论文浅尝 | AAAI2020 - 基于生成对抗的知识图谱零样本关系学习
论文笔记整理:耿玉霞,浙江大学直博生。研究方向:知识图谱,零样本学习等。

来源:AAAI2020
论文链接:https://arxiv.org/pdf/2001.02332.pdf
本文是发表在AAAI2020上的一篇基于生成对抗网络进行知识图谱零样本关系学习的文章。在知识图谱表示学习(KG Embedding)的相关工作中,会出现一些未在训练数据集中出现过的关系(即 zero-shot relations),由于relation及其相关的三元组没有在训练数据集中出现过,则无法获得该relation训练好的向量表示,从而无法进行链接预测等下游任务。在这篇文章中,作者提出利用这些relations的文本描述信息以及生成对抗网络,为这些zero-shot relations学习到有语义意义的向量表示,从而避免KG中存在新出现的关系时,表示学习模型需要重新训练的问题。
1. 相关背景
1.1 基于生成对抗网络的零样本学习
零样本学习,即处理那些未在训练集中出现过的类别的分类问题。在训练集中出现过的类别(即seen classes),有训练数据,此类classes经训练具备一定分类该类测试样本的能力;而未在训练集中出现过的类别(即unseen classes),无训练数据,此类classes测试样本的分类/预测依赖与seen classes建立一定的语义联系(如文本描述、属性描述等),迁移相关seen classes的样本特征,使得unseen classes的样本特征得到学习,并最终实现分类。
近年来,随着生成对抗网络(Generative Adversarial Networks, GANs)在生成图片等方面的成熟运用,许多研究者将GANs引入零样本学习中,为unseen classes,这些缺少样本的classes生成训练样本,使得零样本学习转化为传统的监督学习,从而对unseen classes测试样本进行预测。
此类方法的一般框架为:基于类别的语义描述(文本描述等)及一些随机噪声,输入到GAN的生成器(Generator)中,生成该类别对应的样本特征;同时,在判别器(Discriminator)中,将生成的样本(fake data)与真实样本的特征(real data)经过对抗,使得生成器生成高质量的样本。经过训练的生成对抗网络,具备为unseen classes生成样本的能力。
1.2 知识图谱中的零样本关系学习
知识图谱的表示学习通常用于知识图谱的补全(链接预测等)任务,对于一个三元组,在给定头实体(head entity)及关系的情况下,预测其对应的尾实体(tail entity)。这篇文章的作者们考虑了KG中的零样本关系学习,即对于新出现的一些关系,在不经过表示学习算法重新训练的情况下,依然能在这些关系上进行链接预测的任务。
考虑KG中存在一些由seen relations组成的训练数据集: ![]() ,其对应的测试集由unseen relations组成:
,其对应的测试集由unseen relations组成: 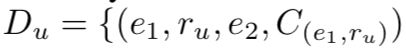 ,零样本学习算法最终的任务即为这些unseen relations涉及到的head entity预测其对应的tail entity。值得注意的是,本篇文章的问题设定集中在处理zero-shot relations,未考虑会出现一些新的实体,即KG中的实体在训练集和测试集中都出现过。换句话说,在测试时,对于KG中已经存在的实体添加了一些zero-shot relations,预测它们是否构成一个完整的三元组。
