泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练

©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加 Dropout 以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往 loss 里边添加正则项,比如 , 惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。

随机噪声
我们记模型为 f(x), 为训练数据集合,l(f(x), y) 为单个样本的 loss,那么我们的优化目标是:

是 f(x) 里边的可训练参数。假如往模型输入添加噪声 ,其分布为 ,那么优化目标就变为:
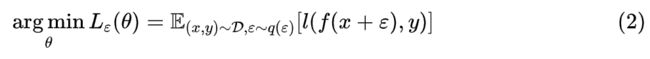
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重 ,甚至可以是输出 y(等价于标签平滑),噪声也不一定是加上去的,比如 Dropout 是乘上去的。对于加性噪声来说, 的常见选择是均值为 0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布 U([0,1]) 或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。

提高效率
添加随机噪声的方式容易实现,而且在不少情况下确实也很有效,但它有一个明显的缺点:不够“特异性”。噪声 是随机的,而不是针对 x 构建的,这意味着多数情况下 可能只是一个平凡样本,也就是没有对原模型造成比较明显的扰动,所以对泛化性能的提高帮助有限。
增加采样
从理论上来看,加入随机噪声后,单个样本的 loss 变为:
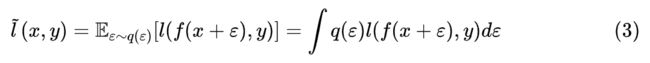
但实践上,对于每个特定的样本 (x,y),我们一般只采样一个噪声,所以并没有很好地近似上式。当然,我们可以采样多个噪声 ,然后更好地近似:

但这样相当于 batch_size 扩大为原来的 k 倍,增大了计算成本,并不是那么友好。
近似展开
一个直接的想法是,如果能事先把式 (3) 中的积分算出来,那就用不着低效率地采样了(或者相当于一次性采样无限多的噪声)。我们就往这个方向走一下试试。当然,精确的显式积分基本上是做不到的,我们可以做一下近似展开:
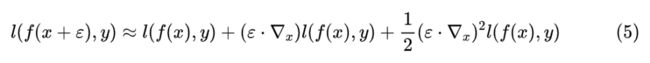
然后两端乘以 积分,这里假设 的各个分量是独立同分布的,并且均值为 0、方差为 ,那么积分结果就是:
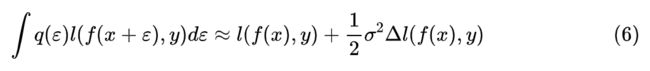
这里的 是拉普拉斯算子,即 。这个结果在形式上很简单,就是相当于往 loss 里边加入正则项 ,然而实践上却相当困难,因为这意味着要算 l 的二阶导数,再加上梯度下降,那么就一共要算三阶导数,这是现有深度学习框架难以高效实现的。

转移目标
直接化简 的积分是行不通了,但我们还可以试试将优化目标换成:
![]()
也就是变成同时缩小 、 的差距,两者双管齐下,一定程度上也能达到缩小 差距的目标。关键的是,这个目标能得到更有意思的结果。
思路解析
用数学的话来讲,如果 l 是某种形式的距离度量,那么根据三角不等式就有:
![]()
如果 l 不是度量,那么通常根据詹森不等式也能得到一个类似的结果,比如 ,那么我们有:
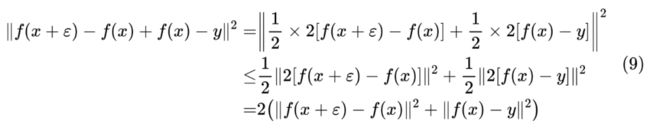
这也就是说,目标 (7)(的若干倍)可以认为是 的上界,原始目标不大好优化,所以我们改为优化它的上界。
注意到,目标 (7) 的两项之中, 衡量了模型本身的平滑程度,跟标签没关系,用无标签数据也可以对它进行优化,这意味着它可以跟带标签的数据一起,构成一个半监督学习流程。
勇敢地算
对于目标 (7) 来说,它的积分结果是:
![]()
还是老路子,近似展开 :
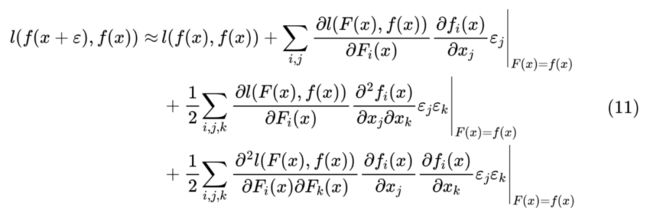
很恐怖?不着急,我们回顾一下,作为 loss 函数的 l,它一般会有如下几个特点:
1. l是光滑的;
2. l(x, x)=0;
3. 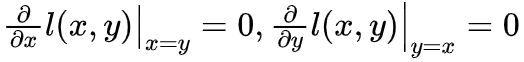 。
。
这其实就是说 l 是光滑的,并且在 x=y 的时候取到极(小)值,且极(小)值为 0,这几个特点几乎是所有 loss 的共性了。基于这几个特点,恐怖的 (11) 式的前三项就直接为 0 了,所以最后的积分结果是:

