基于水色图象的水质分类问题(傻瓜式工具TPOT)
基于水色图象的水质分类问题(傻瓜式工具TPOT)
这个东西,我看了很多人也做过,也是一个经典的案例,大部分都用的SVM支持向量机或者是决策树要么就是随机森林,这里我看数据量不大,我突然觉得好像TPOT这个东西可以用来玩一玩。
图片处理的流程(基于颜色矩的图片特征提取)
1.将图片的文件批量导入到工作环境中(此部分需要用到循环导数据的方法)
2.将图片进行裁剪,提取出最主要的部分(因为原始图片有许多的干扰部分,可能会干扰后续的处理)
3.计算图片的RGB颜色通道的1,2,3阶矩
4.处理得到的1,2,3阶矩的数据,得到一个数据框
5.建立合适的模型
6.评估模型,修改模型
1、看一眼数据
网盘链接
6o85

都是图片,而且图片的噪音还很大。嘶~
2、对图片的处理,特征的提取
先导入数据吧:
import os
from PIL import Image
import numpy as np
import pandas as pd
name=os.listdir('C:\\Users\\dell\\Desktop\\images')###得到文件夹下的图片名字
label=[]
image=[]
for i in range(len(name)):
a=name[i].split('_')
label.append(a[0])###因为观察到图片的名字已经分好类别了,所以将其用一个列表形式存储起来,以便于后面和表
image.append('C:\\Users\\dell\\Desktop\\images\\'+name[i])###将每个图片的路径得到
对图片进行剪裁,这里是选用图片中间100*100的区域进行裁剪,结果如下:

