Indian Buffet Process(印度自助餐过程)介绍
近期,有人将本人博客,复制下来,直接上传到百度文库等平台。
本文为原创博客,仅供学习使用。未经允许,禁止将其复制下来上传到百度文库等平台。如有转载请注明本文博客的地址(链接)
简介
无监督学习的目的是从观测数据中,发掘潜在的结构(latent structure)。无监督学习算法的一个关键问题是如何确定潜在结构的数目,如聚类中的类的数目,变量的数目等。以聚类为例,如果能够基于数据之间的内在关系,自动学习类的数目,要比通过经验设置一个数目要好的多。
相比参数化的贝叶斯模型,非参贝叶斯有其独特的地方,也是近些年来,机器学习比较火的一种方法,如DPMM(Dirichlet process mixture model)、层次DP过程(Hierarchical Dirichlet Processes)等。DPMM和HDP模型都是假设一个数据点只能分配到一个潜在类或者簇中(each datapoint is assigned to a latent class),即一个数据点。相反,无监督学习的一些模型中,假设一个数据点可以拥有多个特征,经典的模型有主成分分析(PCA)、因子分析(factor analysis)。从图(1)中可以看出每个数据点 x 对应一个所属的类 θ 。 从图(2)中可以看出,每个数据点(顾客)只能被分配到一个类中(即一个顾客只能坐一张座子),在黑白格子的图中,行代表数据点(顾客),列代表隐特征(菜-类),可以看出,每一个数据点,在一行中,只有一个涂黑的。
关于中餐馆过程可以参考我写的另外的博客:
http://blog.csdn.net/qy20115549/article/details/52371443
也可参考相关论文(提供一篇中文的,一篇英文的):
Teh Y W, Jordan M I, Beal M J, et al. Sharing clusters among related groups: Hierarchical Dirichlet processes[C]//Advances in neural information processing systems. 2005: 1385-1392.
周建英, 王飞跃, 曾大军. 分层 Dirichlet 过程及其应用综述[J]. 自动化学报, 2011, 37(4): 389-407.

图(1) 左图为DPMM 右图为HDP

图(2) 中餐馆过程
印度自助餐过程(Indian Buffet Process,IBP)是2005年提出的,其核心思想是一个数据点可用无限个二元特征表示,即数据点可以拥有多个隐性特征,且这些特征的概率和不为1。该过程定义了一个有限维行(数据点的个数)、无限维列(隐特征数目)的先验。从图3和图4中,可以看出,一个数据点可以拥有多个隐特征,形象的理解为一个自助餐馆中,一个顾客可以选择吃多个菜。
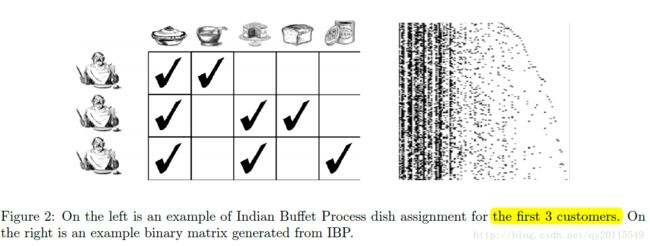
图(3) IBP过程
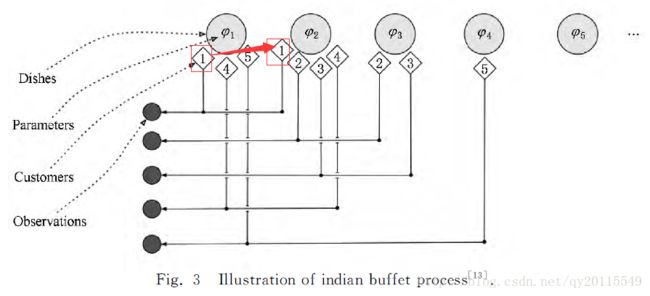
图(4) IBP过程
隐类别模型(Latent Class Models)
在隐类别模型中,一个数据点只能属于一个类别,主要包括有限混合模型和无限混合模型。
有限混合模型
假设有 N 个数据点,有K个类,其概率生成模型可以表示如下



利用多项式分布与Dirichlet共轭,有如下公式:
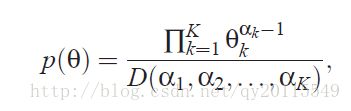
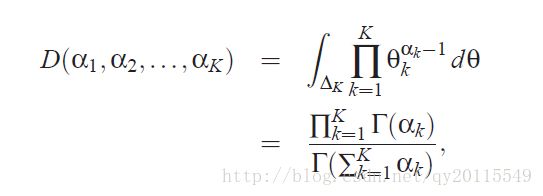
对隐变量 θ 进行积分得:

我们可以看到 p(c) 依旧服从Dirichlet分布。
无限混合模型
可以参考我这篇博客:http://blog.csdn.net/qy20115549/article/details/77905679
主要介绍的是DPMM。
也可看这两篇论文:
Teh Y W, Jordan M I, Beal M J, et al. Sharing clusters among related groups: Hierarchical Dirichlet processes[C]//Advances in neural information processing systems. 2005: 1385-1392.
周建英, 王飞跃, 曾大军. 分层 Dirichlet 过程及其应用综述[J]. 自动化学报, 2011, 37(4): 389-407.
下面两个图,一个是有向图表示,一个是生成过程。
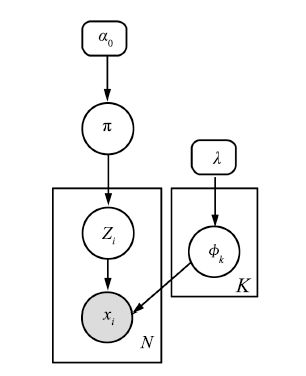

其对隐特征的抽样公式如下:
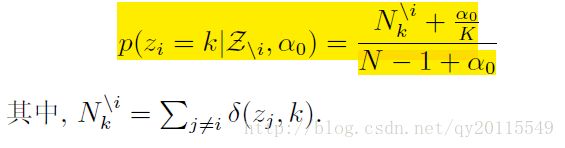
中餐馆过程
中国餐馆过程是一个典型的Dirichlet过程混合模型。可以将中国餐馆过程描述如下:
1.假设一个中国餐馆中,可以有无限个桌子。
2.来吃饭的第一位顾客坐了第一张桌子。
3.对于每一位顾客,都按照下面的规则来选择桌子坐下,对于第n个顾客:
(3.1)顾客选择坐在已经有人的桌子上,这样的概率为
其中, nk 表示第 k 个桌子上已经有的顾客数。 n−1 表示在这个顾客之前,已有的顾客总数。
(3.2)顾客可以选择坐在一个没有人坐的桌子上 K+1 的概率为
在这里,可以将顾客类比成数据,将每一张桌子类别成类。
隐特征模型(Latent Feature Models)
印度自助餐过程(Indian Buffet Process)
简介
印度自助餐过程可以类比成: N 个顾客(表示 N 个数据)进入一个有无穷多菜品的自助餐馆进行选餐的过程,用 1 表示选择了该菜,用 0 表示没有选择该菜,一个用户可以选择多个菜,直到其餐盘满了。
在印度自助餐过程中,
(1): N 个顾客,一个接着一个进入餐馆,餐馆中的自助菜品排成一排供顾客选择。第一个顾客从左至右开始选择 K1 个菜品,其中:
(2):对于第二个顾客及后面的顾客则存在两种情况:
(2.1)对于已被选择的菜品,该顾客按照选择该菜品的人数成正比的概率选择该菜品,即 mki ,其中 mk 表示选择第 k 个菜品的人数 。
(2.2)或者选择 Ki 个从未被其他顾客选择的菜品,其中:
如下图所示:当 α=10 的情况。

Gibbs Sampling
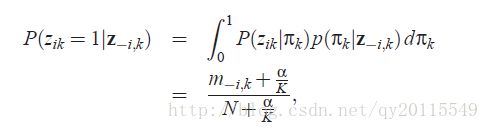
当 K→∞ 时,得:
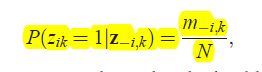
由贝叶斯公式可得后验为:
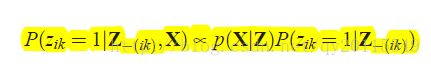
公式中的p\left ( X|Z \right )为数据似然,计算时,要根据数据的分布。
参考文献:
Teh Y W, Jordan M I, Beal M J, et al. Sharing clusters among related groups: Hierarchical Dirichlet processes[C]//Advances in neural information processing systems. 2005: 1385-1392.
Griffiths T L, Ghahramani Z. The indian buffet process: An introduction and review[J]. Journal of Machine Learning Research, 2011, 12(Apr): 1185-1224.
Ghahramani Z. The Indian Buffet Process[J].
朱军, 胡文波. 贝叶斯机器学习前沿进展综述[J]. 计算机研究与发展, 2015, 52(1): 16-26.