,零样本学习算法最终的任务即为这些unseen relations涉及到的head entity预测其对应的tail entity。值得注意的是,本篇文章的问题设定集中在处理zero-shot relations,未考虑会出现一些新的实体,即KG中的实体在训练集和测试集中都出现过。换句话说,在测试时,对于KG中已经存在的实体添加了一些zero-shot relations,预测它们是否构成一个完整的三元组。
2. 算法模型
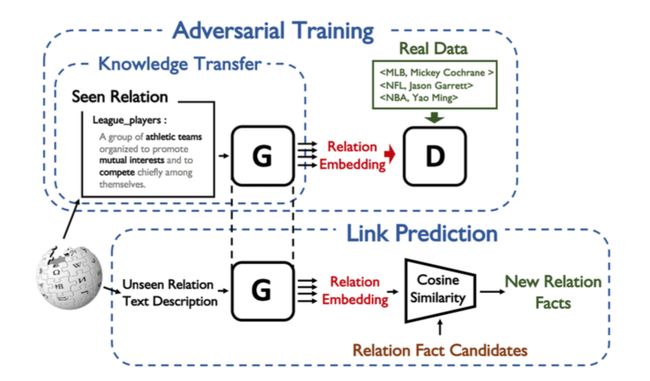
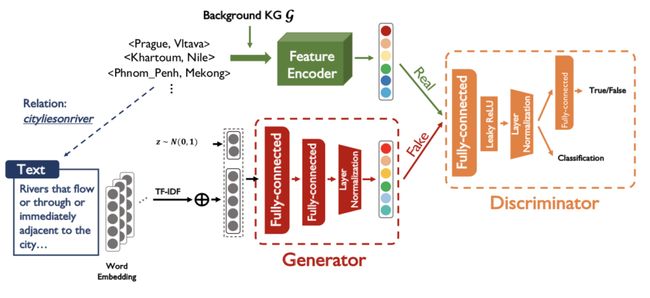
因此,本文提出使用生成对抗网络为知识图谱中的unseen relations生成特征表示,从而解决知识图谱中的零样本关系学习问题。本文的框架如下图所示。
其中,
生成器(G):利用关系的描述文本,生成关系的特征表示向量(即relation embedding),此向量蕴含了KG中的语义信息;
判别器(D):分类/判别生成样本和测试样本,并且为保证生成样本的质量,对生成的样本进行分类,使得样本具有inter discriminative的特征;
预训练的特征编码器:编码某关系对应的三元组(即获取真实样本的特征分布)。
下面将详细介绍这三个部分。
2.1 特征编码器
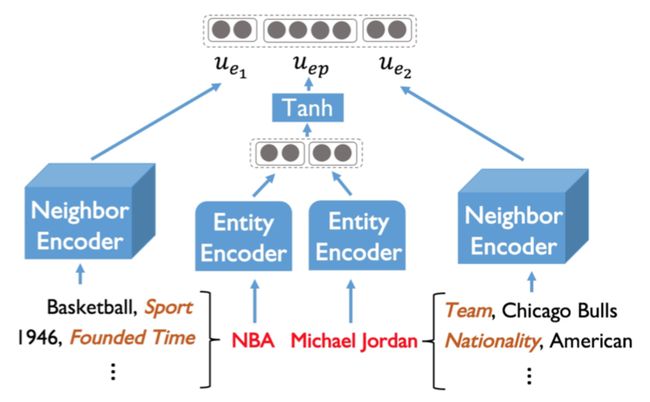
对于某关系r,存在一系列的实体对集合,这些实体对描述了该关系的样本特征分布。对于其中的每一对实体,特征编码器首先通过一个entity encoder和一个neighbor encoder捕获这些实体对的蕴含的特征;随后,得到实体对的表示后,特征编码器再组合得到该关系的表示。
Entity encoder首先将实体 经过一个全连接层,随后将实体对对应的两个实体进行拼接,得到 :
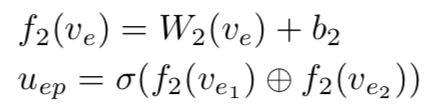
其次,neighbor encoder将实体对中每一个实体对应周围一跳范围的关系和实体进行编码,具体地,对于实体周围一跳范围的实体关系集合 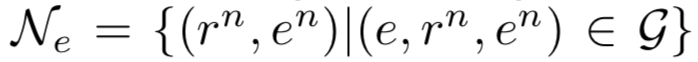 ,neighbor encoder将每一对邻居经过拼接之后,再分别经过全连接层,最终计算所有邻居表示的均值,得到:
,neighbor encoder将每一对邻居经过拼接之后,再分别经过全连接层,最终计算所有邻居表示的均值,得到:
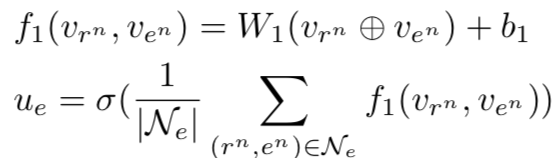
其中,对于所涉及实体和关系的初始化表示(,, etc.)可由TransE等经典的KG embedding模型得到。
对于该实体对,拼接上述实体表示,可得到关系特定的实体对表示:
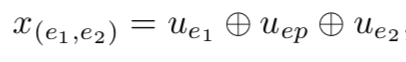
整体过程如下图所示:
最终,对关系r所有的实体对的表示进行聚类可得到关系r的特征表示:
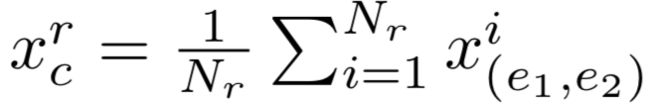
此特征编码器的训练,文章采用了基于margin loss的预训练策略。具体地,对于关系r,首先选定一些reference triples作为标准集,即 ![]() ,可得到关系的reference embedding
