实战 | 电信客户流失分析与预测
本文所有代码都通过运行!
将从以下方面进行分析:1.背景 2.提出问题 3.理解数据 4.数据清洗 5.可视化分析 6.用户流失预测 7.结论和建议
本项目带你根据以上过程详细分析电信客户数据!
01
背景
关于用户留存有这样一个观点,如果将用户流失率降低5%,公司利润将提升25%-85%。如今高居不下的获客成本让电信运营商遭遇“天花板”,甚至陷入获客难的窘境。随着市场饱和度上升,电信运营商待解决增加用户黏性,延长用户生命周期的问题。因此,电信用户流失分析与预测至关重要。数据集为“电信运营商客户数据集”
02
提出问题
1.分析用户特征与流失的关系
2.从整体情况看,流失用户的普遍具有哪些特征?
3.尝试找到合适的模型预测流失用户。
4.针对性给出增加用户黏性、预防流失的建议。
03
理解数据
根据介绍,该数据集有21个字段,共7043条记录。每条记录包含了唯一客户的特征。我们目标就是发现前20列特征和最后一列客户是否流失特征之间的关系。
04
数据清洗
数据清洗的“完全合一”规则:
1、完整性:单条数据是否存在空值,统计的字段是否完善。
2、全面性:观察某一列的全部数值,通过常识来判断该列是否有问题,比如:数据定义、单位标识、数据本身。
3、合法性:数据的类型、内容、大小的合法性。比如数据中是否存在非ASCII字符,性别存在了未知,年龄超过了150等。
4、唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的。
导入工具包。
In [1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
导入数据集文件。
In [2]:
customerDF = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')查看数据集信息,查看数据集大小,并初步观察前10条的数据内容。
In [3]:
# 查看数据集大小
customerDF.shape
# 运行结果:(7043, 21)
#设置查看列不省略
pd.set_option('display.max_columns',None)
# 查看前10条数据
customerDF.head(10)查看数据是否存在Null,没有发现。
In [4]:
# Null计数
pd.isnull(customerDF).sum()
查看数据类型,根据一般经验,发现‘TotalCharges’总消费额的数据类型为字符串,应该转换为浮点型数据。
In [5]:
# 查看数据类型
customerDF.info()#customerDf.dtypes
将‘TotalCharges’总消费额的数据类型转换为浮点型,发现错误:字符串无法转换为数字。
In [6]:
#customerDf[['TotalCharges']].astype(float)#ValueError: could not convert string to float:依次检查各个字段的数据类型、字段内容和数量。最后发现“TotalCharges”(总消费额)列有11个用户数据缺失。
采用强制转换,将“TotalCharges”(总消费额)转换为浮点型数据。
In [7]:
#强制转换为数字,不可转换的变为NaN
customerDF['TotalCharges']=customerDF['TotalCharges'].convert_objects(convert_numeric=True)
转换后发现“TotalCharges”(总消费额)列有11个用户数据缺失,为NaN。
In [8]:
test=customerDF.loc[:,'TotalCharges'].value_counts().sort_index()
print(test.sum())
#运行结果:7032
print(customerDF.tenure[customerDF['TotalCharges'].isnull().values==True])
#运行结果:11
