利用python进行数据分析——之数据结构pandas(一)
这一系列的文章主要是自己读《利用python进行数据分析》所做的总结,详细内容可以参考这本书,本系列主要做梳理和简化,本章主要介绍pandas的文件读写函数和常用的数据分析处理函数,pandas和numpy一样都是python中非常常用的库。
1、pandas的文件读函数
1.1、read_csv()函数。用于读取csv文件的函数:默认的分隔符为逗号,得到的df是pandas的DataFrame数据结构格式。
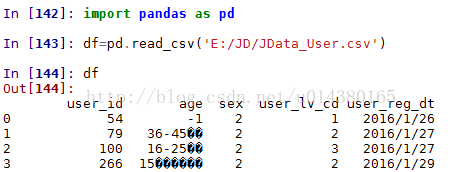
可以看到如果你原始表格带有列名,那么默认方式读入的话会沿用这个列名。如果你原始表格没有列名,那么需要加上关键字header=None或添加新的列名,这样你表格中的所有内容都将当做是DataFrame的内容:
![]()

读大型文件的话,可以限制读入的行数:
![]()
1.2、read_table()函数。默认分隔符为制表符("\t")。也可以用read_table()来读csv文件,不过要指定分隔符。
![]()
1.3、json.load()函数
该函数主要用于读取json文件数据,一个json文件数据的例子如下:

读取函数如下:
![]()
2、pandas的文件写函数
主要是DataFrame的to_csv方法,用于写到csv文件,默认也是写成逗号分隔符。
![]()
另外默认写入的话会将index也写入csv文件,如下图中的第一列。

因此如果不希望有这一列,可以加上
![]()
这样得到的表就没有第一列的index。当然还可以加上关键字header=False,可以去掉第一行的列名,但是一般不会这样做。
还有就是在写入的时候可以指定写入分隔符,如‘|’,不过一般还是默认的逗号分隔符用的比较多
![]()
3、pandas常用的数据处理函数或方法
3.1、merge函数
这个函数主要用于连接表,表为pandas的DataFrame格式,有点像SQL里面的Join。merge函数默认的连接方式为内连接,如下图:

除了默认的内连接外,还可以左连接,右连接和外连接,如下图:

另外merge函数还可以进行多键连接,例如要按两个键进行合并,只需要将on改为on=['key1','key2']即可
3.2、drop_duplicates方法
DataFrame的drop_duplicates方法主要用于过滤掉重复列。如下图创建了一个DataFrame,然后过滤掉重复的列,默认是判断全部列。

也可以指定某个或某些列进行重复性判断,如下图

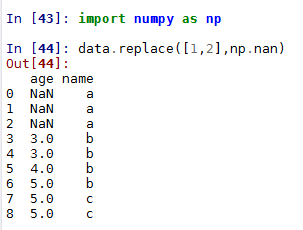
3.3、replace方法
Series和DataFrame的replace方法可以用来替换表格中的数值,如下图,将data的1和2替换成NaN值
3.4、cut函数
pandas的cut函数可以用于数据的离散化,比如针对年龄数据,希望按照不同年龄段划分并计算各年龄段的人数:

cut函数中的第二个参数表示分割区间,pandas的value_counts()函数可以用于计算不同区间的人数
3.5、describe方法
DataFrame的describe方法用于生成数据的基本统计信息如均值、分位数、方差等:

3.6、get_dummies函数
pandas的get_dummies函数主要用于将类别型的变量转化成哑变量(dummy variable),如下图创建一个DataFrame,然后将city列转化成哑变量

将生成的哑变量和其他数据合并:

3.7、groupby方法
DataFrame的groupby方法和SQL的group by语句很像,都是用于聚合。新建一个DataFranme数据,然后根据sex聚合并计算score列的均值:

把mean()换成count()或size()就是计算各个组内样本个数,把groupby里面换成多个数组就可以按照多个数组进行分组:

groupby的方法包括count(),sum(),mean(),median(),min(),max()等都是针对非NA值的计算,另外std(),var()是无偏(分母为n-1)的标准差和方差
groupby也可以传入字典,Series,函数等等,此处不细讲,可以参考书籍
3.8、apply方法
apply是最一般化的GroupBy方法,直接上例子:

桶分析:即可以将数据按照某种分割方式进行分组,然后计算分组信息:先将数据cut成4组

然后groupby可以直接接收cut生成的对象
