利用协同过滤算法的皮尔逊系数:计算歌曲相似度
想要什么
数据已经足够多了,我现在想法就是单独维护一张歌曲相似度的表,每首歌曲有10首相似度歌曲,并且有相似度的程度,介于0到1之间。
首先来明确我有什么,我有3张表。
- user表:用户1.4万左右
- music表:10万首歌曲记录(只针对中文歌曲)
- favorites表:888153条,收藏记录。表内也就是一个用户ID和一个歌曲ID
理由有:
- 业界实例,豆瓣电台的中文歌曲才8000多首
- 大多数歌曲也许只被收藏了一次或者两次,看下图:
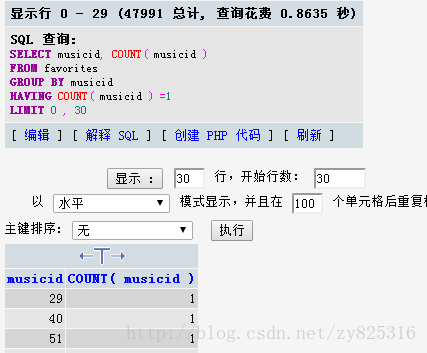
被收藏了一次的歌曲就有47991条。几乎快占到了一半了吧?还不说要2次、3次的,2次、3次的意义也不大(这句话貌似有问题哦,因为如果出现了2次的话,那么说明有两个用户收藏了这一首歌,如果这首歌是冷门的歌曲的话,这极大的说明了两个用户的相似,这可以用来应对,某一个用户听的歌曲都比较冷门,在我们预先算好的相似度歌单里面没有太多他收藏的歌曲信息,那么我们可以再利用他的冷门歌曲找到相似用户,产生推荐歌曲列表)。
ok,说了缘由之后,我打算建立的维护的歌曲相似度表的歌曲数量大约在1万首,所以最后是一个10个条目的表。1万首歌曲当然是被用户收藏最多的歌曲。当然这个也是可以商量的,被收藏的最多,一个方面也说明了歌曲的热门程度,另一方面也更容易计算出用户的相似度。
失败的思路
先确定用户
所以,最终,我决定使用收藏歌曲在100到300之间的用户(被这1789位用户),如下图所示:
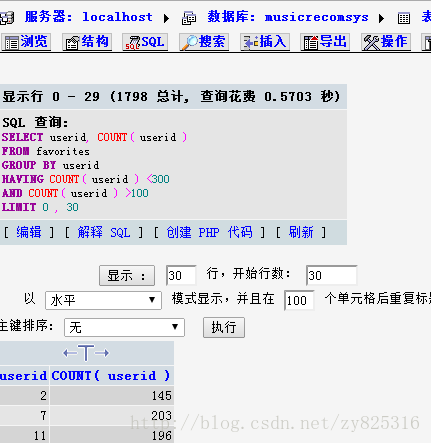
由于我边写博客边抓数据,所以实际数字还在不断的增加。
利用这些用户收藏的歌曲,来计算收藏了的歌曲的相似度。我相信能被这1789用户收藏了的歌曲应该比较普遍的歌曲,不是冷门的。我现在被这1789位用户收藏了的歌曲总共有多少首,但是这条sql语句还比较难哦。由于favorites那张表的数据已经够多了,所以复制了一张字表,该表内的内容是:收藏歌曲在100到300之间的用户的收藏记录。
sql语句如下:
CREATE TABLE smallFavorites SELECT *
FROM (
SELECT *
FROM favorites, (
SELECT userid AS uid
FROM favorites
GROUP BY userid
HAVING COUNT( userid ) >100
AND COUNT( userid ) <300
)a
WHERE favorites.userid = a.uid
)b再确定歌
我查看一下有多少歌,sql语言:
SELECT musicid, COUNT( musicid ) , music.name
FROM smallfavorites
INNER JOIN music ON musicid = music.id
GROUP BY musicid
ORDER BY COUNT( musicid ) DESC 我发现居然有6万多少歌。而且可以得到一些有趣的结果:原来很多人都喜欢:我的歌声里

我们必须要淘汰歌曲,首当其冲的就是只被收藏了一次的歌曲,因为这些歌曲是否有意义值得探讨。我简单的想了一下,是否存在意义的关键在于,计算相似度的方式。
如下所示一个简单的例子,用户A、B,收藏歌曲的情况a、b
a b
A 0 1
B 1 0
计算相似度的方式:如果使用皮尔逊公式计算,肯定就有意义,因为两者兴趣完全相背离。会出现相似度为-1的情况,但是如果用Tanimoto来计算,必须为0,因为两者交集为0。
不过这一次,我决定还是不删除了。当然如果计算速度太慢了,删除了先得到结果。现在虽然有6万多首歌,但是最后我将会选出1万首保留在相似度的表内。
数据以字典形式存在
#一个字典,第一个key是人名,value是又是一个字典,字典里面是key歌曲名,value是否收藏,收藏了为1,没收藏为0
critics={'Lisa Rose': {'Lady in the Water': 0, 'Snakes on a Plane': 1,
'Just My Luck': 0, 'Superman Returns': 0, 'You, Me and Dupree': 1,
'The Night Listener': 1},
'Gene Seymour':{'Lady in the Water': 0, 'Snakes on a Plane': 1,
'Just My Luck': 1, 'Superman Returns': 0, 'You, Me and Dupree': 1,
'The Night Listener': 0},
