数据分析——以斗鱼为实例解析requests库与scrapy框架爬虫技术
按照我的理解,数据分析大概整体分为5大模块——数据收集、数据清洗、数据挖掘、数据建模、数据应用。
今天,我便“开车”进军第一大模块!数据收集!!!!
数据收集,通俗一点即爬虫技术,即利用脚本模拟浏览器行为向服务器发送请求并快速获取数据的过程。利用Python可以十分简单的制作一个爬虫(随便一搜,代码就哗哗嘀),因此我在这里就不赘述如何去写一个简单的爬虫了。这篇文章我将倾向于如何分别利用requests库和scrapy框架去完成相同数据的爬取,让大家看到两种方法各自的优缺点,尽量通俗易懂的为大家说明,我选取的是爬取斗鱼直播平台中主播的图片。
注:有任何问题,也欢迎大家在下面留言,随时与我交流。好啦,接下来开始开车啦!
一、requests库爬取斗鱼主播图片
1、requests库操作简介
1)session:开启会话。一般首先均会开启会话,并在会话上进行操作。
2)get(url, params=None):获取网页,允许使用params关键字,即支持以字典格式传递参数。其下常用的有:
.url:获取请求的url
.text:获取响应内容
.status_code:返回请求状态码;如 200表示成功,404表示用户端错误等。
.json:返回的内容转换为dict格式。
.encoding:返回响应内容的编码格式,也可以直接对其赋值改变编码格式。
.headers:返回响应头内容。
.cookies:返回cookies内容。
3)post(url, data, json):发送请求。若数据为字典,则用data参数传;若为json,则用json参数传。
注:字典与json可用json.dump()转换,不知道的同学可以去大致学习一下json库中的dumps与loads。
具体代码如下:
#coding=utf-8
import requests
import os
import json
s = requests.session()
offset = 0
url = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=" + str(offset)
htmltext = s.get(url).text
htmltext = json.loads(htmltext.encode("utf-8"))
while True:
if len(htmltext['data']) != 0 :
for data in htmltext['data']:
nickname = data['nickname']
f = open("./Image/" + nickname + ".jpg", "w")
imageLink = data['vertical_src']
f.write(s.get(imageLink).content)
offset += 20
url = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=" + str(offset)
htmltext = s.get(url).text
htmltext = json.loads(htmltext.encode("utf-8"))
else:
break
二、scrapy框架爬取斗鱼主播图片
1、scrapy结构简单讲解
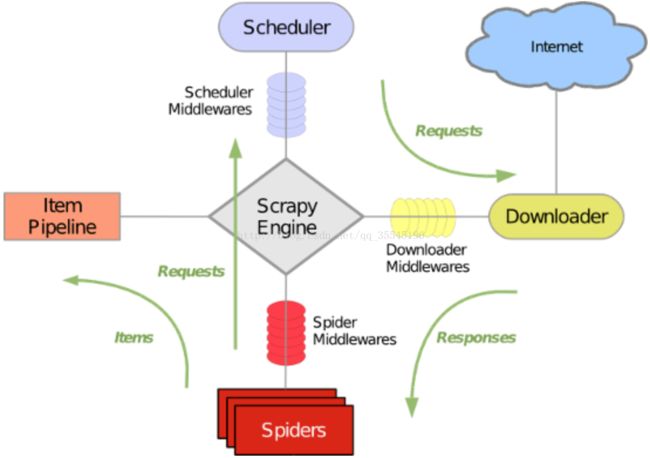
第一眼看上去你肯定和当初的我一样懵逼!这尼玛是个什么东西?僵尸符嘛嘛嘛嘛嘛!!!不要慌!我下面这段解释很重要:
上图即Scrapy的主要结构:首先,scrapy解析器会从Spiders文件出发,将里面的请求交给Scheduler,然后Scheduler将请求给Downloader去下载,将下载到的数据再交还给Spiders。根据咱们自己所写的Spiders文件,将我们需要的数据交给Item Pipeline保存,如果在Spider文件中还有别的请求(爬取到的请求或者原始你就有很多要爬取的网站),Spider便再将这些请求给Scheduler,又开始了上面的循环,直到所有请求结束。
敲黑板! 敲黑板!!!有很多同学混乱是因为他不知道调度器和引擎是什么,其实咱们并不用知道那是什么,因为这两个东西在你写scrapy时基本不会出现,所以你要知道的就只是我上面的解释即可!完全够写scrapy用的啦!
爬虫创建:用 scrapy startproject XXX 命令,在相对应的路径下创建一个名为XXX的scrapy框架。再输入scrapy genspider XXX 域名,完成爬虫的创建,其中XXX为爬虫名,域名即为爬取的目标网站。
2、scrapy各文件编写
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DouyuItem(scrapy.Item):
nickname = scrapy.Field()
vertical_src = scrapy.Field()# -*- coding: utf-8 -*-
import scrapy
from Douyu.items import DouyuItem
import json
class DouyuSpider(scrapy.Spider):
name = 'douyu'
allowed_domains = ['http://www.douyu.com']
base_url = 'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset='
offset = 0
start_urls = [base_url + str(offset)]
def parse(self, response):
data_list = json.loads(response.body)["data"]
if len(data_list) == 0:
return
for data in data_list:
item = DouyuItem()
item['nickname'] = data['nickname'].encode("utf-8")
item['vertical_src'] = data['vertical_src']
yield item
self.offset += 20
url = self.base_url + str(self.offset)
yield scrapy.Request(url, callback=self.parse,dont_filter=True)# -*- coding: utf-8 -*-
import scrapy
from scrapy.pipelines.images import ImagesPipeline
import os
class DouyuPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
image_link = item['vertical_src']
yield scrapy.Request(image_link)
def item_completed(self, result, item, info):
path = '/Users/yixiong_bian/Desktop/Douyu主播图片爬取/Douyu/Image/'
if result[0][0] == True:
os.rename(path + result[0][1]['path'], path + str(item['nickname'] + ".jpg"))
return itemBOT_NAME = 'Douyu'
SPIDER_MODULES = ['Douyu.spiders']
NEWSPIDER_MODULE = 'Douyu.spiders'
IMAGES_STORE = '/Users/yixiong_bian/Desktop/Douyu主播图片爬取/Douyu/Image'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# item pipelines
ITEM_PIPELINES = {
'Douyu.pipelines.DouyuPipeline': 300,
}三、requests与scrapy对比