Flink零基础教程:并行度和数据重分布
Flink的Transformation转换主要包括四种:单数据流基本转换、基于Key的分组转换、多数据流转换和数据重分布转换。读者可以使用Flink Scala Shell或者Intellij Idea来进行练习:
-
Flink Scala Shell使用教程
-
Intellij Idea开发环境搭建教程
-
Flink单数据流基本转换:map、filter、flatMap
-
Flink基于Key的分组转换:keyBy、reduce和aggregations
-
Flink多数据流转换:union和connect
并行度
Flink使用并行度来定义某个算子被切分为多少个算子子任务。我们编写的大部分Transformation转换操作能够形成一个逻辑视图,当实际运行时,逻辑视图中的算子会被并行切分为一到多个算子子任务,每个算子子任务处理一部分数据。如下图所示,各个算子并行地在多个子任务上执行,假如算子的并行度为2,那么它有两个实例。
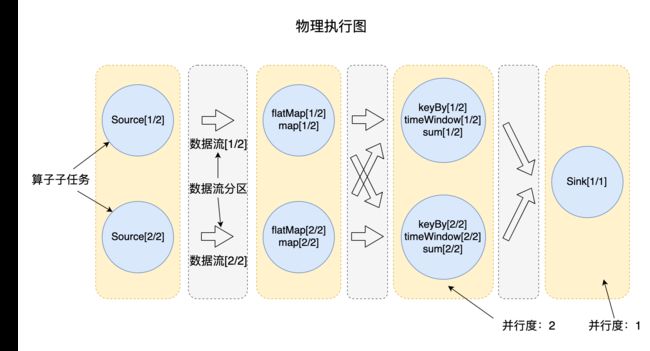
并行度可以在一个Flink作业的执行环境层面统一设置,这样将设置该作业所有算子并行度,也可以对某个算子单独设置其并行度。如果不进行任何设置,默认情况下,一个作业所有算子的并行度会依赖于这个作业的执行环境。如果一个作业在本地执行,那么并行度默认是本机CPU核心数。当我们将作业提交到Flink集群时,需要使用提交作业的客户端,并指定一系列参数,其中一个参数就是并行度。
下面的代码展示了如何获取执行环境的默认并行度,如何更改执行环境的并行度。
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 获取当前执行环境的默认并行度
val defaultParallelism = senv.getParallelism
// 设置所有算子的并行度为4,表示所有算子的并行执行的实例数为4
senv.setParallelism(4)
也可以对某个算子设置并行度:
dataStream.map(new MyMapper).setParallelism(defaultParallelism * 2)
数据重分布
默认情况下,数据是自动分配到多个实例上的。有的时候,我们需要手动对数据在多个实例上进行分配,例如,我们知道某个实例上的数据过多,其他实例上的数据稀疏,产生了数据倾斜,这时我们需要将数据均匀分布到各个实例上,以避免部分实例负载过重。数据倾斜问题会导致整个作业的计算时间过长或者内存不足等问题。
下文涉及到的各个数据重分布算子的输入是DataStream,输出也是DataStream。keyBy也有对数据进行分组和数据重分布的功能,但keyBy输出的是KeyedStream。
shuffle
shuffle基于正态分布,将数据随机分配到下游各算子实例上。
dataStream.shuffle()
rebalance与rescale
rebalance使用Round-ribon思想将数据均匀分配到各实例上。Round-ribon是负载均衡领域经常使用的均匀分配的方法,上游的数据会轮询式地分配到下游的所有的实例上。如下图所示,上游的算子会将数据依次发送给下游所有算子实例。
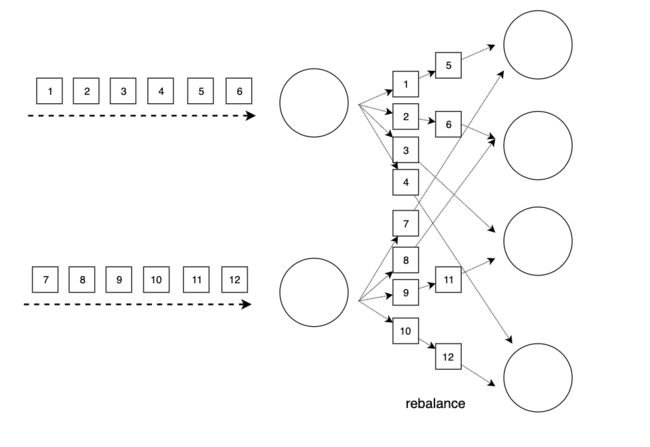
dataStream.rebalance()
rescale与rebalance很像,也是将数据均匀分布到各下游各实例上,但它的传输开销更小,因为rescale并不是将每个数据轮询地发送给下游每个实例,而是就近发送给下游实例。
dataStream.rescale()
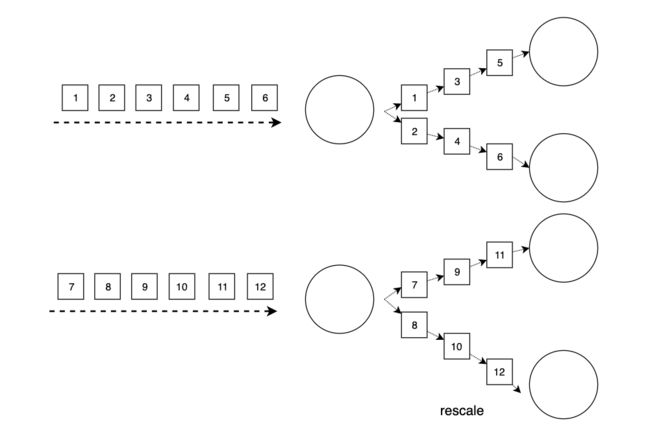
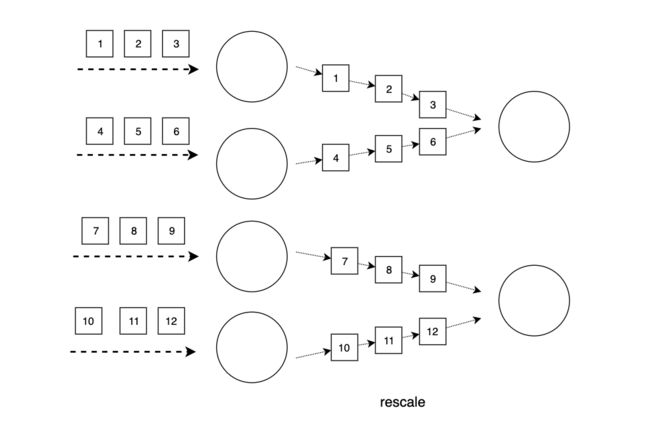
如上图所示,当上游有两个实例时,上游第一个实例将数据发送给下游第一个和第二个实例,上游第二个实例将数据发送给下游第三个和第四个实例,相比rebalance将数据发送给下游每个实例,rescale的传输开销更小。下图则展示了当上游有四个实例,上游前两个实例将数据发送给下游第一个实例,上游后两个实例将数据发送给下游第二个实例。
broadcast
英文单词"broadcast"翻译过来为广播,在Flink里,数据会被复制并广播发送给下游的所有实例上。
dataStream.broadcast()
