【论文解读 WSDM 2018 | DRL】Curriculum Learning for Heterogeneous Star Network Embedding via DRL

论文链接:http://hanj.cs.illinois.edu/pdf/wsdm18_mqu.pdf
代码链接:https://github.com/mnqu/DRL
会议:WSDM 2018
本文将深度强化学习应用到了异构星型网络的表示学习中。在异构星型网络表示的学习过程中通常需要采样一系列的边来得到点之间的相似性,作者发现这些边的顺序会显著影响表示学习的效果。作者借鉴了课程学习(Curriculum Learning)的思想,研究如何在网络表示学习中学习这些边的采样顺序。该问题可以形式化为马尔可夫决策过程,作者提出了一个基于深度强化学习的解决方法。
1 摘要
本文聚焦于异构星型网络的节点表示学习问题。异构星型网络有一个中心节点,通过不同类型的边和多个不同类型的属性节点相连。在异构星型网络中,不同类型边的训练顺序会影响模型的表现效果。作者在异构星型网络的节点表示学习中,引入课程学习的思想。为节点表示学习学习到一个最优顺序的边序列。
问题可被形式化为马尔科夫决策过程,动作是为训练选择特定类型的边,状态是到目前为止选择的边的类型序列。奖励由实际任务中的准确度定义,目标是采取一系列的动作以实现最大化积累奖励。
作者提出基于深度强化学习的方法解决上述问题。利用LSTM模型编码状态(state),并估计每个状态-动作对(state-action pair)的期望累计奖励。(在节点分类任务上做了实验)
2 介绍
异构星型网络有一个中心节点,通过不同类型的边和多个不同类型的属性节点相连。许多问题都可以形式化为异构星型网络上的问题,例如author identification、predictive text embedding、user attribute prediction。下图是一个引文领域的异构星型网络:
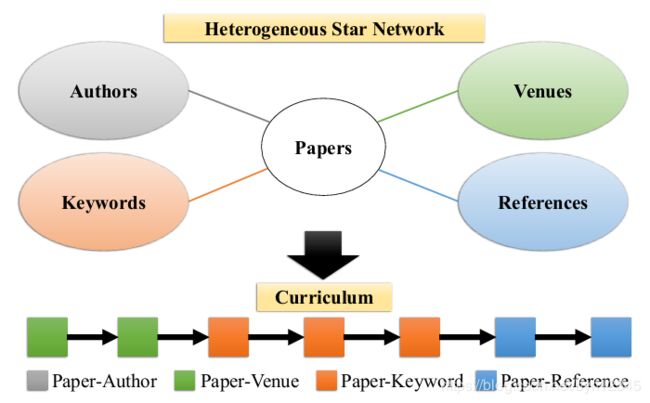
节点表示学习的关键就是获取编码在边中的节点间相似度信息,所以需要采样不同类型的边作为训练数据。现有的方法通常采用随机采样、加权采样的方式,不考虑不同类型边之间的相对顺序。然而,每种类型的边都编码了特定的知识,可能会对不同的训练步骤带来影响,也就是说边类型的训练顺序在训练中很重要。
例如上图所示,在学习paper节点的表示时,venue粗略反映了文献的类型,而keywords和references更具体地刻画了文献的语义信息。
受课程学习的启发,粗略的语义信息可能更易理解,且可能对更具体的语义信息的学习起到帮助作用。先选择简单的样本进行学习,然后逐渐增加学习难度。
2.1 动机
尽管课程学习已被广泛研究,但是在异构星型网络的节点表示学习中,如何学习到有意义的训练数据顺序,还没有被研究过。其中,课程被定义为用于训练的边类型序列。问题实际上是一个连续的决策任务,作者将其形式化为马尔科夫决策过程。每一步的动作是为训练选择特定类型的边,状态是到目前为止选择的边的类型序列。在每个状态采取了一个动作后,转移到下一个状态且得到了一个回报。目标是学习到一个边类型的序列以最大化整体的回报和。但是搜索空间是序列长度的指数倍,作者提出的方法可以有效高效地进行学习。