'Michael Phillips': {'Lady in the Water': 0, 'Snakes on a Plane': 1,
'Just My Luck': 1, 'Superman Returns': 0, 'You, Me and Dupree': 1,
'The Night Listener': 0},
'Claudia Puig': {'Lady in the Water': 0, 'Snakes on a Plane': 1,
'Just My Luck': 1, 'Superman Returns': 0, 'You, Me and Dupree': 0,
'The Night Listener': 1},
'Mick LaSalle': {'Lady in the Water': 1, 'Snakes on a Plane': 0,
'Just My Luck': 1, 'Superman Returns': 1, 'You, Me and Dupree': 1,
'The Night Listener': 1},
'Jack Matthews': {'Lady in the Water': 0, 'Snakes on a Plane': 0,
'Just My Luck': 0, 'Superman Returns': 1, 'You, Me and Dupree': 1,
'The Night Listener': 1},
'Toby': {'Lady in the Water': 1, 'Snakes on a Plane': 1,
'Just My Luck': 0, 'Superman Returns': 1, 'You, Me and Dupree': 0,
'The Night Listener': 0}} 失败原因:数据太大,内存不足
所以下面的重点是如何,把smallfavorites的数据导入内存,以字典的形式。
首先和数据库进行连接,在windows需要使用:MySQL-python-1.2.3.win32-py2.7.exe安装模板,进而来连接数据库。
本来打算原封不动的使用6w多首歌和1800列用户的数据,结果数据太大了,用python跑要内存崩溃。现在只有删一次数据了,把收藏了只有一次的歌曲全部删了。同时,也使我考虑到,选择前收藏最多的前1万首歌曲,再把收藏了这些歌曲的用户全部召集起来,这些用户未必只收藏这1万首歌曲之内的歌曲吧。那样其他歌曲就当不存在。也可以,我先跑这个吧。
尝试解决:减少歌曲数
创建一个新表,所有收藏次数大于1的都被保留,但这样一句sql也会跑非常久。
CREATE TABLE copysmallFavorites SELECT *
FROM (
SELECT *
FROM smallFavorites,(
SELECT musicid AS mid
FROM smallFavorites
GROUP BY musicid
HAVING COUNT( musicid ) >1
)a
WHERE smallFavorites.musicid = a.mid
)b 删除表中只被收藏一次的歌曲。
mysql中不能这么用。 (等待mysql升级吧)
错误提示就是说,不能先select出同一表中的某些值,再update这个表(在同一语句中)
替换方案,创建临时表,将收藏次数为1的给单独放在一张临时表内:
CREATE TABLE tmp SELECT *
FROM (
SELECT *
FROM smallFavorites,(
SELECT musicid AS mid
FROM smallFavorites
GROUP BY musicid
HAVING COUNT( musicid ) =1
)a
WHERE smallFavorites.musicid = a.mid
)b 再删除
delete from smallfavorites where musicid in (select mid from tmp)下一句话跑了12个小时,最后也没有成功,而且内存还占用内存还越来越少。实在没想通就放弃了。
成功的思路
先确定歌曲
由于某些记录确实要跑非常久,我觉得放弃先确定用户,再确定歌曲的思路,改为先确定歌曲,再确定用户,这样方便我觉得了歌曲的范围。
注意,在限制返回结果的个数的时候不要用top,mysql应该是不支持top,但是就使用limit
所有收藏了前10000首歌曲的收藏记录,将其创建在一张新表中,moresmallFavorites。
由于moresmallFavorites是以favorites为父表创建的,所以与smallFavorites是没有关系的。
CREATE TABLE moresmallFavorites SELECT *
FROM (select * from favorites,