经过观察,发现这11个用户‘tenure’(入网时长)为0个月,推测是当月新入网用户。根据一般经验,用户即使在注册的当月流失,也需缴纳当月费用。因此将这11个用户入网时长改为1,将总消费额填充为月消费额,符合实际情况。
In [9]:
#将总消费额填充为月消费额
customerDF.loc[:,'TotalCharges'].replace(to_replace=np.nan,value=customerDF.loc[:,'MonthlyCharges'],inplace=True)#查看是否替换成功
print(customerDF[customerDF['tenure']==0][['tenure','MonthlyCharges','TotalCharges']])
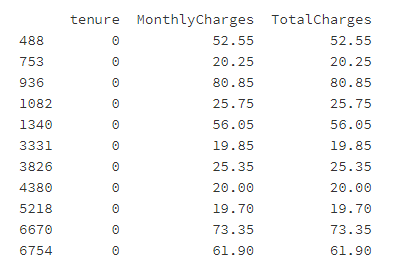
In [10]:
# 将‘tenure’入网时长从0修改为1
customerDF.loc[:,'tenure'].replace(to_replace=0,value=1,inplace=True)
print(pd.isnull(customerDF['TotalCharges']).sum())
print(customerDF['TotalCharges'].dtypes)
0
float64查看数据的描述统计信息,根据一般经验,所有数据正常。
In [11]:
# 获取数据类型的描述统计信息
customerDF.describe()
Out[13]:
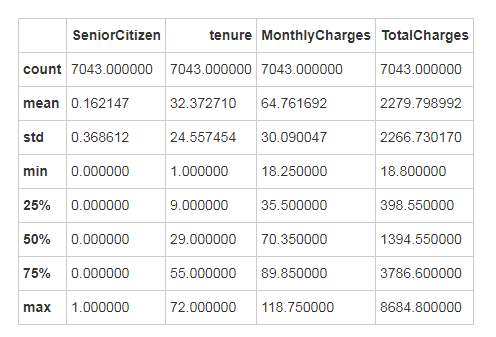
05
可视化分析
根据一般经验,将用户特征划分为用户属性、服务属性、合同属性,并从这三个维度进行可视化分析。
查看流失用户数量和占比。
plt.rcParams['figure.figsize']=6,6
plt.pie(customerDF['Churn'].value_counts(),labels=customerDF['Churn'].value_counts().index,autopct='%1.2f%%',explode=(0.1,0))
plt.title('Churn(Yes/No) Ratio')
plt.show()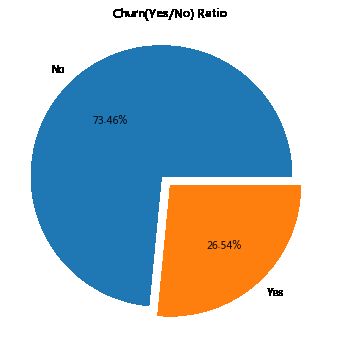 查看数量上的对比:
查看数量上的对比:
churnDf=customerDF['Churn'].value_counts().to_frame()
x=churnDf.index
y=churnDf['Churn']
plt.bar(x,y,width = 0.5,color = 'c')
#用来正常显示中文标签(需要安装字库)
plt.title('Churn(Yes/No) Num')
plt.show()
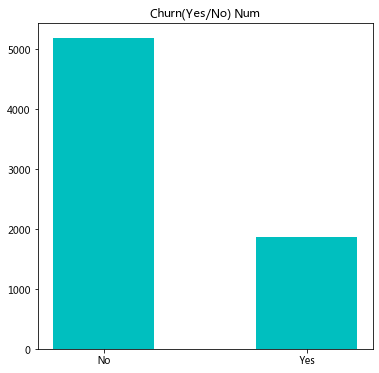
属于不平衡数据集,流失用户占比达26.54%。
(1)用户属性分析
def barplot_percentages(feature,orient='v',axis_name="percentage of customers"):
ratios = pd.DataFrame()
g = (customerDF.groupby(feature)["Churn"].value_counts()/len(customerDF)).to_frame()
g.rename(columns={"Churn":axis_name},inplace=True)
g.reset_index(inplace=True)
#print(g)
if orient == 'v':
ax = sns.barplot(x=feature, y= axis_name, hue='Churn', data=g, orient=orient)
ax.set_yticklabels(['{:,.0%}'.format(y) for y in ax.get_yticks()])