梯度惩罚
看上去依然让人有些心悸,但总比 (11) 好多了。上式也是一个正则项,其特点是只包含一阶梯度项,而对于特定的损失函数, 可以提前算出来,我们记为 ,那么:
![]()
这其实就是对每个 f(x) 的每个分量都算一个梯度惩罚项 ,然后按 加权求和。
对于 MSE 来说, ,这时候可以算得 ,所以对应的正则项为 ;对于 KL 散度来说,,这时候 ,那么对应的正则项为 。
这些结果大家多多少少可以从著名的“花书”《深度学习》[1] 中找到类似的,所以并不是什么新的结果。类似的推导还可以参考文献 Training with noise is equivalent to Tikhonov regularization [2]。
采样近似
当然,虽然能求出只带有一阶梯度的正则项 ,但事实上这个计算量也不低,因为需要对每个 都要求梯度,如果输出的分量数太大,这个计算量依然难以承受。
这时候可以考虑的方案是通过采样近似计算:假设 是均值为 0、方差为 1 的分布,那么我们有:
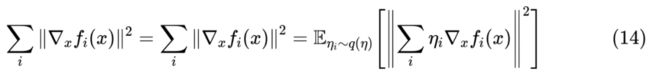
这样一来,每步我们只需要算 的梯度,不需要算多次梯度。 的一个最简单的取法是空间为 的均匀分布,也就是 等概率地从 中选取一个。