(SELECT musicid as mid
FROM favorites
GROUP BY musicid
ORDER BY COUNT( musicid ) DESC
LIMIT 10000
) a where favorites.musicid=a.mid
) b再确定用户
来看看这里有多少用户:SELECT userid, COUNT( userid )
FROM moresmallfavorites
GROUP BY userid
ORDER BY COUNT( userid ) DESC如下查询:
SELECT userid
FROM moresmallfavorites
GROUP BY userid
having COUNT( userid ) >80
and COUNT( userid ) <500为此,我们再建立一张新表,保存这1800个用户的所有收藏记录。sql如下:
CREATE TABLE mostsmallFavorites SELECT *
FROM (
SELECT *
FROM moresmallfavorites, (
SELECT userid AS uid
FROM moresmallfavorites
GROUP BY userid
HAVING COUNT( userid ) >80
AND COUNT( userid ) <500
)a
WHERE moresmallfavorites.userid = a.uid
)b计算相似用户
yes!!现在成功读表入内存,并且我实验了一下,成功计算了一个用户的相似用户,代码如下:import MySQLdb
import copy
def getDataFromMySqlRowIsUser():
#一个字典,第一个key是用户id,value是又是一个字典,字典里面是key歌的id,value是0/1,表示未收藏、收藏
critics={}
try:
#下一句是连好数据库
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306)
#用拿到执行sql语句的对象
cur1=conn.cursor()
cur2=conn.cursor()
#返回用户名的id作为行
count1=cur1.execute('SELECT userid FROM mostsmallfavorites GROUP BY userid')
#返回歌曲的id作为列
count2=cur2.execute('SELECT musicid FROM mostsmallfavorites GROUP BY musicid')
results1=cur1.fetchall()
results2=cur2.fetchall()
#初始化列表,拿到行列的id之后,先全部至为0
temp=dict([(r2[0],0)for r2 in results2])#先制作列
#critics=dict([(r1[0],temp)for r1 in results1])#错误句,这样是浅拷贝,实际上拷贝了一个指针,指向内存中同一个地址
critics=dict([(r1[0],copy.deepcopy(temp))for r1 in results1])#再制作行。这是深拷贝,另开辟一个内存空间
count=cur1.execute('select * from mostsmallfavorites')
results1=cur1.fetchall()
for r1 in results1:
critics[r1[1]][r1[2]]=1
conn.commit()#conn.commit()这句来提交事务,要不然不能真正的插入数据,暂时不清楚这句在查询中有什么用
cur1.close()
cur2.close()
conn.close()
return critics
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])计算相似歌曲
计算用户相似度没问题的话,下面就是计算物品相似度,并且要将计算结果插入数据库,那么就告一段落了。但是当考虑计算一首歌曲的相似歌曲的时候,需要进行行列置换,但矩阵的转换太费时间了,我试了一下,如果1800用户,10000首歌曲,以用户为行需要读1分钟左右。这个时间还可以忍受,我觉得还是从数据库读数据的时候就直接以歌曲为行比较好。所以,我再写一个函数,直接产生以歌为行,以用户为列的数据。其实非常简单,只改变了三行代码:
temp=dict([(r1[0],0)for r1 in results1])#先制作列
critics=dict([(r2[0],copy.deepcopy(temp))for r2 in results2])#再制作行。这是深拷贝,另开辟一个内存空间
