scrapy-redis分布式爬虫的搭建过程(理论篇)
scrapy-redis分布式爬虫的搭建过程(理论篇)
1. 背景
- Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
2. 环境
- 系统:win7
- scrapy-redis
- redis 3.0.5
- python 3.6.1
3. 原理
3.1. 对比一下scrapy 和 Scrapy-redis 的架构图。
scrapy架构图:
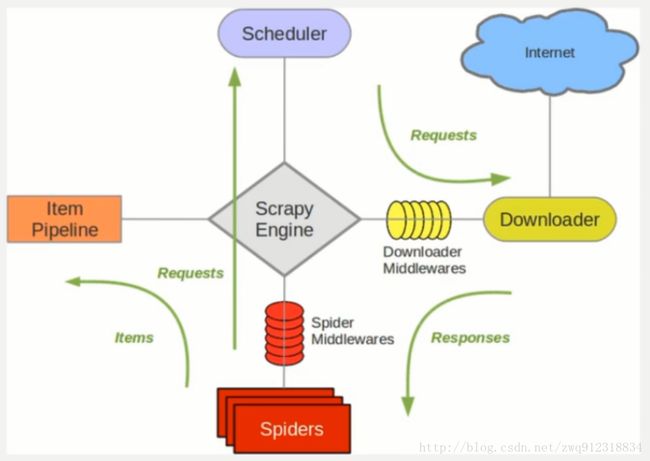
scrapy-redis 架构图:

- 多了一个redis组件,主要影响两个地方:第一个是调度器。第二个是数据的处理。
3.2. Scrapy-Redis分布式策略。

- 作为一个分布式爬虫,是需要有一个Master端(核心服务器)的,在Master端,会搭建一个Redis数据库,用来存储start_urls、request、items。Master的职责是负责url指纹判重,Request的分配,以及数据的存储(一般在Master端会安装一个mongodb用来存储redis中的items)。出了Master之外,还有一个角色就是slaver(爬虫程序执行端),它主要负责执行爬虫程序爬取数据,并将爬取过程中新的Request提交到Master的redis数据库中。
- 如上图,假设我们有四台电脑:A, B, C, D ,其中任意一台电脑都可以作为 Master端 或 Slaver端。整个流程是:
- 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。


Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
4. 运行流程
- 第一步:在slaver端的爬虫中,指定好 redis_key,并指定好redis数据库的地址,比如:
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'amazon'
redis_key = 'amazonCategory:start_urls'# 指定redis数据库的连接参数
'REDIS_HOST': '172.16.1.99',
'REDIS_PORT': 6379,- 第二步:启动slaver端的爬虫,爬虫进入等待状态,等待 redis 中出现 redis_key ,Log如下:
2017-12-12 15:54:18 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapybot)
2017-12-12 15:54:18 [scrapy.utils.log] INFO: Overridden settings: {'SPIDER_LOADER_WARN_ONLY': True}
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2017-12-12 15:54:18 [myspider_redis] INFO: Reading start URLs from redis key 'myspider:start_urls' (batch size: 110, encoding: utf-8
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'redisClawerSlaver.middlewares.ProxiesMiddleware',
'redisClawerSlaver.middlewares.HeadersMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-12-12 15:54:18 [scrapy.middleware] INFO: Enabled item pipelines:
['redisClawerSlaver.pipelines.ExamplePipeline',
'scrapy_redis.pipelines.RedisPipeline']
2017-12-12 15:54:18 [scrapy.core.engine] INFO: Spider opened
2017-12-12 15:54:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-12 15:55:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-12 15:56:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)- 第三步:启动脚本,往redis数据库中填入redis_key(start_urls)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
# 将start_url 存储到redis中的redis_key中,让爬虫去爬取
redis_Host = "172.16.1.99"
redis_key = 'amazonCategory:start_urls'
# 创建redis数据库连接
rediscli = redis.Redis(host = redis_Host, port = 6379, db = "0")
# 先将redis中的requests全部清空
flushdbRes = rediscli.flushdb()
print(f"flushdbRes = {flushdbRes}")
rediscli.lpush(redis_key, "https://www.baidu.com")
- 第四步:slaver端的爬虫开始爬取数据。Log如下:
2017-12-12 15:56:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
parse url = https://www.baidu.com, status = 200, meta = {'download_timeout': 25.0, 'proxy': 'http://proxy.abuyun.com:9020', 'download_slot': 'www.baidu.com', 'download_latency': 0.2569999694824219, 'depth': 7}
parse url = https://www.baidu.com, status = 200, meta = {'download_timeout': 25.0, 'proxy': 'http://proxy.abuyun.com:9020', 'download_slot': 'www.baidu.com', 'download_latency': 0.8840000629425049, 'depth': 8}
2017-12-12 15:57:18 [scrapy.extensions.logstats] INFO: Crawled 2 pages (at 2 pages/min), scraped 1 items (at 1 items/min)- 第五步:启动脚本,将redis中的items,转储到mongodb中。
这部分代码,请参照:scrapy-redis分布式爬虫的搭建过程(代码篇)5. 环境安装以及代码编写
5.1. scrapy-redis环境安装
pip install scrapy-redis
- 代码位置:后面可以进行修改定制。

5.2. scrapy-redis分布式爬虫编写
- 第一步,下载官网的示例代码,地址:https://github.com/rmax/scrapy-redis (需要安装过git)
git clone https://github.com/rmax/scrapy-redis.git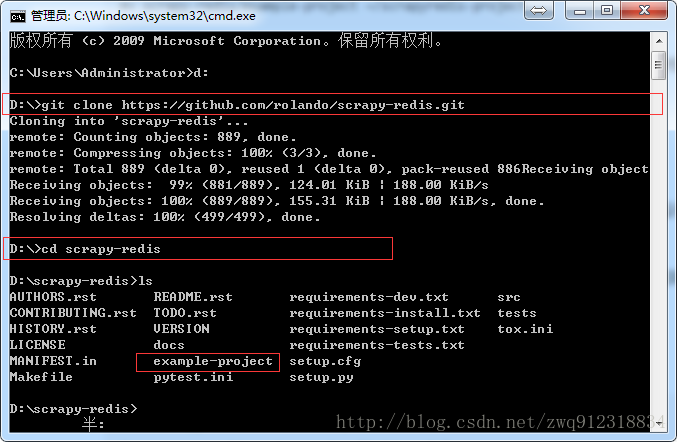
官网提供了两种示例代码,分别继承自 Spider + redis 和 CrawlSpider + redis
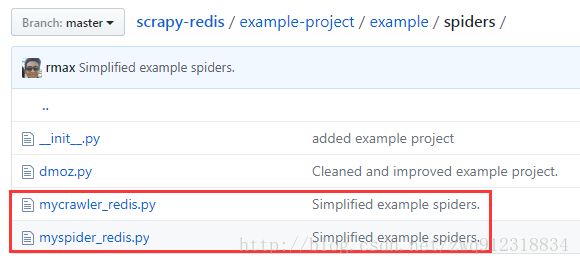
第二步,根据官网提供的示例代码进行修改。