plt.rcParams.update({'font.size': 13})
#plt.legend(fontsize=10)
else:
ax = sns.barplot(x= axis_name, y=feature, hue='Churn', data=g, orient=orient)
ax.set_xticklabels(['{:,.0%}'.format(x) for x in ax.get_xticks()])
plt.legend(fontsize=10)
plt.title('Churn(Yes/No) Ratio as {0}'.format(feature))
plt.show()
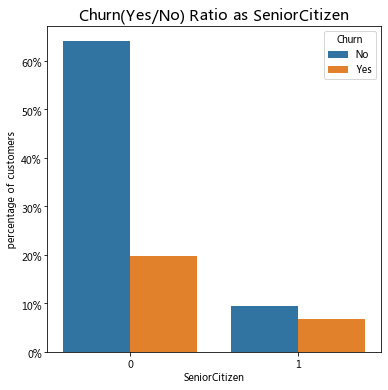
barplot_percentages("SeniorCitizen")
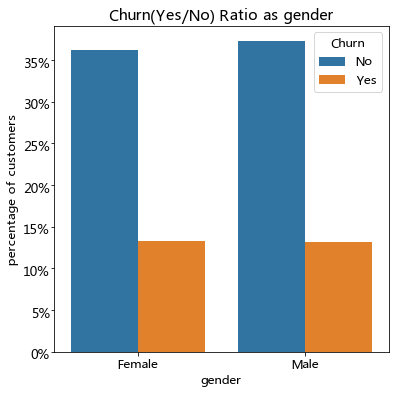
barplot_percentages("gender")
customerDF['churn_rate'] = customerDF['Churn'].replace("No", 0).replace("Yes", 1)
g = sns.FacetGrid(customerDF, col="SeniorCitizen", height=4, aspect=.9)
ax = g.map(sns.barplot, "gender", "churn_rate", palette = "Blues_d", order= ['Female', 'Male'])
plt.rcParams.update({'font.size': 13})
plt.show()
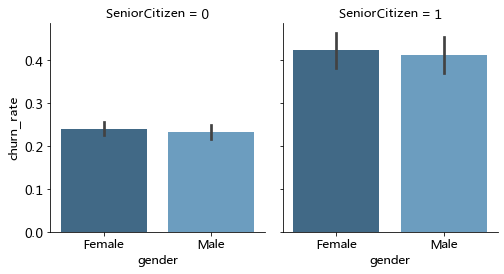
小结:
用户流失与性别基本无关;年老用户流失占显著高于年轻用户。
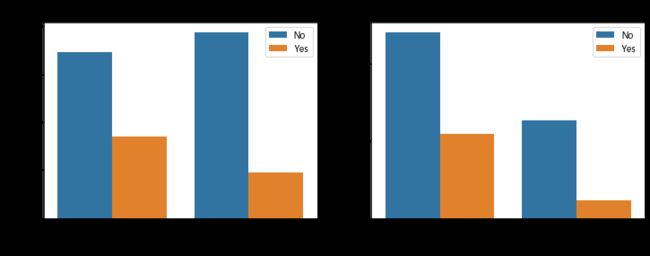
fig, axis = plt.subplots(1, 2, figsize=(12,4))
axis[0].set_title("Has Partner")
axis[1].set_title("Has Dependents")
axis_y = "percentage of customers"
# Plot Partner column
gp_partner = (customerDF.groupby('Partner')["Churn"].value_counts()/len(customerDF)).to_frame()
gp_partner.rename(columns={"Churn": axis_y}, inplace=True)
gp_partner.reset_index(inplace=True)
ax1 = sns.barplot(x='Partner', y= axis_y, hue='Churn', data=gp_partner, ax=axis[0])
ax1.legend(fontsize=10)
#ax1.set_xlabel('伴侣')
# Plot Dependents column
gp_dep = (customerDF.groupby('Dependents')["Churn"].value_counts()/len(customerDF)).to_frame()
#print(gp_dep)
gp_dep.rename(columns={"Churn": axis_y} , inplace=True)
#print(gp_dep)
gp_dep.reset_index(inplace=True)
#print(gp_dep)
ax2 = sns.barplot(x='Dependents', y= axis_y, hue='Churn', data=gp_dep, ax=axis[1])
#ax2.set_xlabel('家属')
#设置字体大小