critics[r1[2]][r1[1]]=1def getDataFromMySqlRowIsMusic():
#一个字典,第一个key是用户id,value是又是一个字典,字典里面是key歌的id,value是0/1,表示未收藏、收藏
critics={}
try:
#下一句是连好数据库
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306)
#用拿到执行sql语句的对象
cur1=conn.cursor()
cur2=conn.cursor()
#返回用户名的id作为行
count1=cur1.execute('SELECT userid FROM mostsmallfavorites GROUP BY userid')
#返回歌曲的id作为列
count2=cur2.execute('SELECT musicid FROM mostsmallfavorites GROUP BY musicid')
results1=cur1.fetchall()
results2=cur2.fetchall()
#初始化列表,拿到行列的id之后,先全部至为0
temp=dict([(r1[0],0)for r1 in results1])#先制作列
#critics=dict([(r1[0],temp)for r1 in results1])#错误句,这样是浅拷贝,实际上拷贝了一个指针,指向内存中同一个地址
critics=dict([(r2[0],copy.deepcopy(temp))for r2 in results2])#再制作行。这是深拷贝,另开辟一个内存空间
count=cur1.execute('select * from mostsmallfavorites')
results1=cur1.fetchall()
for r1 in results1:
critics[r1[2]][r1[1]]=1
conn.commit()#conn.commit()这句来提交事务,要不然不能真正的插入数据,暂时不清楚这句在查询中有什么用
cur1.close()
cur2.close()
conn.close()
return critics
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])接着,我写了一个函数,完成了一下功能:从数据库拿到以歌名为行,以用户为列的矩阵,然后计算歌曲相似度,然后取前10名,插入到数据库的simmusic表,
由于以后要计算很多歌曲的相似表(不同的语言、不同的相似度计算方式),要注意这张表是在win7平台,用python计算,使用的相似度计算方式是:sim_pearson。
表包括:
- id:自增长
- musicid:歌曲id
- simmusicid:相似歌曲的id
- similarity:相似的程度,一个float型小数。
def insertDataToDB():
try:
print '开始拿歌曲数据'
simmusics=getDataFromMySqlRowIsMusic()#拿到以用歌曲id为行的数据
print '已经拿到数据'
#下一句是连好数据库
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306)
#用拿到执行sql语句的对象
cur1=conn.cursor()
cur2=conn.cursor()
#返回歌曲的id作为列
count2=cur2.execute('SELECT musicid FROM mostsmallfavorites GROUP BY musicid')
results2=cur2.fetchall()
simNumber=10#保留多少首相似的歌曲
flag=0
for r2 in results2:
flag+=1
print (count2-flag)#打印一下剩余多少歌曲
simForOneMusic=topMatches(simmusics,r2[0],n=simNumber,similarity=sim_pearson)
for i in range(simNumber):
cur1.execute("INSERT INTO simmusic(musicid,simmusicid,similarity) VALUES (%s,%s,%s)",[r2[0],simForOneMusic[i][1],simForOneMusic[i][0]])
conn.commit()#必须要有这个提交事务,否则不能正确插入
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])结果:成功!