2.2 作者提出
基于深度强化学习的方法,进行异构星型网络的表示学习。通过估计每个状态-节点对(state-action pair)的回报值Q,学习到最优的课程序列。
Q值的学习来源于计划模块和学习模块。给定状态后,计划模块通过向前看(looking ahead)计算Q,通过模拟发掘出了子序列动作,然后用模拟出来的回报估计Q值。然而,学习模块是通过向后看(looking back)来估计Q。作者使用了LSTM模型,通过学习过去的经验进一步做预测。
使用这两个模块,可以高效准确地估计Q值。从而高效有效地学习到有意义的课程。
2.3 贡献
(1)定义了一个新问题——使用课程学习方法解决异构星型网络的节点表示学习;
(2)上上述问题形式化为马尔科夫决策过程,提出基于深度强化学习的解决方法;
(3)在真实存在的异构星型网络上进行了实验,证明了本文方法的有效性和高效性。
3 方法
3.1 问题定义
(1)异构星型网络:![]() ,
,![]() 是中心节点,
是中心节点,![]() 是和
是和![]() 相连的属性节点,
相连的属性节点,![]() 是中心节点和属性节点之间的连边,每条边都有w>0的权重,表示连接节点之间的关系强度。
是中心节点和属性节点之间的连边,每条边都有w>0的权重,表示连接节点之间的关系强度。
(2)问题定义:给定异构星型网络 和回报函数
和回报函数![]() 。对于每个状态-动作对(s, a),采取一系列的动作以最大化回报的总和,为训练过程学习到一个边类型序列。
。对于每个状态-动作对(s, a),采取一系列的动作以最大化回报的总和,为训练过程学习到一个边类型序列。
3.2 METHODOLOGY
问题形式化为马尔科夫决策过程,每一步的动作是选择一个特定类型的边(记为![]() ,
,![]() ),或者是判断终止条件(a=STOP )。状态定义为到目前为止所选边类型的序列,
),或者是判断终止条件(a=STOP )。状态定义为到目前为止所选边类型的序列,![]() 。在每个状态下完成一次动作后,会转移到下一个状态,并且通过回报函数R(s,a) ,计算得到一个回报Q(s,a) 。对于不同的任务,回报函数也不同,例如节点分类任务的回报为动作发生后的准确度增益。最终的目标是采取一系列的动作以最大化回报,为训练过程学习到一个边类型序列。
。在每个状态下完成一次动作后,会转移到下一个状态,并且通过回报函数R(s,a) ,计算得到一个回报Q(s,a) 。对于不同的任务,回报函数也不同,例如节点分类任务的回报为动作发生后的准确度增益。最终的目标是采取一系列的动作以最大化回报,为训练过程学习到一个边类型序列。
一旦学习得到Q值,就可以通过连续地选择每一步使Q最大化的动作,组成最优的动作序列。
Q值的学习来源于计划模块和学习模块。为了权衡有效性和高效性,对每个动作都有一定的惩罚。当为一个动作计算回报时,根据回报函数的计算结果,减去一个常值惩罚。小的惩罚值鼓励学习到更长的序列,这有益于有效性,但不利于高效性;大的惩罚值鼓励学习到更短的序列,这不利于有效性,但有利于高效性。
