论文浅尝 | 利用多语言 wordnet 上随机游走实现双语 embeddings
论文笔记整理:谭亦鸣,东南大学博士生,研究方向为知识图谱问答。

来源:Knowledge Based System
链接:https://www.sciencedirect.com/science/article/abs/pii/S0950705118301412?via%3Dihub
双语word embedding将两种语言表示与同一个空间中,使之不依赖机器翻译的情况下,实现知识从某一语言到另一语言的转换。实现这一方法的主要流程包括:1.训练单语embedding;2. 利用双语词典构建双语映射关系。不同于这一做法,本文提出基于多语言知识库(例如wordnet)的双语embedding方法,基本思路是通过在多语言wordnet上随机游走抽取出双语信息,而后学习到联合embedding空间中。
动机
现有的方法主要基于双语词典构建不同语言之间的桥梁,作者认为双语词典虽然给出了基本的对齐信息,但是以wordnet为代表的多语言知识库则可以在基本对齐的基础上增加同义,上下位关系等等更多的语义信息,这些可以用于构建更高质量的双语embedding。
贡献
提出了一种基于多语言知识库上随机游走的双语embedding方法
探究了从wordnet中抽取双语约束改进Skipgram的loss-function的方法
利用wordnet构建双语人工语料,并与单语数据集结合用于改进embedding方法
方法
带有约束的双语embedding
关于Skipgram
Skipgram是一种利用当前词w预测其上下文文本c的模型,目标为通过文本语料学习参数θ,使得概率P(c|w;θ)最大化。本文主要关注Skipgram中负样本在损失函数中的表现形式如下所示:

其中,(w, c)表示语料中的词w及其共现文本中的词c(共现文本由设定为K的窗口参数确定),cn表示负样本文本的词,P(c)表示噪声分布(负样本集)
引入双语约束
对于不同语言的单语语料,获得双语embedding的直接方式就是从句子级别对他们进行融合,而后利用其中的公用词,比如数字,专有名词等等作为桥梁找寻双语文本中的共现成分。但是显然这种公用词的数量是不足以构建高质量embedding的。
一种强化联合embedding空间的方式是对于上述loss-function添加约束,这种约束一般来自于外部数据,提供诸如句法,相关词等等信息。作者在这里使用基于双语词典的对等翻译,强制规范原始词与其另一种语言的对等词之间的距离,从而得到如下改进loss-function:
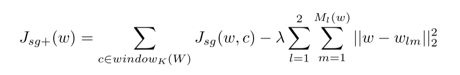
知识库随机游走
随机游走的目的是从知识库中获取能够反映结构信息的共现数据,从而用于构建wordrepresentations。
单语随机游走

首先,文章给出了单语图谱上的随机游走算法,对于给定图谱G=(C, E),其中C表示概念集,E表示概念之间的边集合。N(c)表示c在图谱上的邻居节点集,D(c)表示c可能的词汇化表达,SC表示游走结果集,S表示每一轮循环游走得到的节点路径集。
算法过程描述如下:
初始化SC为空集
根据预先定义的概率分布从C中选择一个c
根据预先定义的概率分布从c的邻居中随机选择N(c),及c的词汇化表达D(c)
重复2,3步直到达到游走步数I
从而得到图谱随机游走生成的文本,该文本带有语义结构信息(从语法上不一定成句子)。
利用生成文本(或者说词序列)从自然语言语料中抽取成分共现的句子,从而得到带有结构信息的自然语言语料
双语随机游走
为了实现多语言知识库上的随机游走,作者在算法1的基础上进行以下改进:
将单语词汇化表达D(c)变为双语集,即对于某concept由两种语言的表达可选(当知识库没有相关对齐时,某一语言的表达可以为空),修改效果如算法2,添加了一个随机选择D(c)的语言步骤,其他与单语算法基本一致。

这样得到的输出序列可能同时包含两种语言的词汇,同样,利用单语文本共现抽取,可以构建该序列的自然语言句子。
实验
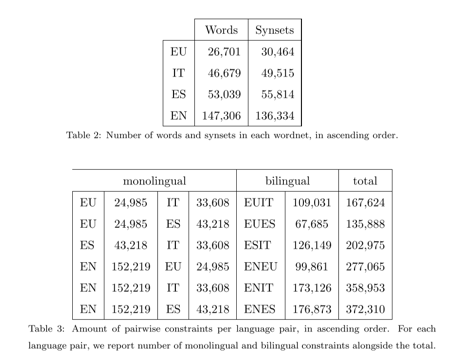
数据方面使用到了Wikipedia corpora以及wordnets
语言方面包含Basque,English,Spanish等版本(具体见原文)
一些统计信息如下:
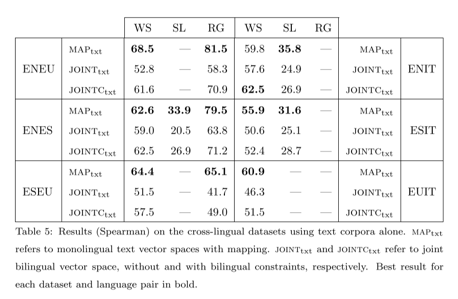
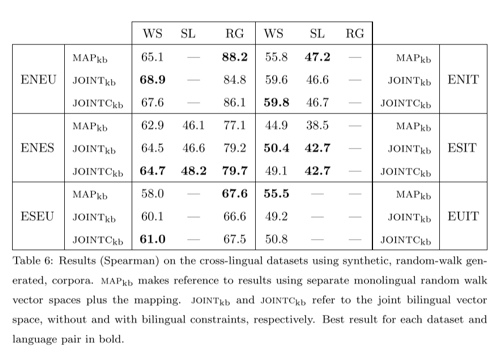
这篇文章的实验做的比较细,部分实验结果如下:
添加双语约束实验
随机游走实验
推荐阅读:
论文浅尝 | 基于属性嵌入的知识图谱实体对齐
论文浅尝 | 基于图匹配神经网络的跨语言知识图对齐 (ACL 2019)
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。