global
global会所有数据发送给下游算子的第一个实例上,使用这个算子时要小心,以免造成严重的性能问题。
dataStream.global()
partitionCustom
我们也可以使用partitionCustom来自定义数据重分布逻辑。partitionCustom有两个参数:第一个参数是自定义的Partitioner,我们需要重写里面的partition函数;第二个参数是对数据流哪个字段使用partiton逻辑。partition函数的返回一个整数,表示该元素将被路由到下游第几个实例。
Partitioner[T]中泛型T为指定的字段类型,比如我们要对case class (id: Long, name: String, score: Double)这个数据结构按照id均匀分配到下游各实例,那么泛型T就为id的数据类型Long。同时,泛型T也是partition(key, numPartitions)函数的第一个参数的数据类型。在调用partitionCustom(partitioner, field)时,第一个参数是我们重写的Partitioner,第二个参数表示按照id字段进行处理。
下面的代码按照数据流中的第二个字段进行数据重分布,当该字段中包含数字时,将被路由到下游算子的前半部分,否则被路由到后半部分。如果设置并行度为4,表示所有算子的实例数为4,或者说有4个分区,那么如果字符串包含数字时,该元素将被分配到第0个和第1个实例上,否则被分配到第2个和第3个实例上。
package com.flink.tutorials.api.transformations
import org.apache.flink.api.common.functions.Partitioner
import org.apache.flink.streaming.api.scala._
object PartitionCustomExample {
/**
* Partitioner[T] 其中泛型T为指定的字段类型
* 重写partiton函数,并根据T字段对数据流中的所有元素进行数据重分配
* */
class MyPartitioner extends Partitioner[String] {
val rand = scala.util.Random
/**
* key 泛型T 即根据哪个字段进行数据重分配,本例中是(Int, String)中的String
* numPartitons 为当前有多少个并行实例
* 函数返回值是一个Int 为该元素将被发送给下游第几个实例
* */
override def partition(key: String, numPartitions: Int): Int = {
var randomNum = rand.nextInt(numPartitions / 2)
// 如果字符串中包含数字,该元素将被路由到前半部分,否则将被路由到后半部分。
if (key.exists(_.isDigit)) {
return randomNum
} else {
return randomNum + numPartitions / 2
}
}
}
def main(args: Array[String]): Unit = {
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 获取当前执行环境的默认并行度
val defaultParalleism = senv.getParallelism
// 设置所有算子的并行度为4,表示所有算子的并行执行的实例数为4
senv.setParallelism(4)
val dataStream: DataStream[(Int, String)] = senv.fromElements((1, "123"), (2, "abc"), (3, "256"), (4, "zyx")
, (5, "bcd"), (6, "666"))
// 对(Int, String)中的第二个字段使用 MyPartitioner 中的重分布逻辑
val partitioned = dataStream.partitionCustom(new MyPartitioner, 1)
partitioned.print()
senv.execute("partition custom transformation")
}
}