至于颜色距的计算,大家可以百度,其实简单来说,一张彩色图片是每一个像素组成的,每一个元素都有(R,G,B)这样的RGB值然后,颜色有3个阶矩,分别是R,G,B通道的每一个通道的像素值的均值,方差,梯度,也就是说一共有9个值,R通道3个颜色矩,G3个,B也3个。也就是一张图上的每一个像素都是类似于(111,111,222)、(541,568,214)…这样的像素值,然后进行计算就可以了。具体代码如下:
data=pd.DataFrame(np.zeros((len(image),10)),
columns=['类别','R通道一阶矩','G通道一阶矩','B通道一阶矩','R通道二阶矩','G通道二阶矩','B通道二阶矩','R通道三阶矩','G通道三阶矩','B通道三阶矩'])
###创建一个203*10的空的数据框用来装RGB三通道的值
data.iloc[:,0]=[int(i) for i in label]###将类别值输入
for j in range(len(image)):
tu=Image.open(image[j])
L,T=tu.size
box=[L/2-50,T/2-50,L/2+50,T/2+50]
b=tu.crop(box)
R,G,B=b.split()
r0=np.array(R)###将图片的每个像素的RGB值得出
r1=r0.mean()###一阶矩
r2=r0.std()###二阶矩
if np.mean((r0-r1)**3)>=0:
r3=pow(np.mean((r0-r1)**3),1/3)
else:
r3=-pow(abs(np.mean((r0-r1)**3)),1/3)###三阶矩,python开负数立方根时要注意和平时不一样,需要先转化为绝对值开立方然后在结果加上负号
g0=np.array(G)
g1=g0.mean()
g2=g0.std()
if np.mean((g0-g1)**3)>=0:
g3=pow(np.mean((g0-g1)**3),1/3)
else:
g3=-pow(abs(np.mean((g0-g1)**3)),1/3)
b0=np.array(B)
b1=b0.mean()
b2=b0.std()
if np.mean((b0-b1)**3)>=0:
b3=pow(np.mean((b0-b1)**3),1/3)
else:
b3=-pow(abs(np.mean((b0-b1)**3)),1/3)
data.iloc[j,1]=r1/255###标准化数据
data.iloc[j,2]=g1/255
data.iloc[j,3]=b1/255
data.iloc[j,4]=r2/255
data.iloc[j,5]=g2/255
data.iloc[j,6]=b2/255
data.iloc[j,7]=r3/255
data.iloc[j,8]=g3/255
data.iloc[j,9]=b3/255
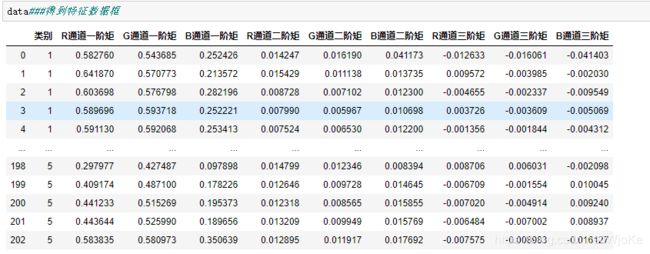
将之前的分类标签和特征值合并得到的结果如下:
3、模型建立
说好了用TPOT来选模型,那么就用这个来选。因为在anaconda中没有tpot库,所以打开anaconda prompt下载。
直接上代码:
首先划分训练集,测试集
from sklearn.model_selection import train_test_split###导入划分训练集测试集的库
data_train,data_test=train_test_split(data,test_size=0.2)###以8:2的比例划分训练集和测试集
x_train=data_train.iloc[:,1:]
x_test=data_test.iloc[:,1:]
y_train=data_train.iloc[:,0]
y_test=data_test.iloc[:,0]
然后用TPOT来选择模型:
from tpot import TPOTClassifier###导入TPOT库
tpot = TPOTClassifier(generations=10,population_size=20,verbosity=2)###迭代10次,可以改的
tpot.fit(x_train,y_train)
print(tpot.score(x_test,y_test))###得到一个最优模型
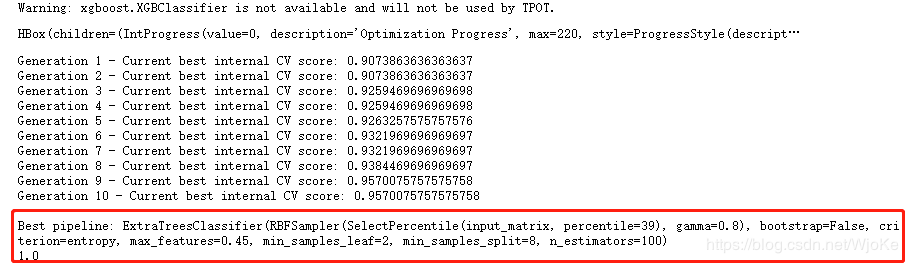 可以看见最优的模型选择出来了(过程可能有点慢)
可以看见最优的模型选择出来了(过程可能有点慢)
接下来将模型导出,方便后面改用。
tpot.export('tpot_data_pipeline.py')###将代码文件导入到py文本中,随后可以复制代码
将模型导入,做适当修改,主要是训练集测试集修改成自己的。
import numpy as np
import pandas as pd
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_selection import SelectPercentile, f_classif
from sklearn.kernel_approximation import RBFSampler
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
# Average CV score on the training set was: 0.9570075757575758
exported_pipeline = make_pipeline(
SelectPercentile(score_func=f_classif, percentile=39),
RBFSampler(gamma=0.8),
ExtraTreesClassifier(bootstrap=False, criterion="entropy", max_features=0.45, min_samples_leaf=2, min_samples_split=8, n_estimators=100)
)
exported_pipeline.fit(x_train, y_train)
results = exported_pipeline.predict(x_test)
4、模型的评价
得到模型后,来评价一下模型:
用分析报告来看
from sklearn.metrics import classification_report###评价模型
print(classification_report(y_test,results))
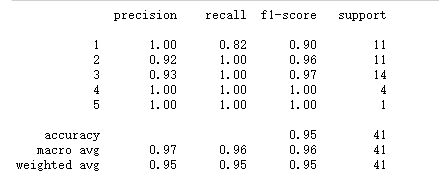
效果喜人
用混淆矩阵来看
from sklearn.metrics import confusion_matrix###创建混淆矩阵
confusion_matrix(y_test,results)###混淆矩阵里面第一类里有两个预测错误,第二类全部预测正确,第三类全部预测正确,第四类全部预测正确,第五类全部预测正确

效果喜人
5、总结
TPOT好用是好用,但是对于数据量大的就非常不友好了,对于这种数据量小的,还是可以试一试的,挺方便的,而且模型的参数也调好了,挺适合我这种傻子的hhh