【python与机器学习 5-2】参数调整——交叉验证和网格搜索
模型参数
机器学习中有两种类型的模型参数,分为模型自身参数和超参数
模型自身参数
模型自身参数,通过样本学习得到的参数。
如:逻辑回归及神经网络中的权重及偏置的学习等
超参数
超参数是模型框架的参数,通常由手工设定。
如kmeans中的k,神经网络中的网络层数及每层的节点个数。
调参调的都是k,c这样的超参数。
调整参数
我们知道进行机器学习最重要的就是调整参数得到好的学习模型,这里调整参数指的就是超参数,模型自身的参数是不能调整的。
那么如何调参呢?这就是我们接下来要介绍的东西。
我们可以通过以往进行机器学习的经验进行调参,除此之外还可以依靠实验。也就是先用交叉验证评估模型的好坏,再用网格搜索来选择最优参数。(这里针对多个超参数的情况,当只有一个参数时,直接通过交叉验证就可以进行参数的选择)
依靠经验
有经验的人可以根据经验来调整参数。
交叉验证
我们在进行机器学习的时候,把数据集划分为数据集和测试集,通过数据集训练好的模型再将测试集放上去进行测试可以看出模型好坏。不好再进行调参,重新得到新的模型。
上述过程是用一个测试集来检测模型的好坏的,这样不具有普遍性,现实中在产品上线前我们没有数据来测试模型的好坏,但是可以通过训练集近似的比拟上线后的场景进行测试,如何测试呢?
可是使用交叉验证的方法,通过交叉验证,在产品上线之前可以检测出来学习出来的模型哪个好。
交叉验证的思想是把一份数据随机分成三个部分:训练集(training set)、验证集(validation set)、测试集(test set)。训练集用来训练模型,验证集用于模型的选择,测试集用于最终对学习方法的评估。
以高考为例,训练集就是我们平时做的作业,用于训练自己的能力;验证集就是我们的月考、模拟考,用于检验和反馈自己的能力;测试集就是我们的高考,绝对保密,用于最终告诉你的能力水平(分数);
后来又有了k折交叉验证
注意!!!
交叉验证最后得到的结果是验证集的得分。
交叉验证的例子——5折交叉验证
k折交叉验证其实就是把数据集分成若干份,依次取一份作为测试集其它份作为数据集进行训练,然后取所有的结果平均值作为此模型的结果。
下面以5这交叉验证为例。5折交叉验证就是把数据集分成5份,然后进行5此测试,如model1就是将第一折fold1的数据作为测试集,其余的四份作为数据集。最后每个model都计算出来一个准确度accuracy,求平均后作为此验证集的精确度。

sklearn进行交叉验证——单一超参数
交叉验证得分cross_val_score()
得到每个交叉验证集的score,即准确率
from sklearn.model_selection import cross_val_score
cross_val_score(estimator, X, y=None, cv=None)
参数:
- estimator 训练器的选择,如knn
- X是训练集上的特征
- y是训练集中要预测的标签
- cv是交叉验证分为几折
返回值是每一折得到的准确率也就是个列表,这里的准确率是验证集的准确率
当模型里只有一个超参数时,即单一参数的情况,我们可以直接用交叉验证的结果进行参数的选择。
例子1
我们用knn进行水果识别为例,这里的超参数为k。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
k_range = [2, 4, 5, 10] #k选择2,4,5,10四个参数
cv_scores = [] #分别放用4个参数训练得到的精确度
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#*****下面这句进行了交叉验证**********
scores = cross_val_score(knn, X_train_scaled, y_train, cv=3)#进行3折交叉验证,返回的是3个值即每次验证的精确度
cv_score = np.mean(scores)# 把某个k对应的精确度求平均值
print('k={},验证集上的准确率={:.3f}'.format(k, cv_score))
cv_scores.append(cv_score)验证曲线validation_curve()
验证曲线的横轴为某个超参数的一系列值,由此来看不同参数设置下模型的准确率。从验证曲线上可以看到随着超参数设置的改变,模型可能从欠拟合到合适再到过拟合的过程,进而选择一个合适的设置,来提高模型的性能。
在sklearn中使用的是validation_curve得到验证曲线
sklearn.model_selection.validation_curve(estimator, X, y, param_name, param_range, cv=None, scoring=None)
参数:
- estimator: 训练器
- X: 训练集上选择的特征
- y:训练集上的要预测值
- param_name :变化的参数的名称
- param_range : 参数变化的范围
- cv:交叉验证的折数
- scoring:采用的模型评价标准
下面是官网给出的此公式的介绍:
Determine training and test scores for varying parameter values.
Compute scores for an estimator with different values of a specified parameter. This is similar to grid search with one parameter. However, this will also compute training scores and is merely a utility for plotting the results.