plt.rcParams.update({'font.size': 20})
ax2.legend(fontsize=10)
#设置
plt.show()
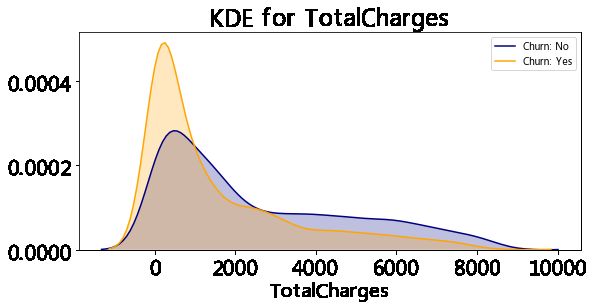
# Kernel density estimaton核密度估计
def kdeplot(feature,xlabel):
plt.figure(figsize=(9, 4))
plt.title("KDE for {0}".format(feature))
ax0 = sns.kdeplot(customerDF[customerDF['Churn'] == 'No'][feature].dropna(), color= 'navy', label= 'Churn: No', shade='True')
ax1 = sns.kdeplot(customerDF[customerDF['Churn'] == 'Yes'][feature].dropna(), color= 'orange', label= 'Churn: Yes',shade='True')
plt.xlabel(xlabel)
#设置字体大小
plt.rcParams.update({'font.size': 20})
plt.legend(fontsize=10)
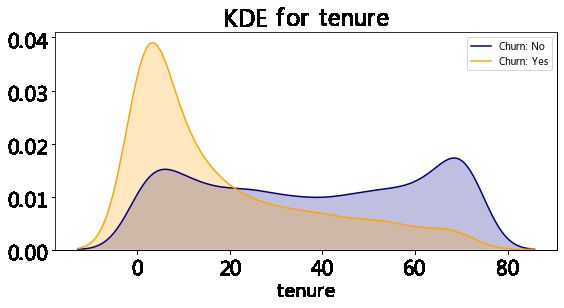
kdeplot('tenure','tenure')
plt.show()

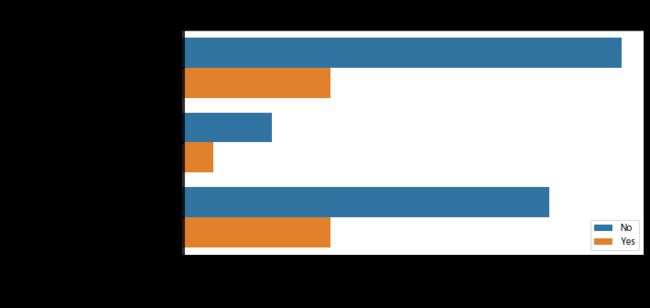
(2)服务属性分析
plt.figure(figsize=(9, 4.5))
barplot_percentages("MultipleLines", orient='h')
plt.figure(figsize=(9, 4.5))
barplot_percentages("InternetService", orient="h")
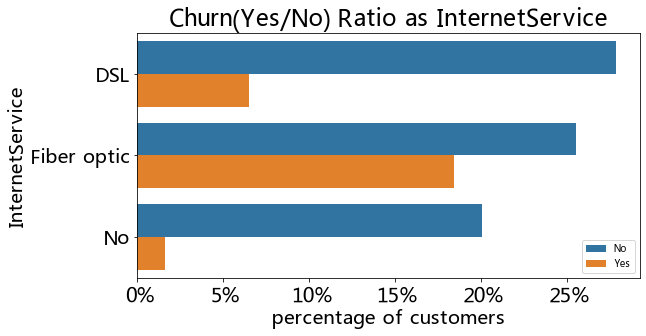
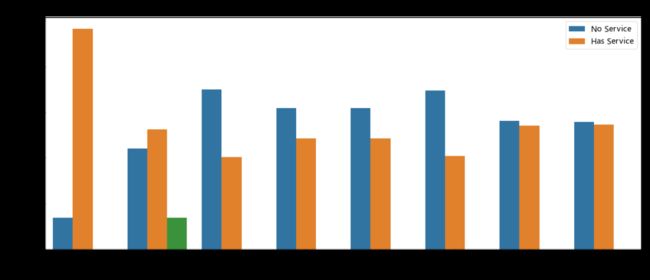
cols = ["PhoneService","MultipleLines","OnlineSecurity", "OnlineBackup", "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies"]
df1 = pd.melt(customerDF[customerDF["InternetService"] != "No"][cols])
df1.rename(columns={'value': 'Has service'},inplace=True)
plt.figure(figsize=(20, 8))
ax = sns.countplot(data=df1, x='variable', hue='Has service')
ax.set(xlabel='Internet Additional service', ylabel='Num of customers')
plt.rcParams.update({'font.size':20})
plt.legend( labels = ['No Service', 'Has Service'],fontsize=15)
plt.title('Num of Customers as Internet Additional Service')
plt.show()
plt.figure(figsize=(20, 8))
df1 = customerDF[(customerDF.InternetService != "No") & (customerDF.Churn == "Yes")]
df1 = pd.melt(df1[cols])
df1.rename(columns={'value': 'Has service'}, inplace=True)