该代码一共大约运行了4天,从大年初一凌晨3点开始到大年初4我早上醒来已经结束。由于这次是使用python代码跑的,所以才会那么慢。
我执行以下sql可以查询到一个首歌的相似歌:
先找到歌曲的Id,比如刘惜君的怎么唱情歌。
先找到歌曲ID
SELECT *
FROM `music`
WHERE name = '怎么唱情歌'在返回的列表中,识别出id号,如果只给出歌名的话,会发现会有几首歌。
将下面这句sql的****部分改为识别出的歌曲id号即可。
SELECT music.name,music.singer,similarity
FROM (select * from simmusic where musicid = ****) a
INNER JOIN music
WHERE a.simmusicid = music.id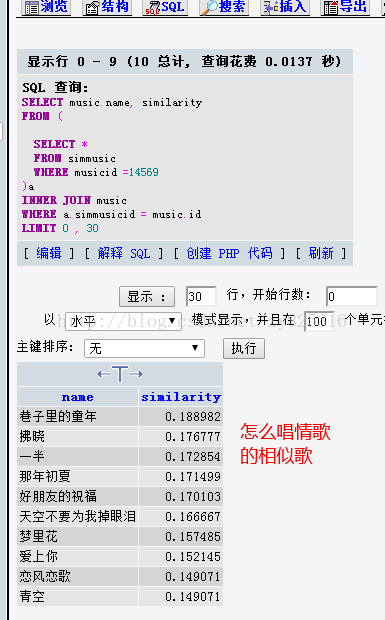
进一步研究的方向
使相似度更准
很显然,歌曲之间相似度虽然有了,而且还是比较有意义,请老婆和老婆哥哥试了一下,还是比较准得。过程就是他们给我一首歌名,我把相似的10首歌给他们就好了。然后他们试听了一下,反应不错。但是这个相似度肯定可以改进的,比如利用歌单系统或者标签系统。比如,两首歌曲有同样的标签的话,相似度度肯定是要增加的,如果两首歌同时出现在一个歌单内,我认为相似度也应该有所增加,因为歌单本身就是一个人为的对歌曲的一种兴趣的聚类。另外一种增加歌曲相似度的办法就是:改变相似度的算法,除了经常使用的相似度的算法之外,我觉得我可以试着改进。
如何验证我的相似度计算的好?
离线计算:还好我手上我有大量的用户数据。我认为就可以利用大量用户数量作离线计算,原理也非常简单:我把某个用户,这个用户当然不是我用来计算歌曲相似度里面的用户,把这个用户收藏的歌里面随机删掉10个,然后给这个用户推荐10个,看这个10个里面有多少个之前删除了的10个歌曲。有一篇论文的方式大概也是这样的。当然,由于用户非常多,所以,我也应该有所筛选。比如收藏歌曲数量为多少的,还有他收藏的歌曲必须尽可能在的我计算了相似度的一万首歌曲内。用户调查:之前还想了想用,用用户调查,现在发现为时过早。而且貌似我给他们找了相似的10首歌,但是他们也不一定知道这10首歌。基于这个原因,无法让他们做出立刻的判断的话,我觉得就比较麻烦。
python计算的速度太慢
这次计算了4天,才把这一万首歌曲的相似度计算出来。下一步我认为我要在linux环境下用c/c++完全这些计算过程,也可以试着用java来计算一次,看看java的速度和python的计算速度相差多少。此外:也要学着使用hadoop来解决这个问题,虽然现在没有很多机子让我实现分布式,但是学习其技术是必然的。
全部源代码
是根据之前的:MyRecommendation for music.py改出来的,可以参考我的博客,所以和那个很像,只是多了3个从数据库读数据和讲算出来的数据插入到数据的三个函数而已。# -*- coding: cp936 -*-
import MySQLdb
import copy
def getDataFromMySqlRowIsMusic():
#一个字典,第一个key是用户id,value是又是一个字典,字典里面是key歌的id,value是0/1,表示未收藏、收藏
critics={}
try:
#下一句是连好数据库
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306)
#用拿到执行sql语句的对象
cur1=conn.cursor()
cur2=conn.cursor()
#返回用户名的id作为行
count1=cur1.execute('SELECT userid FROM mostsmallfavorites GROUP BY userid')
#返回歌曲的id作为列
count2=cur2.execute('SELECT musicid FROM mostsmallfavorites GROUP BY musicid')
results1=cur1.fetchall()
results2=cur2.fetchall()
#初始化列表,拿到行列的id之后,先全部至为0
temp=dict([(r1[0],0)for r1 in results1])#先制作列
#critics=dict([(r1[0],temp)for r1 in results1])#错误句,这样是浅拷贝,实际上拷贝了一个指针,指向内存中同一个地址
critics=dict([(r2[0],copy.deepcopy(temp))for r2 in results2])#再制作行。这是深拷贝,另开辟一个内存空间
count=cur1.execute('select * from mostsmallfavorites')
results1=cur1.fetchall()
for r1 in results1:
critics[r1[2]][r1[1]]=1
conn.commit()#conn.commit()这句来提交事务,要不然不能真正的插入数据,暂时不清楚这句在查询中有什么用
cur1.close()
cur2.close()
conn.close()
return critics
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
def getDataFromMySqlRowIsUser():
#一个字典,第一个key是用户id,value是又是一个字典,字典里面是key歌的id,value是0/1,表示未收藏、收藏