翻译为:
当某个参数不断变化是,在每一个取值上计算出的模型在训练集和测试集上的得分。在一个不断变化的参数上计算学习器的得分,类似于只有一个参数的网格搜索,但是这个函数也会计算训练集上的得分。
下面举一个例子:
例子2
通过SVM的超参数C,调用 验证曲线validation_curve 绘制超参数对训练集和验证集的影响
1.导入validation_curve和SVC
import matplotlib.pyplot as plt
from sklearn.model_selection import validation_curve
from sklearn.svm import SVC2.确定超参数的选择范围,求验证曲线
c_range = [1e-3, 1e-2, 0.1, 1, 10, 100, 1000, 10000] #C的取值范围
train_scores, test_scores = validation_curve(SVC(kernel='linear'), X_train_scaled, y_train, param_name='C', param_range=c_range, cv=5, scoring='accuracy')# 通过验证曲线得到不同取值的C在验证集合训练集上的得分。3.根据验证曲线的返回值求出不同C在每一折验证集和训练集上的得分的平均值和标准差
train_scores_mean = np.mean(train_scores, axis=1)# 对每一个参数C,他通过5折交叉验证后都会得到5个得分,这里就是把这5个得分求均值。求得的均值用于接下来的绘制每个参数的取值对应的得分。
train_scores_std = np.std(train_scores, axis=1) #求标准差是为了画出它的置信区间
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)4.绘图
plt.figure(figsize=(10, 8))
plt.title('Validation Curve with SVM')
plt.xlabel('C')
plt.ylabel('Score')
plt.ylim(0.0, 1.1)
lw = 2
plt.semilogx(c_range, train_scores_mean, label="Training score",
color="darkorange", lw=lw)
plt.fill_between(c_range, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.2,
color="darkorange", lw=lw) #画出置信区间
plt.semilogx(c_range, test_scores_mean, label="Cross-validation score",
color="navy", lw=lw)
plt.fill_between(c_range, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.2,
color="navy", lw=lw)
plt.legend(loc="best")
plt.show()结果:
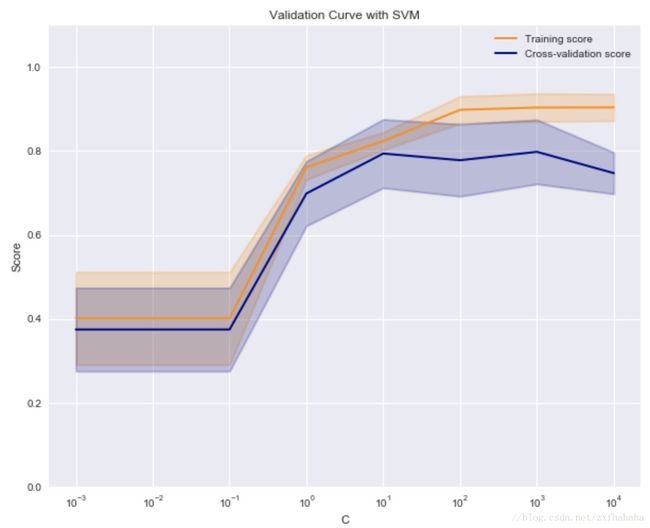
如图是 SVM 在不同的C值时,它在训练集和交叉验证上的分数:
C 很小时,训练分数和验证分数都很低,为欠拟合。
C 逐渐增加,两个分数都较高,此时模型相对不错。
C太高时,训练分数高,验证分数低,学习器会过拟合。
本例中,可以选验证集准确率开始下降,而测试集越来越高那个转折点作为 C的最优选择。
网格搜索
我们知道交叉验证用于评估模型的好坏,超参数为1时可以直接根据交叉验证的结果选择最优的参数。但是,超参数多余1时就要用到网格搜索。
什么是网格搜索
网格搜索法算法就是通过交叉验证的方法去寻找最优的模型参数。详细点说就是模型的每个参数有很多个候选值,我们每个参数组合做一次交叉验证,最后得出交叉验证分数最高的,就是我们的最优参数。
网格搜索存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。
sklearn使用网格搜索
sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)
参数:
- estimator 训练器
- param_grid 多个超参数的值,字典形式
- scoring 评价标准
- cv 采用几折交叉验证
返回给定参数的最好组合
得到网格搜索的结果cv_results_
clf.cv_results_ #得到的结果是所有参数的键值对,clf是网格搜索的返回值
获取最优模型best_estimator_
clf.best_estimator_
获取最优参数best_params_
clf.best_params_
获取验证集的最高得分clf.best_score_
clf.best_score_
使用网格搜索对对个超参数选择的例子
#调用网格搜索和决策树
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
parameters = {'max_depth':[3, 5, 7, 9], 'min_samples_leaf': [1, 2, 3, 4]}# 选择两个超参数 树的深度max_depth和叶子的最小值min_samples_leaf
clf = GridSearchCV(DecisionTreeClassifier(), parameters, cv=3, scoring='accuracy')# 进行网格搜索得到最优参数组合
clf.fit(X_train, y_train) #通过有最优参数组合的最优模型进行训练
print('最优参数:', clf.best_params_)
print('验证集最高得分:', clf.best_score_)
# 获取最优模型
best_model = clf.best_estimator_
print('测试集上准确率:', best_model.score(X_test, y_test))