ax = sns.countplot(data=df1, x='variable', hue='Has service', hue_order=['No', 'Yes'])
ax.set(xlabel='Internet Additional service', ylabel='Churn Num')
plt.rcParams.update({'font.size':20})
plt.legend( labels = ['No Service', 'Has Service'],fontsize=15)
plt.title('Num of Churn Customers as Internet Additional Service')
plt.show()
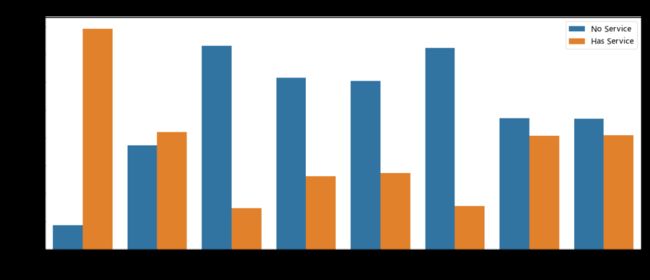 小结:
小结:

(3)合同属性分析
plt.figure(figsize=(9, 4.5))
barplot_percentages("PaymentMethod",orient='h')
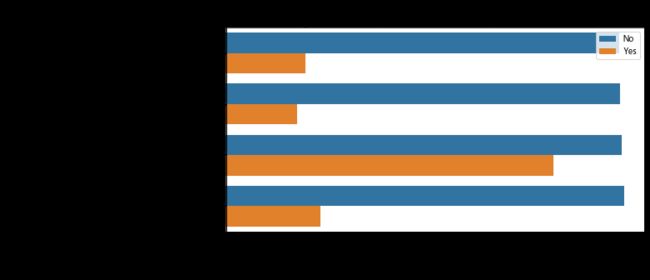
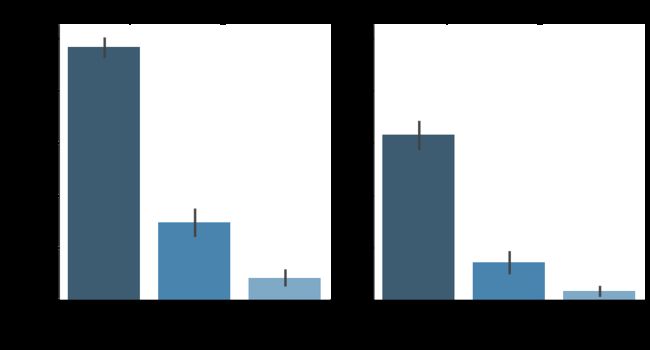
g = sns.FacetGrid(customerDF, col="PaperlessBilling", height=6, aspect=.9)
ax = g.map(sns.barplot, "Contract", "churn_rate", palette = "Blues_d", order= ['Month-to-month', 'One year', 'Two year'])
plt.rcParams.update({'font.size':18})
plt.show()
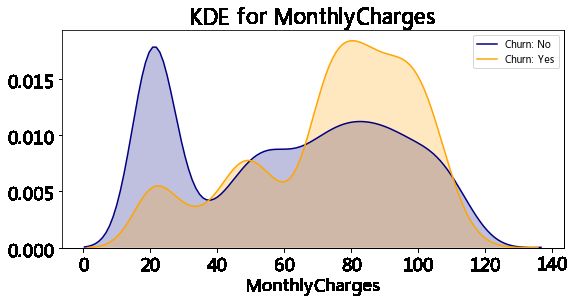
kdeplot('MonthlyCharges','MonthlyCharges')
kdeplot('TotalCharges','TotalCharges')
plt.show()
06
用户流失预测
对数据集进一步清洗和提取特征,通过特征选取对数据进行降维,采用机器学习模型应用于测试数据集,然后对构建的分类模型准确性进行分析
(1)数据清洗
customerID=customerDF['customerID']
customerDF.drop(['customerID'],axis=1, inplace=True)
观察数据类型,发现大多除了“tenure”、“MonthlyCharges”、“TotalCharges”是连续特征,其它都是离散特征。对于连续特征,采用标准化方式处理。对于离散特征,特征之间没有大小关系,采用one-hot编码;特征之间有大小关联,则采用数值映射。
获取离散特征。
cateCols = [c for c in customerDF.columns if customerDF[c].dtype == 'object' or c == 'SeniorCitizen']
dfCate = customerDF[cateCols].copy()
dfCate.head(3)太长这里省略。
下面进行特征编码。
for col in cateCols:
if dfCate[col].nunique() == 2:
dfCate[col] = pd.factorize(dfCate[col])[0]
else:
dfCate = pd.get_dummies(dfCate, columns=[col])
dfCate['tenure']=customerDF[['tenure']]
dfCate['MonthlyCharges']=customerDF[['MonthlyCharges']]
dfCate['TotalCharges']=customerDF[['TotalCharges']]