,可得到关系的reference embedding 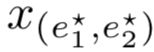 ,在训练时,使正样本
,在训练时,使正样本 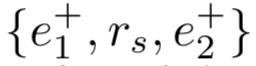 的表示逼近reference embedding,而负样本
的表示逼近reference embedding,而负样本 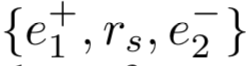 的表示远离 reference embedding,loss function为:
的表示远离 reference embedding,loss function为:
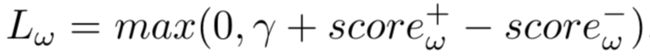
其中,正样本的score即为计算正样本和reference triple之间的cosine相似度:
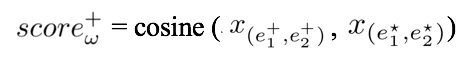
2.2 生成器
生成器利用关系r的描述文本及噪声,生成关系r的特征表示,如下图所示。
对于关系的描述文本,作者利用文本中每个词的word embedding,并通过计算文本中词的TF-IDF权重,对这些word embedding进行加权求和得到文本描述的向量表示。随后,文本的向量表示与随机采样的噪声共同作为生成器的输入。其中,生成器由两层全连接层及激活层函数组成,最终,生成关系r的特征表示。生成器的loss function为:
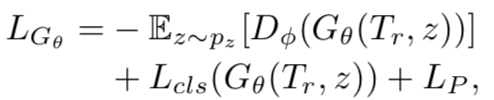
其中,生成样本表示为 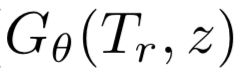 ,为关系r的文本描述表示,为随机采样的噪声;loss function的第一项为GAN中的Wasserstein loss,第二项为分类生成样本的分类损失项,第三项为 visual pivot 正则化项,即使得生成样本的中心逼近真实样本的中心。
,为关系r的文本描述表示,为随机采样的噪声;loss function的第一项为GAN中的Wasserstein loss,第二项为分类生成样本的分类损失项,第三项为 visual pivot 正则化项,即使得生成样本的中心逼近真实样本的中心。
2.3 判别器
判别器使得真实的样本和生成的样本进行对抗,从而训练生成器生成高质量样本的能力,其loss function为:
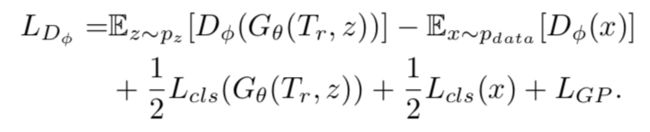
其中,前两项为计算真实样本和生成样本的Wasserstein距离,第三项、第四项分别为分类真实样本和生成样本的分类损失函数,最后一项为Wasserstein GAN网络中为保证Lipschitz constraint 约束的GP优化项(即规范判别器的梯度下降)。
2.4 Unseen relations的分类/预测
基于前面训练好的生成器,给定unseen relation的文本描述,可生成其对应的relation embedding: 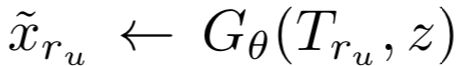 。预测时,对于一个query triple
。预测时,对于一个query triple 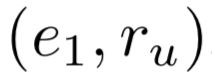 ,其候选尾实体对应的score计算如下:
,其候选尾实体对应的score计算如下:
