Kaggle数据集之电信客户流失数据分析(一)
分析背景
某电信公司市场部为了预防用户流失,收集了已经打好流失标签的用户数据。现在要对流失用户情况进行分析,找出哪些用户可能会流失?
理解数据
采集数据
本数据集描述了电信用户是否流失以及其相关信息,共包含7043条数据,共21个字段,分别介绍如下:
- customerID : 用户ID。
- gender:性别。(Female & Male)
- SeniorCitizen :老年用户 (1表示是,0表示不是)
- Partner :伴侣用户 (Yes or No)
- Dependents :亲属用户 (Yes or No)
- tenure : 在网时长(0-72月)
- PhoneService : 是否开通电话服务业务 (Yes or No)
- MultipleLines: 是否开通了多线业务(Yes 、No or No phoneservice 三种)
- InternetService:是否开通互联网服务 (No, DSL数字网络,fiber optic光纤网络 三种)
- OnlineSecurity:是否开通网络安全服务(Yes,No,No internetserive 三种)
- OnlineBackup:是否开通在线备份业务(Yes,No,No internetserive 三种)
- DeviceProtection:是否开通了设备保护业务(Yes,No,No internetserive 三种)
- TechSupport:是否开通了技术支持服务(Yes,No,No internetserive 三种)
- StreamingTV:是否开通网络电视(Yes,No,No internetserive 三种)
- StreamingMovies:是否开通网络电影(Yes,No,No internetserive 三种)
- Contract:签订合同方式 (按月,一年,两年)
- PaperlessBilling:是否开通电子账单(Yes or No)
- PaymentMethod:付款方式(bank transfer,credit card,electronic check,mailed check)
- MonthlyCharges:月费用
- TotalCharges:总费用
- Churn:该用户是否流失(Yes or No)
导入数据
import pandas as pd
df=pd.read_csv(r"D:\PycharmProjects\ku_pandas\WA_Fn-UseC_-Telco-Customer-Churn.csv")
df.head(5) #显示数据前n行,不指定n,df.head则会显示所有的行| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | ... | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | ... | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | ... | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
5 rows × 21 columns
查看数据
df.shape #显示数据的格式(7043, 21)
df.dtypes #输出每一列对应的数据类型customerID object
gender object
SeniorCitizen int64
Partner object
Dependents object
tenure int64
PhoneService object
MultipleLines object
InternetService object
OnlineSecurity object
OnlineBackup object
DeviceProtection object
TechSupport object
StreamingTV object
StreamingMovies object
Contract object
PaperlessBilling object
PaymentMethod object
MonthlyCharges float64
TotalCharges object
Churn object
dtype: object
df.columns #显示全部的列名Index(['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents',
'tenure', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport',
'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling',
'PaymentMethod', 'MonthlyCharges', 'TotalCharges', 'Churn'],
dtype='object')
df.columns.tolist() #使用tolist()函数转化为list['customerID',
'gender',
'SeniorCitizen',
'Partner',
'Dependents',
'tenure',
'PhoneService',
'MultipleLines',
'InternetService',
'OnlineSecurity',
'OnlineBackup',
'DeviceProtection',
'TechSupport',
'StreamingTV',
'StreamingMovies',
'Contract',
'PaperlessBilling',
'PaymentMethod',
'MonthlyCharges',
'TotalCharges',
'Churn']
type(df.columns.tolist())list
df.columns.values #获取所有列索引的名称array(['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents',
'tenure', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection',
'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract',
'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges',
'TotalCharges', 'Churn'], dtype=object)
df.isnull().sum().values.sum() #查找缺失值0
df.nunique() #查看不同值customerID 7043
gender 2
SeniorCitizen 2
Partner 2
Dependents 2
tenure 73
PhoneService 2
MultipleLines 3
InternetService 3
OnlineSecurity 3
OnlineBackup 3
DeviceProtection 3
TechSupport 3
StreamingTV 3
StreamingMovies 3
Contract 3
PaperlessBilling 2
PaymentMethod 4
MonthlyCharges 1585
TotalCharges 6531
Churn 2
dtype: int64
df.describe() #查看数值型列的汇总统计| SeniorCitizen | tenure | MonthlyCharges | |