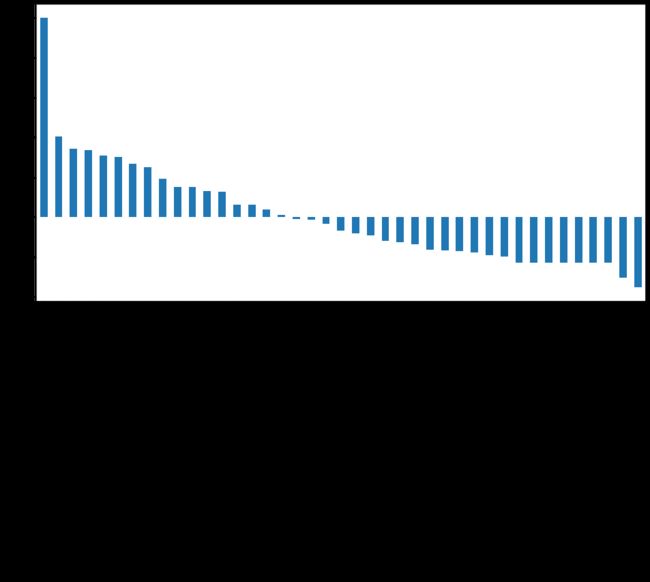
查看关联关系
plt.figure(figsize=(16,8))
dfCate.corr()['Churn'].sort_values(ascending=False).plot(kind='bar')
plt.show()
(2)特征选取
# 特征选择
dropFea = ['gender','PhoneService',
'OnlineSecurity_No internet service', 'OnlineBackup_No internet service',
'DeviceProtection_No internet service', 'TechSupport_No internet service',
'StreamingTV_No internet service', 'StreamingMovies_No internet service',
#'OnlineSecurity_No', 'OnlineBackup_No',
#'DeviceProtection_No','TechSupport_No',
#'StreamingTV_No', 'StreamingMovies_No',
]
dfCate.drop(dropFea, inplace=True, axis =1)
#最后一列是作为标识
target = dfCate['Churn'].values
#列表:特征和1个标识
columns = dfCate.columns.tolist()
构造训练数据集和测试数据集。
# 列表:特征
columns.remove('Churn')
# 含有特征的DataFrame
features = dfCate[columns].values
# 30% 作为测试集,其余作为训练集
# random_state = 1表示重复试验随机得到的数据集始终不变
# stratify = target 表示按标识的类别,作为训练数据集、测试数据集内部的分配比例
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(features, target, test_size=0.30, stratify = target, random_state = 1)
(3)构建模型
构造多个分类器,
# 构造各种分类器
classifiers = [
SVC(random_state = 1, kernel = 'rbf'),
DecisionTreeClassifier(random_state = 1, criterion = 'gini'),
RandomForestClassifier(random_state = 1, criterion = 'gini'),
KNeighborsClassifier(metric = 'minkowski'),
AdaBoostClassifier(random_state = 1),
]
# 分类器名称
classifier_names = [
'svc',
'decisiontreeclassifier',
'randomforestclassifier',
'kneighborsclassifier',
'adaboostclassifier',
]
# 分类器参数
#注意分类器的参数,字典键的格式,GridSearchCV对调优的参数格式是"分类器名"+"__"+"参数名"
classifier_param_grid = [
{'svc__C':[0.1], 'svc__gamma':[0.01]},
{'decisiontreeclassifier__max_depth':[6,9,11]},
{'randomforestclassifier__n_estimators':range(1,11)} ,
{'kneighborsclassifier__n_neighbors':[4,6,8]},
{'adaboostclassifier__n_estimators':[70,80,90]}