框架的整体结构如下图所示:

3.2.1 Planning Module
计划模块是从给定的状态出发向前看,模拟出子序列动作,估计Qp 的值。每次模拟时,先选择动作序列,然后使用节点表示学习算法模拟动作,并计算回报,根据回报进一步优化Qp 。具体流程如下:
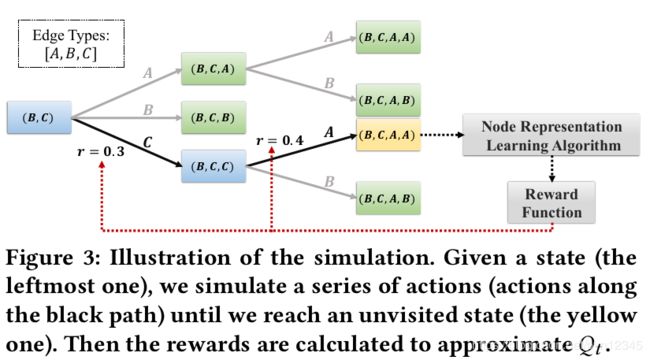
状态-动作对(state-action pair)的回报值![]() 是使用look-up table计算的。像蒙特卡洛树搜索一样,给定状态s,每次模拟都递归地选择一些动作,直到访问到未被访问的状态为止(上图中的黄色状态)。针对状态s,使用如下的公式选择动作a:
是使用look-up table计算的。像蒙特卡洛树搜索一样,给定状态s,每次模拟都递归地选择一些动作,直到访问到未被访问的状态为止(上图中的黄色状态)。针对状态s,使用如下的公式选择动作a:

![]() 分别是计划模块和学习模块计算出的Q值,N(s, a)访问次数,
分别是计划模块和学习模块计算出的Q值,N(s, a)访问次数,![]() 是状态s的访问次数和。
是状态s的访问次数和。
到达未被访问的状态后,使用节点表示算法模拟被选的动作,也就是使用相应类型的边更新节点表示,或者是终止训练过程。接着,在学习得到的节点表示上应用回报函数就可计算出回报值。基于下式,更新![]() :
:
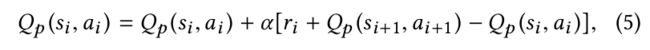
其中![]() 是学习率,
是学习率,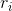 是在状态
是在状态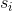 处采样动作
处采样动作 后的即时回报,
后的即时回报,![]() 是对长期回报的估计。
是对长期回报的估计。
3.2.2 Learning Module
学习模块是向后看(looking back),回看过去的经验,使用深度神经网络记忆历史数据,估计![]() 。
。
在DNN中,用向量表示每种类型的边![]() 和动作
和动作![]() 。用LSTM层编码状态
。用LSTM层编码状态![]() ,然后将状态s和动作a的编码向量拼接起来,使用两层全连接网络计算
,然后将状态s和动作a的编码向量拼接起来,使用两层全连接网络计算![]() 。网络结构如下图所示:
。网络结构如下图所示:
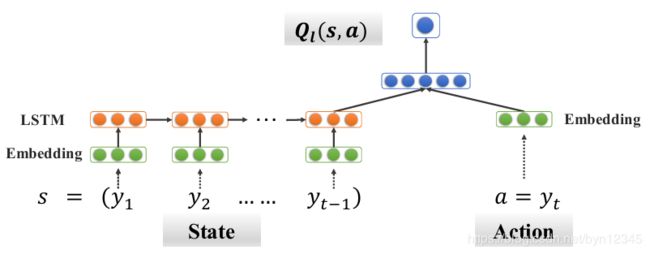
使用LSTM编码状态序列,可以有效的获取不同状态之间的相关性。基于新的状态-动作对(state-action pair)与之前的相关性,可以有效地推断出![]() 的值。
的值。
为了学习到DNN的参数,作者将计划模块模拟得到的state-action pairs和相对应的回报作为训练数据。模拟得到的state-action序列记为![]() ,相对应的回报序列记为
,相对应的回报序列记为![]() 。基于下式进行参数更新:
。基于下式进行参数更新:
![]()
3.2.3 整合两个模块
给定当前状态s,为动作a计算回报值:
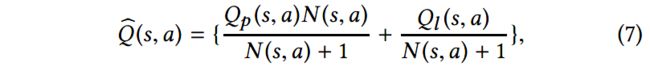
![]() 是基于前向搜索的,相对更精确,所以在式中占更大的权重。Ql
是基于前向搜索的,相对更精确,所以在式中占更大的权重。Ql![]() 是基于过去的经验进行学习的,权重值会随着访问次数的增加而减小。
是基于过去的经验进行学习的,权重值会随着访问次数的增加而减小。
回报值Q估计了在状态s采取动作a的回报期望,让Q最大的动作![]() 是当前步骤的最好选择。选择动作
是当前步骤的最好选择。选择动作![]() 也就是为节点表示学习选择了合适的边类型,或者是实现了训练过程的终止条件。
也就是为节点表示学习选择了合适的边类型,或者是实现了训练过程的终止条件。
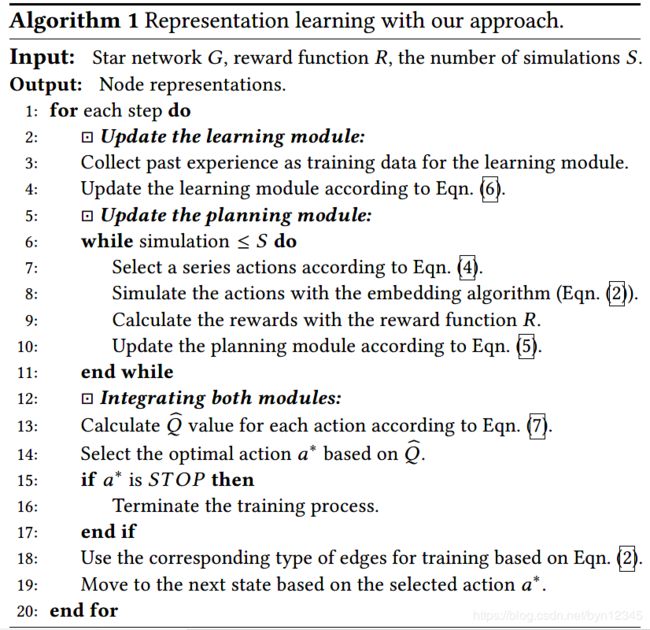
本文提出的基于课程学习的节点表示学习过程,整体算法如下:
4 实验
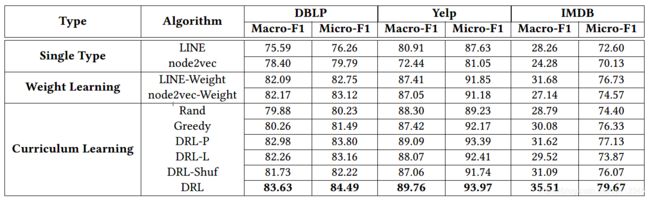
数据集:DBLP、Yelp、IMDB
实验任务:中心节点分类任务(有监督和无监督两种实验设置)
对比方法:
(1)LINE和node2vec都是用于同质图的方法,为了适用于本文工作的异构星型网络,作者给不同类型的边赋予了不同的权重。
(2)Rand:在每步训练选择不同类型的边,并使用LINE学习节点的表示。
(3)Greedy:根据每步最大的即时回报,贪婪地选择动作,并使用LINE学习节点表示。
(4)DRL:使用本文的深度强化学习的方法,学习得到合适的序列,并使用LINE学习节点表示。
(5)DRL-Shuf:打乱本文方法学习到的序列,并使用LINE学习节点表示。
(6)DRL-P:只使用计划模块,学习模块的回报值保持为0。
(7)DRL-L:只使用学习模块,计划模块的回报值保持为0。
实验结果:
无监督设置下的实验结果如下:

半监督设置下的实验结果如下:
5 总结
本文的工作是针对异构星型网络的节点表示学习。
前人的方法都没有考虑到不同类型边的训练顺序,作者的动机就是学习到有意义的不同类型边的训练顺序,以提高表示学习的能力。
作者使用深度强化学习的方法解决了这一问题,具体来讲用的是课程学习(curriculum learning)的方法,并且使用了强化学习中的学习(learning)和计划(planning)策略。第一个将课程学习,应用到了异构星型网络的节点表示学习上。
本文的工作是针对异构星型网络的,课程(curriculum)指的是边类型的序列。作者考虑未来将这一框架扩展至一般的异构网络中,那时的课程就可以定义成meta-path的序列,或者hyper-edges的序列。
研究的问题很有新意,想到的解决方法(课程学习)也很有新意。本文在HIN表示学习的具体贡献体现在模型的训练过程中,即如何获取更有效的按照一定顺序的训练数据,以优化模型的节点表示学习能力。并没有像以往大多数的论文一样,提出更好的HIN嵌入学习方法。但作者的想法还是非常有新意的。