critics={}
try:
#下一句是连好数据库
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306)
#用拿到执行sql语句的对象
cur1=conn.cursor()
cur2=conn.cursor()
#返回用户名的id作为行
count1=cur1.execute('SELECT userid FROM mostsmallfavorites GROUP BY userid')
#返回歌曲的id作为列
count2=cur2.execute('SELECT musicid FROM mostsmallfavorites GROUP BY musicid')
results1=cur1.fetchall()
results2=cur2.fetchall()
#初始化列表,拿到行列的id之后,先全部至为0
temp=dict([(r2[0],0)for r2 in results2])#先制作列
#critics=dict([(r1[0],temp)for r1 in results1])#错误句,这样是浅拷贝,实际上拷贝了一个指针,指向内存中同一个地址
critics=dict([(r1[0],copy.deepcopy(temp))for r1 in results1])#再制作行。这是深拷贝,另开辟一个内存空间
count=cur1.execute('select * from mostsmallfavorites')
results1=cur1.fetchall()
for r1 in results1:
critics[r1[1]][r1[2]]=1
conn.commit()#conn.commit()这句来提交事务,要不然不能真正的插入数据,暂时不清楚这句在查询中有什么用
cur1.close()
cur2.close()
conn.close()
return critics
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
def insertDataToDB():
try:
print '开始拿歌曲数据'
simmusics=getDataFromMySqlRowIsMusic()#拿到以用歌曲id为行的数据
print '已经拿到数据'
#下一句是连好数据库
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306)
#用拿到执行sql语句的对象
cur1=conn.cursor()
cur2=conn.cursor()
#返回歌曲的id作为列
count2=cur2.execute('SELECT musicid FROM mostsmallfavorites GROUP BY musicid')
results2=cur2.fetchall()
simNumber=10#保留多少首相似的歌曲
flag=0
for r2 in results2:
flag+=1
print (count2-flag)#打印一下剩余多少歌曲
simForOneMusic=topMatches(simmusics,r2[0],n=simNumber,similarity=sim_pearson)
for i in range(simNumber):
cur1.execute("INSERT INTO simmusic(musicid,simmusicid,similarity) VALUES (%s,%s,%s)",[r2[0],simForOneMusic[i][1],simForOneMusic[i][0]])
conn.commit()#必须要有这个提交事务,否则不能正确插入
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
from math import sqrt
#利用欧几里得计算两个人之间的相似度
def sim_distance(prefs,person1,person2):
#首先把这个两个用户共同拥有评过分电影给找出来,方法是建立一个字典,字典的key电影名字,电影的值就是1
si={}
for item in prefs[person1]:
if item in prefs[person2]:
si[item]=1
#如果亮着没有共同之处
if len(si)==0:return 0
#计算所有差值的平方和
sum_of_squares=sum([pow(prefs[person1][item]-prefs[person2][item],2) for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sqrt(sum_of_squares))
#返回两个人的皮尔逊相关系数
def sim_pearson(prefs,p1,p2):
si={}
for item in prefs[p1]:
if item in prefs[p2]: si[item]=1
#得到列表元素的个数
n=len(si)
#如果两者没有共同之处,则返回0
if n==0:return 1
#对共同拥有的物品的评分,分别求和
sum1=sum([prefs[p1][it] for it in si])
sum2=sum([prefs[p2][it] for it in si])
#求平方和
sum1Sq=sum([pow(prefs[p1][it],2)for it in si])