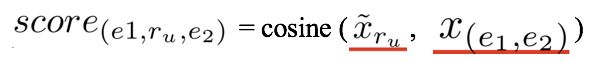
为了验证生成器的泛化能力,对于关系 r 可生成一组特征表示向量,其中的每一个与测试样本计算score之后取均值:
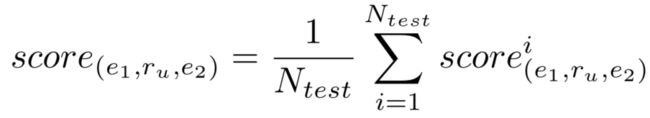
3. 实验
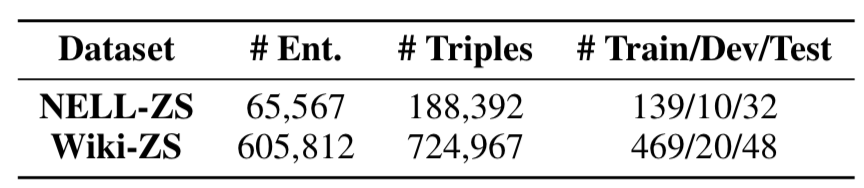
针对提出的zero shot relation learning,文章基于NELL和Wiki构建了两个数据集:NELL-ZS、Wiki-ZS,其中数据集中的每一个关系均有可获取的文本描述。其数据统计情况如下图所示:
考虑到现有的KG embedding的算法无法对unseen relation实现预测,文章提出了三种针对unseen relations改进的baselines:ZS-TransE, ZS-DistMult 和 ZS-ComplEx。这三种baseline,在原TransE, DistMult 和ComplEx算法的基础上,取代原本算法中对关系进行随机初始化的操作,利用关系的文本描述学习关系的特征表示。具体地,与生成器的输入类似,同样也使用TF-IDF加权的word embedding得到文本的表示,再经过两层全连接层得到关系的特征表示。该表示将与实体随机初始化的表示在表示学习算法score function的训练下进行优化。由此,对于unseen relations即可通过关系的文本描述得到关系的表示,从而进行链接预测等任务。
在两个数据集上对比baselines结果如下:
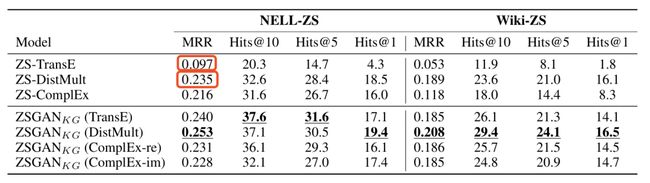
其中,ZSGAN为本文中提出的方法,ZSGAN(TransE) 等表示在2.1中特征编码时,使用TransE预训练的embedding对实体和关系进行初始化。结果表示,本文提出的ZSGAN对比baseline在两个数据集上取得了不错的效果。同时,值得注意的是,在unseen relations存在的情况下,baseline中的DistMult具有一定的学习优势。
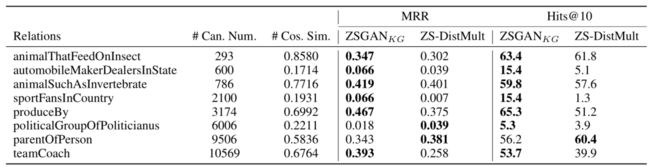
文章同时分析了生成样本的质量,具体地,计算生成的relation embedding和其对应真实样本的embedding之间的cosine距离,在一些关系上的对比结果如下所示:
4.总结
本文首次提出了知识图谱中的零样本关系学习问题,同时引入生成对抗网络以生成relation embedding的方式,解决预测时新出现的unseen relations的预测问题。
文本中蕴含的relation之间的关联信息,为seen relations和unseen relations构建了类别层面的关联,使得生成对抗网络在seen relations的训练下,可为unseen relations生成语义丰富的特征表示。
除文本描述信息外,一般的零样本学习也利用了属性描述及类别间层次关系等信息,在知识图谱零样本学习的场景中,利用一些relation间更加high-level的关系(如共现关系等)或关系间共有的属性信息,对零样本的关系学习是否有贡献也是值得思考的问题。
同时,本文将研究点关注于KG中zero-shot relation,对于KG中新出现的一些实体(即zero-shot entity)的学习也是值得探索的方向。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。