]
(4)模型参数调优和评估
对分类器进行参数调优和评估,最后得到试用AdaBoostClassifier(n_estimators=80)效果最好。
# 对具体的分类器进行 GridSearchCV 参数调优
def GridSearchCV_work(pipeline, train_x, train_y, test_x, test_y, param_grid, score = 'accuracy_score'):
response = {}
gridsearch = GridSearchCV(estimator = pipeline, param_grid = param_grid, cv=3, scoring = score)
# 寻找最优的参数 和最优的准确率分数
search = gridsearch.fit(train_x, train_y)
print("GridSearch 最优参数:", search.best_params_)
print("GridSearch 最优分数: %0.4lf" %search.best_score_)
#采用predict函数(特征是测试数据集)来预测标识,预测使用的参数是上一步得到的最优参数
predict_y = gridsearch.predict(test_x)
print(" 准确率 %0.4lf" %accuracy_score(test_y, predict_y))
response['predict_y'] = predict_y
response['accuracy_score'] = accuracy_score(test_y,predict_y)
return response
for model, model_name, model_param_grid in zip(classifiers, classifier_names, classifier_param_grid):
#采用 StandardScaler 方法对数据规范化:均值为0,方差为1的正态分布
pipeline = Pipeline([
#('scaler', StandardScaler()),
#('pca',PCA),
(model_name, model)
])
result = GridSearchCV_work(pipeline, train_x, train_y, test_x, test_y, model_param_grid , score = 'accuracy')
07
结论和建议
根据以上分析,得到高流失率用户的特征:
用户属性:老年用户,未婚用户,无亲属用户更容易流失;服务属性:在网时长小于半年,有电话服务,光纤用户/光纤用户附加流媒体电视、电影服务,无互联网增值服务;合同属性:签订的合同期较短,采用电子支票支付,是电子账单,月租费约70-110元的客户容易流失;其它属性对用户流失影响较小,以上特征保持独立。针对上述结论,从业务角度给出相应建议:
根据预测模型,构建一个高流失率的用户列表。通过用户调研推出一个最小可行化产品功能,并邀请种子用户进行试用。用户方面:针对老年用户、无亲属、无伴侣用户的特征退出定制服务如亲属套餐、温暖套餐等,一方面加强与其它用户关联度,另一方对特定用户提供个性化服务。服务方面:针对新注册用户,推送半年优惠如赠送消费券,以渡过用户流失高峰期。针对光纤用户和附加流媒体电视、电影服务用户,重点在于提升网络体验、增值服务体验,一方面推动技术部门提升网络指标,另一方面对用户承诺免费网络升级和赠送电视、电影等包月服务以提升用户黏性。针对在线安全、在线备份、设备保护、技术支持等增值服务,应重点对用户进行推广介绍,如首月/半年免费体验。合同方面:针对单月合同用户,建议推出年合同付费折扣活动,将月合同用户转化为年合同用户,提高用户在网时长,以达到更高的用户留存。针对采用电子支票支付用户,建议定向推送其它支付方式的优惠券,引导用户改变支付方式。
注
数据集获取方式
关注下方公众号,后台回复“客户”关键字获取哦~



我不仅仅是一个码