sum2Sq=sum([pow(prefs[p2][it],2)for it in si])
#求乘积之和
pSum=sum([prefs[p1][it]*prefs[p2][it] for it in si])
#计算皮尔逊评价值
num=pSum-(sum1*sum2/n)
den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
if den == 0:return 0
r=num/den
return r
def tanimoto(a,b):
c=[v for v in a if v in b]
return float(len(c))/(len(a)+len(b)-len(c))
#针对一个目标用户,返回和其相似度高的人
#返回的个数N和相似度的函数可以选择
def topMatches(prefs,person,n=5,similarity=sim_pearson):
scores=[(similarity(prefs,person,other),other)for other in prefs if other != person]
scores.sort()
scores.reverse()
return scores[0:n]
#利用所有人对电影的打分,然后根据不同的人的相似度,预测目标用户对某个电影的打分
#所以函数名叫做得到推荐列表,我们当然会推荐预测分数较高的电影
#该函数写的应该是非常好,因为它我们知道的业务逻辑不太一样,但是它确实非常简单的完成任务
def getRecommendations(prefs,person,similarity=sim_pearson):
totals={}
simSums={}
for other in prefs:
#不用和自己比较了
if other==person:continue
sim=similarity(prefs,person,other)
#忽略相似度为0或者是小于0的情况
if sim<=0:continue
for item in prefs[other]:
#只对自己还没看过的电影进行评价
if item not in prefs[person] or prefs[person][item]==0:
#相似度*评价值。setdefault就是如果没有就新建,如果有,就取那个item
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
#相似度之和
simSums.setdefault(item,0)
simSums[item]+=sim
#建立一个归一化的列表,这哪里归一化了?这不是就是返回了一个列表吗
rankings=[(total/simSums[item],item)for item,total in totals.items()]
#返回好经过排序的列表
rankings.sort()
rankings.reverse()
return rankings
#将用户对电影的评分改为,电影对用户的适应度
def transformprefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
#将把用户打分,赋值给电影的适应度
result[item][person]=prefs[person][item]
return result
def calculateSimilarItems(prefs,n=10):
#建立相似物品的字典
result={}
#把用户对物品的评分,改为物品对用户的适应度
itemPrefs=transformprefs(prefs)
c=0
for item in itemPrefs:
c+=1
if c%100==0:print "%d / %d " %(c,len(itemPrefs))
#寻找相近的物品
scores=topMatches(itemPrefs,item,n=n,similarity=sim_distance)
result[item]=scores
return result
def getRecommendedItems(prefs,itemSim,user):
userRatings=prefs[user]
scores={}
totalSim={}
#循环遍历由当前用户评分的物品
for (item,rating) in userRatings.items():
#循环遍历与当前物品相近的物品
for (similarity,item2) in itemSim[item]:
#如果该用户已经对当前物品已经收藏,则将其忽略
if prefs[user][item2]==1:continue
#打分和相似度的加权之和
scores.setdefault(item2,0)
scores[item2]+=similarity*rating
#某一电影的与其他电影的相似度之和
totalSim.setdefault(item2,0)
totalSim[item2]+=similarity
#将经过加权的评分除以相似度,求出对这一电影的评分
rankings=[(score/totalSim[item],item) for item,score in scores.items()]
#排序后转换
rankings.sort()
rankings.reverse()
return rankings备份了数据库,已上传至网盘,名为:BACKUPmusicrecomsys2014-2-8.sql