中文短文本分类实例十四-LEAM(Joint Embedding of Words and Labels for Text Classification)
一.概述
LEAM(Joint Embedding of Words and Labels for Text Classification),是Guoyin Wang等提出的一种文本分类新方法,看论文标题就可以发现,该方法主要是构建 "类别标签 (label) 与词向量 (word-embedding)的联合嵌入",使用注意力机制 (Attention) 作为 laebl 与 word-embedding 沟通的桥梁。通常其他算法如TextCNN,FastText,TextRCNN,HAN等,只把类别标签 (label)作用于网络的最后一层,即计算loss等的时候使用,LEAM等大约可以看成是引入 类别标签(label) 信息吧。
类别标签 (label) 嵌入信息是有效的,在图像领域,图像与文本的多任务领域,图像中识别文本等。特别是少样本 (zero-shot) 问题,嵌入空间中捕获的标签相关性, 可以在某些类不可见时增强预测效果。在NLP领域,类别标签 (label) 与 词 (word)的关系,之前一般认为没什么大用,如 2015年论文 Pte: Predictive text embedding through large-scale heterogeneous text networks 构建的词-词、词-文档、词-类别标签异构网络,试图构建各种关系获取更多的信息;
又如2017年等的论文MTLE: Multi-Task Label Embedding for Text Classification,使用文本分类中的多任务学习利用隐式相关任务之间的相关性以提取共同特征并产生绩效收益,其提出的一种多任务标签嵌入的方法,将文本分类中的标签转化为语义标签向量,从而将原始任务转换为向量匹配任务。其实现了多任务标签嵌入的无监督、有监督和半监督模型,所有这些模型都利用了任务之间的语义相关性,以便于在涉及更多任务时进行缩放和转移。
LEAM网络与其上的方法不同,在BERT兴起后,Tranformer成为迄今为止最好的NLP特征抽取工具,LEAM也果断使用注意力机制Attention构建label与word-embedding的关系。注意力机制(Attention)的表示方法有三种:点乘相似度、权重和余弦相似度,如Transformer使用的是KVQ的权重法,又如使用的是,这种一步到位、端到端的构建方法,使得LEAM达到了较好的效果。此外,LEAM的副产品还可以突出医学文本的关键词信息。
github地址: https://github.com/yongzhuo/Keras-TextClassification
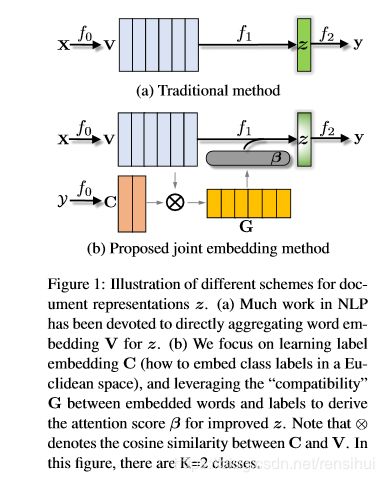
二.LEAM原理图
2.1 LEAM网络核心架构
 l
l
2.2 基本计算
2.2.1 C * V / G

C是一个需要训练的weight (tendorflow用tf.add_weight),C的转置维度为词向量维度(embed_size) * 类别数(label) ,
V是普通的word-embedding,维度为 批尺寸(batch-size) * 文本长度(len_max) * 词向量维度 (embed_size),
G是需要训练的矩阵,维度为 批尺寸(batch-size) * 文本长度(len_max) * 类别数(label)
2.2.2 其他操作

三.LEAM代码实现
3.1 github地址: https://github.com/yongzhuo/Keras-TextClassification
LEAM代码比较麻烦,用到了tensorflow,构建了一个专门的Layer
from keras.regularizers import L1L2, Regularizer
# from keras.engine.topology import Layer
from keras.layers import Layer
from keras import backend as K
import tensorflow as tf
class CVG_Layer(Layer):
def __init__(self, embed_size, filter, label, **kwargs):
self.embed_size = embed_size
self.filter = filter
self.label = label
super().__init__(** kwargs)
def build(self, input_shape):
self._filter = self.add_weight(name=f'filter_{self.filter}',
shape=(self.filter, self.label, 1, 1),
regularizer=L1L2(0.00032),
initializer='uniform',
trainable=True)
self.class_w = self.add_weight(name='class_w',
shape=(self.label, self.embed_size),
regularizer=L1L2(0.0000032),
initializer='uniform',
trainable=True)
self.b = self.add_weight(name='bias',
shape=(1,),
regularizer=L1L2(0.00032),
initializer='uniform',
trainable=True)
super().build(input_shape)
def call(self, input):
# C * V / G
# l2_normalize of x, y
input_norm = tf.nn.l2_normalize(input) # b * s * e
class_w_relu = tf.nn.relu(self.class_w) # c * e
label_embedding_reshape = tf.transpose(class_w_relu, [1, 0]) # e * c
label_embedding_reshape_norm = tf.nn.l2_normalize(label_embedding_reshape) # e * c
# C * V
G = tf.contrib.keras.backend.dot(input_norm, label_embedding_reshape_norm) # b * s * c
G_transpose = tf.transpose(G, [0, 2, 1]) # b * c * s
G_expand = tf.expand_dims(G_transpose, axis=-1) # b * c * s * 1
# text_cnn
conv = tf.nn.conv2d(name='conv', input=G_expand, filter=self._filter,
strides=[1, 1, 1, 1], padding='SAME')
pool = tf.nn.relu(name='relu', features=tf.nn.bias_add(conv, self.b)) # b * c * s * 1
# pool = tf.nn.max_pool(name='pool', value=h, ksize=[1, int((self.filters[0]-1)/2), 1, 1],
# strides=[1, 1, 1, 1], padding='SAME')
# max_pool
pool_squeeze = tf.squeeze(pool, axis=-1) # b * c * s
pool_squeeze_transpose = tf.transpose(pool_squeeze, [0, 2, 1]) # b * s * c
G_max_squeeze = tf.reduce_max(input_tensor=pool_squeeze_transpose, axis=-1, keepdims=True) # b * s * 1
# divide of softmax
exp_logits = tf.exp(G_max_squeeze)
exp_logits_sum = tf.reduce_sum(exp_logits, axis=1, keepdims=True)
att_v_max = tf.div(exp_logits, exp_logits_sum)
# β * V
x_att = tf.multiply(input, att_v_max)
x_att_sum = tf.reduce_sum(x_att, axis=1)
return x_att_sum
def compute_output_shape(self, input_shape):
return None, K.int_shape(self.class_w)[1]希望对你有所帮助!