缺失值的侦测的方法:
1、mice包中的md.pattern()函数可以生成一个以矩阵或数据框形式展示缺失值模式的表格
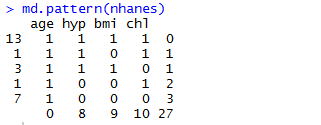
这个矩阵呢,表示像第一行缺失0个的模式有13行,像第二行缺失1个的模式有1行,如此类推
所以呢,一共就有0*13+1*1+1*3+2*1+3*7=27个缺失值,也可以算每列的,age列缺0个,hyp列缺8个,bmi列缺9个,chl列缺10个,共缺0+8+9+10=27个
2、VIM包中可可视化数据集中缺失值模式的函数:aggr()、matrixplot()、scattMiss()
aggr(nhanes,prop=FALSE,numbers=TRUE)
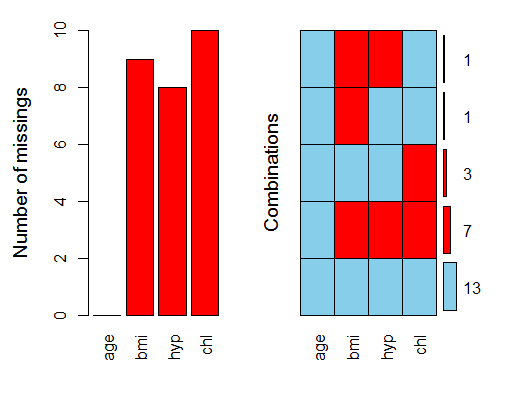
此外,当prop参数设置为true时,将用比例代替计数
matrixplot(nhanes)
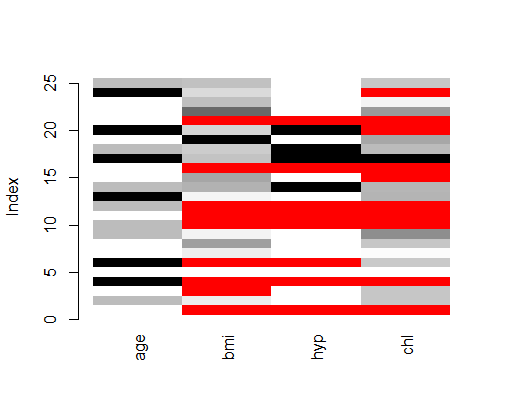
此处,缺失的地方为红色,其他的数值较小,颜色较浅;数值越大,颜色越重。
另,不适合非数值数据,会把非数值数据判断成缺失
marginplot(nhanes[c("hyp","chl")],pch=c(20),col=c("darkgray","red","blue"))

缺失值的处理一般有以下几种方法:
1、将含缺失值的记录删除
2、根据变量之间的相关关系填补缺失值
3、根据记录之间的相似性填补缺失值
4、使用能够处理缺失值的工具
将含缺失值的记录删除
一般适用于以下情况:
此条记录中含有较多变量的缺失值
得到数据中至少含有一个变量的缺失值的记录 的计数
nrow(data[!complete.cases(data),]
剔除含有缺失值的记录
data=data[complete.cases(data),]
或者
data=na.omit(data)
得到每行数据的缺失值个数
apply(data,1,function(x) sum(is.na(x)))
用最高频率值填补缺失值
填补缺失值最简便和快捷的方法是使用一些代表中心趋势的值,因为他们反映了变量分布的最常见值。例如平均值、中位数、众数等。
对于接近正态的分布来讲,平均值数就是最佳选择;
对于偏态分布或者有离群值的分布而言,中位数是更好的代表数据中心趋势的指标。
填补data的noNum列的缺失值:
data[is.na(data$noNum,"noNum"]=median(data$noNum,na.rm=T)
对于名义变量,常使用众数填补。
通过变量的相关关系来填补缺失值
缺失值为数值变量时常使用相关性计算线性回归,
缺失值为名义变量时常通过绘图观察规律进行填充。
产生变量之间的相关值
cor(data[,4:18],use="complete.obs")
改善结果输出形式:
symnum(cor(data[,4:18],use="complete.obs"))
找出相关性比较高的变量,通过线性回归对缺失值进行计算填充
填充名义变量时常用的绘图函数(lattice包):
histogram(~mxPH|season,data=algae) histogram(~mxPH|size*speed,data=algae) stripplot(size~mxPH|speed,data=algae,jitter=T)
根据记录之间的相似性填补缺失值
度量两个记录之间的相似性:欧氏距离,找出与任何含有缺失值的案例最相似的10条记录
两种方法:
1、计算这10条记录的中位数,并用中位数来填补缺失值。若为名义变量,采用众数
2、采用这些最相似数据的加权均值。权重的大小随着距待填补缺失值的个案的距离增大而减小。可采用高斯核函数从距离获得权重。若相邻个案距待填补缺失值的个案的距离为d,则它的值在加权平均中的权重为 w(d)=exp(-d)
注:在计算距离时,一般要对数值变量进行标准化。即 yi=(xi-xbar)/sigma(x)