|---|---|---|---|
| count | 7043.000000 | 7043.000000 | 7043.000000 |
| mean | 0.162147 | 32.371149 | 64.761692 |
| std | 0.368612 | 24.559481 | 30.090047 |
| min | 0.000000 | 0.000000 | 18.250000 |
| 25% | 0.000000 | 9.000000 | 35.500000 |
| 50% | 0.000000 | 29.000000 | 70.350000 |
| 75% | 0.000000 | 55.000000 | 89.850000 |
| max | 1.000000 | 72.000000 | 118.750000 |
df.info() #查看索引、数据类型和内存信息
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7043 non-null object
1 gender 7043 non-null object
2 SeniorCitizen 7043 non-null int64
3 Partner 7043 non-null object
4 Dependents 7043 non-null object
5 tenure 7043 non-null int64
6 PhoneService 7043 non-null object
7 MultipleLines 7043 non-null object
8 InternetService 7043 non-null object
9 OnlineSecurity 7043 non-null object
10 OnlineBackup 7043 non-null object
11 DeviceProtection 7043 non-null object
12 TechSupport 7043 non-null object
13 StreamingTV 7043 non-null object
14 StreamingMovies 7043 non-null object
15 Contract 7043 non-null object
16 PaperlessBilling 7043 non-null object
17 PaymentMethod 7043 non-null object
18 MonthlyCharges 7043 non-null float64
19 TotalCharges 7043 non-null object
20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
数据清洗、数据一致化
1. 简化属性值
- 将InternetService中的DSL数字网络,fiber optic光纤网络替换为Yes
- 将MultipleLines中的No phoneservice替换成No
- 将SeniorCitizen中的1改为Yes,0改为No
- 将Churn中的Yes改为非流失客户,No改为流失客户
- 将TotalCharges转换为数字型
# 将InternetService中的DSL数字网络,fiber optic光纤网络替换为Yes
# 将MultipleLines中的No phoneservice替换成No
replace_list=['OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies']
for i in replace_list:
df[i]=df[i].str.replace('No internet service','No')
df['InternetService']=df['InternetService'].str.replace('Fiber optic','Yes')
df['InternetService']=df['InternetService'].str.replace('DSL','Yes')
df['MultipleLines']=df['MultipleLines'].str.replace('No phone service','No')
# SeniorCitizen中的1改为Yes,0改为No
df.SeniorCitizen=df.SeniorCitizen.replace({0:'No',1:'Yes'})
# 将Churn中的Yes改为非流失客户,No改为流失客户
df.Churn=df.Churn.replace({'No':'非流失客户','Yes':'流失客户'})
# 将TotalCharges转换为数字型
df.TotalCharges=pd.to_numeric(df.TotalCharges,errors="coerce") #.to_numeric()将参数转换为数字类型,其中coerce表示无效的解析将设置为NaN
df.TotalCharges.dtypesdtype('float64')
-
str.replace()函数
s.replace(1,’one’):用‘one’代替所有等于1的值 -
pd.to_numeric()函数
to_numeric(arg, errors=‘coerce’, downcast=None),将参数转换为数字类型- arg : list, tuple, 1-d array, or Series
- errors="coerce"表示无效的解析将设置为NaN
2. 将连续数值型数据分箱
首先是tenure(在网时长),分箱需要知道该列数据的最大最小值,以便确定分箱间隔
df.tenure.describe()count 7043.000000
mean 32.371149
std 24.559481
min 0.000000
25% 9.000000
50% 29.000000
75% 55.000000
max 72.000000
Name: tenure, dtype: float64
# 在网时长分组/分箱操作
bins_t=[0,6,12,18,24,30,36,42,48,54,60,66,72]
level_t=['0.5年','1年', '1.5年', '2年', '2.5年', '3年', '3.5年', '4年', '4.5年','5年','5.5年','6年']
df['tenure_group']=pd.cut(df.tenure,bins=bins_t,labels=level_t,right=True)
df.head(5)| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | tenure_group | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | No | Yes | No | 1 | No | No | Yes | No | ... | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | 非流失客户 | 0.5年 |
| 1 | 5575-GNVDE | Male | No | No | No | 34 | Yes | No | Yes | Yes | ... | No | No | No | One year | No | Mailed check | 56.95 | 1889.50 | 非流失客户 | 3年 |
| 2 | 3668-QPYBK | Male | No | No | No | 2 | Yes | No | Yes | Yes | ... | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | 流失客户 | 0.5年 |
