,可能会发现新的节能方法。”
04 收集数据,制定数据收集机制以供人工智能进行学习
只要有数据,人工智能就可以学习,但是如果没有数据,那就什么也做不了。如何制定数据收集机制以供人工智能进行学习,是人类的重要任务,也是人类的第四个作用。
日本SoftBank Mobile公司目前正在推进由SoftBank Robotics研发的人形机器人“Pepper”的推广活动。其目的之一,就是通过Pepper“收集店里接待客人时的相关数据”(SoftBank Robotics PMO室林要主任)。

▲Softbank公司的待客机器人“Pepper”
一直以来,都是由店员在店里承担接待客人的工作。“店员和客人进行沟通以后,顾客有哪些反应”这一类数据完全没有记录下来。
Pepper可以识别顾客声音,理解话语内容,通过对话向客人提供服务。它甚至还可以根据顾客的语音语调判断客人的情绪。通过Pepper的行为,可以收集到有关顾客反应的相关数据。
“要想让‘服务型机器人’在服务行业大显身手,最重要的一点就是收集数据。如果可以大量收集到能够确保一定质量的数据,就可以孕育出新的认知。”林要主任说。
数据收集工作中最难的一点,就在于收集反映人类判断结果的“训练数据”。如果训练数据的收集实在困难,也可以采用“无监督学习”方式。
例如,风险企业Informetis仅仅根据家庭或办公室里一个电流传感器的数据,就通过无监督学习的方式开发了可以分别识别多台机器用电量的“机器分离技术”。该技术的特点在于无须为每一台机器配备电流传感器。
“冰箱、电视、电脑等机器的种类繁多,我们认为很难收集用于识别各类机器的训练数据,也就是反映各机器耗电倾向的数据,所以采用了无监督学习方式。”该公司社长只野太郎介绍说。
哪些数据需要收集,哪些数据能够收集,对这些问题进行判断,正是只有我们人类才能完成的工作。
关于作者:日经计算机,一本写给管理者与领导者的IT综合信息杂志,以链接IT策划、研发、应用为己任。旨在传播“推进商业的IT”信息,让读者能轻松理解策划、研发与应用的综合信息。

本文摘编自《物联网商业时代》
点击“阅读原文”了解及购买本书
转载请联系:[email protected]
点击文末右下角“写留言”发表你的观点
推荐语:有网友评论该书为“未来生活的提前预演”。这是一部全面展示物联网前沿的产业分析手册,物联网并不是时髦的概念,它在悄悄从产业链的上游改变我们的世界。
推荐阅读
日本老爷爷坚持17年用Excel作画,我可能用了假的Excel···
看完此文再不懂区块链算我输:手把手教你用Python从零开始创建区块链
为什么要学数学?因为这是一场战略性的投资
180页PPT,讲解人工智能技术与产业发展
Q: 你找到你的专属“铁饭碗”了吗?
欢迎留言与大家分享
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:[email protected]
更多精彩文章,请在公众号后台点击“历史文章”查看

 点击
阅读原文,了解更多
点击
阅读原文,了解更多