【4月20日】使用requests登陆教务处网站并查询课表
最近上课总是记不住是哪个教室,感觉每次都要人工登陆教务处网站去查教室很麻烦。正好在学习爬虫,于是想直接写个爬虫去帮我查课表信息岂不美哉?
说干就干。使用requests,个人感觉比较好用的第三方库,基于py3;解析用beautifulsoup。打开Chorme,登陆南理工的教务处网站并跟踪登陆过程的网络行为。
可以看见,需要输入的信息有三样。用户名和密码好办,主要是验证码的及时识别。拟采取的策略为:下载验证码文件到本地,然后再人工输入。点击登陆,继续跟踪网络行为,发现在此输入的数据(连同其他一些附带数据)被post到了http://gsmis.njust.edu.cn/中。
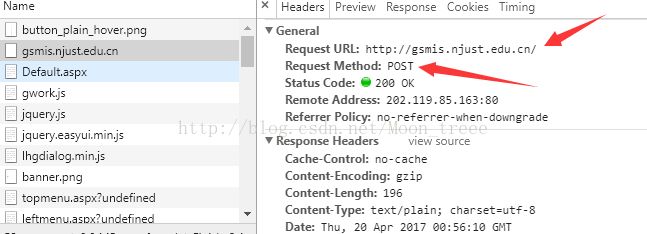
进一步查看这个post的FormData就可以找到这三个数据了,分别为UserName,PassWord以及ValidateCode。
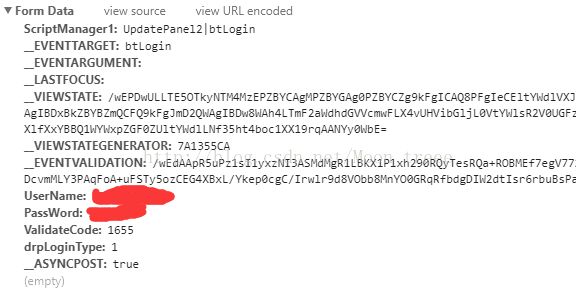
找到了这里已经解决了验证码走那条路(post)以及要到哪里去(http://gsmis.njust.edu.cn/)的问题,接下来要解决从哪里来的问题。在HTML上检查验证码的元素,可以发现其src为Public/ValidateCode.aspx?image=一串无关紧要的数字。也就是说要在http://gsmis.njust.edu.cn/Public/ValidateCode.aspx?image=中拿到验证码文件。这样一来,验证码的来龙去脉就可以厘清了,从src中获取验证码链接并下载到本地,再通过post将验证码及其他必要信息发送http://gsmis.njust.edu.cn/。
登陆之后,用相似的方式分析一下课表查询时数据以及网络行为,就可以自动课表了(虽然课是真的少,但是事情是真的多啊~~~)。另外,我发现这个方法也很麻烦,还不如直接上网查呢。
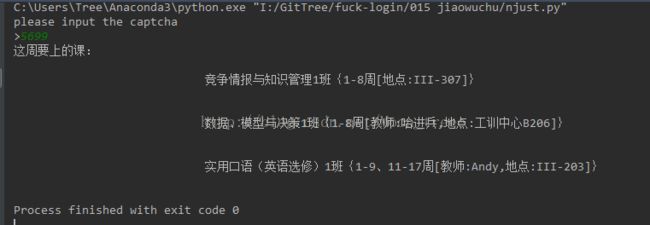
下面,直接上代码:
# -*- coding: utf-8 -*-
"""
@author: Tree
"""
import requests
from bs4 import BeautifulSoup
# 登录地址,以及查询课表的地址
LoginUrl = "http://gsmis.njust.edu.cn/UserLogin.aspx?exit=1"
class_url = "http://gsmis.njust.edu.cn/Gstudent/Course/StuCourseWeekQuery.aspx"
session = requests.session()
# 登录主函数
def login():
headerdic = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',
'Host': 'gsmis.njust.edu.cn',
'Referer': 'http://gsmis.njust.edu.cn/',
'Accept': '*/*',
'Connection': 'Keep-Alive',
}
postdic = {
'UserName': "学号",
'PassWord': "密码",
'drpLoginType': '1',
'__ASYNCPOST': 'true',
'ScriptManager1': 'UpdatePanel2|btLogin',
'__EVENTTARGET': 'btLogin',
'__VIEWSTATE': '/wEPDwULLTE5OTkyNTM4MzEPZBYCAgMPZBYGAg0PZBYCZg9kFgICAQ8PFgIeCEltYWdlVXJsBSp+L1B1YmxpYy9WYWxpZGF0ZUNvZGUuYXNweD9pbWFnZT02ODA3OTUyOTFkZAIRD2QWAmYPZBYCAgEPEGRkFgFmZAIVD2QWAmYPZBYCAgEPDxYCHgtOYXZpZ2F0ZVVybAUtfi9QdWJsaWMvRW1haWxHZXRQYXNzd2QuYXNweD9FSUQ9VHVyOHZadXVYa3M9ZGQYAQUeX19Db250cm9sc1JlcXVpcmVQb3N0QmFja0tleV9fFgEFDVZhbGlkYXRlSW1hZ2W5HJlvYqz666q9lGAspojpOWb4sA==',
'__EVENTVALIDATION': '/wEdAAoKNGMKLh/WwBcPaLKBGC94R1LBKX1P1xh290RQyTesRQa+ROBMEf7egV772v+RsRJUvPovksJgUuQnp+WD/+4LQKymBEaZgVw9rfDiAaM1opWKhJheoUmouOqQCzlwTSNWlQTw3DcvmMLY3PAqFoA+uFSTy5ozCEG4XBxL/Ykep0cgC/Irwlr9d8VObb8MnYO0GRqRfbdgDIW2dtIsr6rbUIwej/LsqVAg3gLMpVY6UeARlz0=',
'__EVENTARGUMENT': '',
'__LASTFOCUS': ''
}
login_header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Host': 'gsmis.njust.edu.cn',
'Referer': 'http://gsmis.njust.edu.cn/UserLogin.aspx?exit=1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3067.6 Safari/537.36'
}
# 执行getCheckCode,将验证码信息存入postdic中
img_url = "http://gsmis.njust.edu.cn/Public/ValidateCode.aspx?image="
postdic = getCheckCode(img_url, postdic, headerdic)
# 获取本周课表,使用get构造带有参数的访问
eid = {'EID': 'j747VIAgTbv89k5pIqOcwJMucc!p3AXikfLcF!otxmBkw0iDLfKWdA=='}
session.post("http://gsmis.njust.edu.cn/", data=postdic, headers=login_header)
sclass = session.get(class_url, params=eid, headers=headerdic)
soup = BeautifulSoup(sclass.text, "lxml")
print("这周要上的课:")
for i in range(len(soup.select('td[rowspan="4"]'))):
print(soup.select('td[rowspan="4"]')[i].get_text())
for i in range(len(soup.select('td[rowspan="2"]'))):
print(soup.select('td[rowspan="2"]')[i].get_text())
# 获取验证码并将其在本地保存
def getCheckCode(url, postdic, headerdic):
r = session.get(url, headers=headerdic)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
f.close()
captcha = input("please input the captcha\n>")
postdic["ValidateCode"] = captcha
return postdic
if __name__ == '__main__':
login()