| 3 | 7795-CFOCW | Male | No | No | No | 45 | No | No | Yes | Yes | ... | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | 非流失客户 | 4年 |
| 4 | 9237-HQITU | Female | No | No | No | 2 | Yes | No | Yes | No | ... | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | 流失客户 | 0.5年 |
5 rows × 22 columns
- pd.cut()函数
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
pd.cut函数有7个参数,主要用于对数据从最大值到最小值进行等距划分- x : 输入待cut的一维数组
- bins : cut的段数,一般为整型,但也可以为序列向量(若不在该序列中,则是NaN)。
- right : 布尔值,确定右区间是否开闭,取True时右区间闭合
- labels : 数组或布尔值,默认为None,用来标识分后的bins,长度必须与结果bins相等,返回值为整数或者对bins的标识
- retbins : 布尔值,可选。是否返回数值所在分组,Ture则返回
- precision : 整型,bins小数精度,也就是数据以几位小数显示
- include_lowest : 布尔类型,是否包含左区间
df.MonthlyCharges.describe()count 7043.000000
mean 64.761692
std 30.090047
min 18.250000
25% 35.500000
50% 70.350000
75% 89.850000
max 118.750000
Name: MonthlyCharges, dtype: float64
# 月租费分组
bins_M=[0,20,40,60,80,100,120]
level_M=['20','40','60','80','100','120']
df['MonthlyCharges_group']=pd.cut(df.MonthlyCharges,bins=bins_M,labels=level_M,right=True)
df.head(5)| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | tenure_group | MonthlyCharges_group | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | No | Yes | No | 1 | No | No | Yes | No | ... | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | 非流失客户 | 0.5年 | 40 |
| 1 | 5575-GNVDE | Male | No | No | No | 34 | Yes | No | Yes | Yes | ... | No | No | One year | No | Mailed check | 56.95 | 1889.50 | 非流失客户 | 3年 | 60 |
| 2 | 3668-QPYBK | Male | No | No | No | 2 | Yes | No | Yes | Yes | ... | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | 流失客户 | 0.5年 | 60 |
| 3 | 7795-CFOCW | Male | No | No | No | 45 | No | No | Yes | Yes | ... | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | 非流失客户 | 4年 | 60 |
| 4 | 9237-HQITU | Female | No | No | No | 2 | Yes | No | Yes | No | ... | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | 流失客户 | 0.5年 | 80 |
5 rows × 23 columns
df.dropna(inplace=True) #缺失值数量不多,删除
df.isnull().sum()customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 0
Churn 0
tenure_group 0
MonthlyCharges_group 0
dtype: int64
df.Churn.value_counts()非流失客户 5163
流失客户 1869
Name: Churn, dtype: int64
数据可视化呈现
计算整体流失率
# 数据可视化呈现,计算整体流失率
import matplotlib as mlp
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df_Churn=df[df['Churn']=='流失客户']
Rate_Churn=df[df['Churn']=='流失客户'].shape[0]/df['Churn'].shape[0]
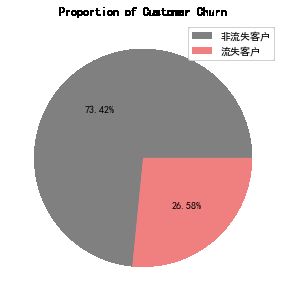
print('经计算,整体流失率={:.2%}'.format(Rate_Churn))经计算,整体流失率=26.58%
- 注意,%matplotlib inline不能缺少
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
%matplotlib inline
fig=plt.figure(num=1,figsize=(5,5))
plt.pie(df['Churn'].value_counts(),autopct="%.2f%%",colors=['grey','lightcoral'])
plt.title('Proportion of Customer Churn')
plt.legend(labels=['非流失客户','流失客户'],loc='best')
- 注意:要想显示中文,必须加plt.rcParams[‘font.sans-serif’]=[‘SimHei’]
问题1:流失用户的特征是什么?
对指标进行归纳梳理,分用户画像指标,消费产品指标,消费信息指标。
- 用户画像指标
- 人口统计指标:‘gender’,‘SeniorCitizen’,‘Partner’,‘Dependents’
- 用户活跃度:‘tenure’
- 消费产品指标
- 手机服务:‘PhoneService’,‘MultipleLines’
- 网络服务:‘InternetService’,‘OnlineSecurity’,‘OnlineBackup’,‘DeviceProtection’,‘TechSupport’,‘StreamingTV’,‘StreamingMovies’
- 消费信息指标
- 收入指标:‘MonthlyCharges’,‘TotalCharges’
- 收入相关指标:‘Contract’,‘PaperlessBilling’,‘PaymentMethod’
采用整体流失率作为标准,用于后面分析各维度的流失率做对比。
未完待续
参考文章:电信客户流失数据分析