对抗训练
回顾前面的流程,我们先是介绍了添加随机噪声这一增强泛化性能的手段,然后指出随机加噪声可能太没特异性,所以想着先把积分算出来,才有了后面推导的关于近似展开与梯度惩罚的一些结果。那么换个角度来想,如果我们能想办法更特异性地构造噪声信号,那么也能提高训练效率,增强泛化性能了。
监督对抗
有监督的对抗训练,关注的是原始目标 (3),优化的目标是让 loss 尽可能小,所以如果我们要选择更有代表性的噪声,那么应该选择能让 loss 变得更大的噪声,而:
![]()
所以让 尽可能大就意味着 要跟 同向,换言之扰动要往梯度上升方向走,即:
这便构成了对抗训练中的 FGM 方法,之前在对抗训练浅谈:意义、方法和思考(附Keras实现)就已经介绍过了。
值得注意的是,在对抗训练浅谈:意义、方法和思考(附Keras实现)一文中我们也推导过,对抗训练在一定程度上也等价于往 loss 里边加入梯度惩罚项 ,这又跟前一节的关于噪声积分的结果类似。这表明梯度惩罚应该是通用的能提高模型性能的手段之一。
虚拟对抗
在前面我们提到, 这一项不需要标签信号,因此可以用来做无监督学习,并且关于它的展开高斯积分我们得到了梯度惩罚 (13)。
如果沿着对抗训练的思想,我们不去计算积分,而是去寻找让 尽可能大的扰动噪声,这就构成了“虚拟对抗训练(VAT)”,首次出现在文章 Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning [3] 中。
基于前面对损失函数 l 的性质的讨论,我们知道 关于 的一阶梯度为 0,所以要算对抗扰动,还必须将它展开到二阶:
![]()
这里用 表示不需要对里边的 x 求梯度。这样一来,我们需要解决两个问题:
1. 如何高效计算 Hessian 矩阵 ;
2. 如何求单位向量 u 使得 最大?
事实上,不难证明 u 的最优解实际上就是“ 的最大特征根对应的特征向量”,也称为“ 的主特征向量”,而要近似求主特征向量,一个行之有效的方法就是“幂迭代法 [4]”:
从一个随机向量 出发,迭代执行 。相关推导可以参考深度学习中的Lipschitz约束:泛化与生成模型的“主特征根”和“幂迭代”两节。
在幂迭代中,我们发现并不需要知道 具体值,只需要知道 的值,这可以通过差分来近似计算:
![]()
其中 是一个标量常数。根据这个近似结果,我们就可以得到如下的 VAT 流程:
初始化向量 、标量 和 ;
迭代 r 次:
用 作为 loss 执行常规梯度下降。
实验表明一般迭代 1 次就不错了,而如果迭代 0 次,那么就是本文开头提到的添加高斯噪声。这表明虚拟对抗训练就是通过 来提高噪声的“特异性”的。
参考实现
关于对抗训练的 Keras 实现,在对抗训练浅谈:意义、方法和思考(附Keras实现)一文中已经给出过,这里笔者给出 Keras 下虚拟对抗训练的参考实现:
def virtual_adversarial_training(
model, embedding_name, epsilon=1, xi=10, iters=1
):
"""给模型添加虚拟对抗训练
其中model是需要添加对抗训练的keras模型,embedding_name
则是model里边Embedding层的名字。要在模型compile之后使用。
"""
if model.train_function is None: # 如果还没有训练函数
model._make_train_function() # 手动make
old_train_function = model.train_function # 备份旧的训练函数
# 查找Embedding层
for output in model.outputs:
embedding_layer = search_layer(output, embedding_name)
if embedding_layer is not None:
break
if embedding_layer is None:
raise Exception('Embedding layer not found')
# 求Embedding梯度
embeddings = embedding_layer.embeddings # Embedding矩阵
gradients = K.gradients(model.total_loss, [embeddings]) # Embedding梯度
gradients = K.zeros_like(embeddings) + gradients[0] # 转为dense tensor
# 封装为函数
inputs = (
model._feed_inputs + model._feed_targets + model._feed_sample_weights
) # 所有输入层
model_outputs = K.function(
inputs=inputs,
outputs=model.outputs,
name='model_outputs',
) # 模型输出函数
embedding_gradients = K.function(
inputs=inputs,
outputs=[gradients],
name='embedding_gradients',
) # 模型梯度函数
def l2_normalize(x):
return x / (np.sqrt((x**2).sum()) + 1e-8)
def train_function(inputs): # 重新定义训练函数
outputs = model_outputs(inputs)
inputs = inputs[:2] + outputs + inputs[3:]
delta1, delta2 = 0.0, np.random.randn(*K.int_shape(embeddings))
for _ in range(iters): # 迭代求扰动
delta2 = xi * l2_normalize(delta2)
K.set_value(embeddings, K.eval(embeddings) - delta1 + delta2)
delta1 = delta2
delta2 = embedding_gradients(inputs)[0] # Embedding梯度
delta2 = epsilon * l2_normalize(delta2)
K.set_value(embeddings, K.eval(embeddings) - delta1 + delta2)
outputs = old_train_function(inputs) # 梯度下降
K.set_value(embeddings, K.eval(embeddings) - delta2) # 删除扰动
return outputs
model.train_function = train_function # 覆盖原训练函数
# 写好函数后,启用虚拟对抗训练只需要一行代码
virtual_adversarial_training(model_vat, 'Embedding-Token')完整的使用脚本请参考:
https://github.com/bojone/bert4keras/blob/master/examples/task_sentiment_virtual_adversarial_training.py
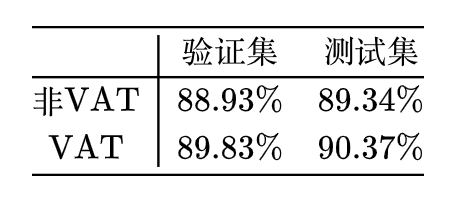
大概是将模型建立两次,一个模型通过标注数据正常训练,一个模型通过无标注数据虚拟对抗训练,两者交替执行,请读懂源码后再使用,不要乱套代码。实验任务为情况分类,大约有 2 万的标注数据,取前 200 个作为标注样本,剩下的作为无标注数据,VAT 和非 VAT 的表现对比如下(每个实验都重复了三次,取平均):

文章小结
本文先介绍了添加随机噪声这一常规的正则化手段,然后通过近似展开与积分的过程,推导了它与梯度惩罚之间的联系,并从中引出了可以用于半监督训练的模型平滑损失,接着进一步联系到了监督式的对抗训练和半监督的虚拟对抗训练,最后给出了 Keras 下虚拟对抗训练的实现和例子。
参考链接
[1] https://book.douban.com/subject/27087503/
[2] https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/bishop-tikhonov-nc-95.pdf
[3] https://arxiv.org/abs/1704.03976
[4] https://en.wikipedia.org/wiki/Power_iteration
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
