云计算深度学习平台架构与实践的必经之路
定义云深度学习平台什么是云深度学习?随着机器学习的发展,单机运行的机器学习任务存在缺少资源隔离、无法动态伸缩等问题,因此要用到基于云计算的基础架构服务。云机器学习平台并不是一个全新的概念,Google、微软、亚马逊等都有相应的服务,这里列举几个比较典型的例子。
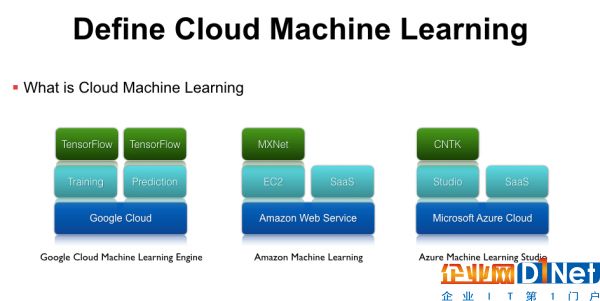
第一个是Google Cloud Machine Learning Engine,它底层托管在Google Cloud上,上层封装了Training、Prediction、Model Service等机器学习应用的抽象,再上层支持了Google官方的TensorFlow开源框架。
亚马逊也推出了Amzon machine learning平台,它基于AWS的Iaas架构,在Iaas上提供两种不同的服务,分别是可以运行MXNet等框架的EC2虚拟机服务,以及各种图象、语音、自然语言处理的SaaS API。
此外,微软提供了Azure Machine Learning Studio服务,底层也是基于自己可伸缩、可拓展的Microsoft Azure Cloud服务,上层提供了拖拽式的更易用的Studio工具,再上面支持微软官方的CNTK等框架,除此之外微软还有各种感知服务、图象处理等SaaS API,这些服务都是跑在Scalable的云基础平台上面。
相关厂商内容
基于卷积神经网络在手机端实现文档检测 阿里巴巴集团千亿级别店铺系统架构平台化技术实践 携程第四代架构之软负载 SLB 实践之路 解读百度PB级数据仓库Palo开源架构 相关赞助商
与100+国内外技术专家探索2017前瞻热点技术
以上这些都是业界比较成熟的云深度学习平台,而在真实的企业环境中,我们为什么还需要实现Cloud Machine Learning服务呢?
首先国外的基础设施并不一定是国内企业可以直接使用的,而如果只是本地安装了TensorFlow,那也只能在裸机上进行训练,本地默认没有资源隔离,如果同时跑两个训练任务就需要自己去解决资源冲突的问题。因为没有资源隔离,所以也做不了资源共享,即使你有多节点的计算集群资源,也需要人工的约定才能保证任务不会冲突,无法充分利用资源共享带来的便利。此外,开源的机器学习框架没有集群级别的编排功能,例如你想用分布式TensorFlow时,需要手动在多台服务器上启动进程,没有自动的Failover和Scaling。因此,很多企业已经有机器学习的业务,但因为缺少Cloud Machine Learning平台,仍会有部署、管理、集群调度等问题。

那么如何实现Cloud Machine Learning平台呢?
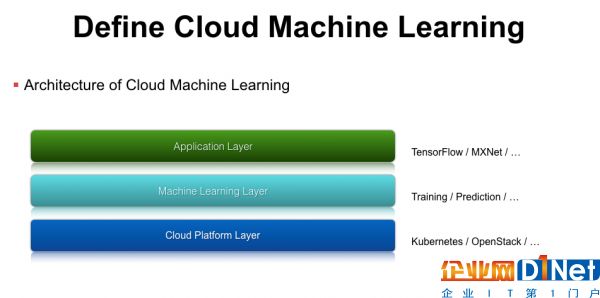
我们对云深度学习服务做了一个分层,第一层是平台层,类似于Google cloud、Azure、AWS这样的IaaS层,企业内部也可以使用一些开源的方案,如容器编排工具Kubernetes或者虚拟机管理工具OpenStack。有了这层之后,我们还需要支持机器学习相关的功能,例如Training、Prediction、模型上线、模型迭代更新等,我们在Machine Learning Layer层对这些功能进行抽象,实现了对应的API接口。最上面是模型应用层,就可以基于一些开源的机器学习类库,如TensorFlow、MXNet等。
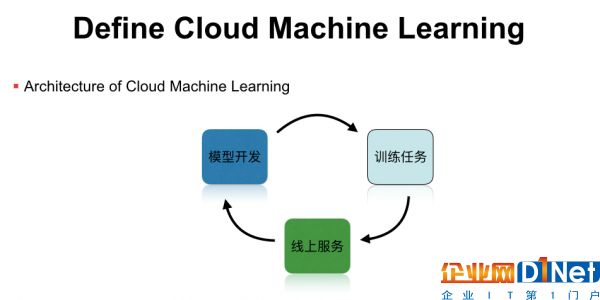
整个Cloud Machine learning运行在可伸缩的云服务上,包行了模型开发、模型训练,以及模型服务等功能,形成一个完整的机器学习工作流。但这并不是一个闭环,我们在实践中发现,线上的机器学习模型是有时效性的,例如新闻推荐模型就需要及时更新热点新闻的样本特征,这时就需要把闭环打通,把线上的预测结果加入到线下的训练任务里,然后通过在线学习或者模型升级,实现完整的机器学习闭环,这些都是单机版的机器学习平台所不能实现的。
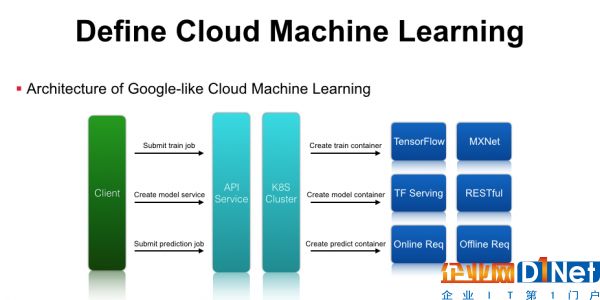
打造云深度学习平台主要包含以下几个组件:首先是客户端访问的API Service,作为服务提供方,我们需要提供标准的RESTful API服务,后端可以对接一个Kubernetes集群、OpenStack集群、甚至是自研的资源管理系统。客户端请求到API服务后,平台需要解析机器学习任务的参数,通过Kubernetes或者OpenStack来创建任务,调度到后端真正执行运算的集群资源中。如果是训练任务,可以通过起一个训练任务的Container,里面预装了TensorFlow或MXNet运行环境,通过这几层抽象就可以将单机版的TensorFlow训练任务提交到由Kubernetes管理的计算集群中运行。在模型训练结束后,系统可以导出模型对应的文件,通过请求云深度学习平台的API服务,最终翻译成Kubernetes可以理解的资源配置请求,在集群中启动TensorFlow Serving等服务。除此之外,在Google Cloud-ML最新的API里多了一个Prediction功能,预测时既可以启动在线Service,也可以启动离线的Prediction的任务,平台只需要创建对应的Prediction的容器来做Inference和保存预测结果即可 。通过这种简单的封装,就可以实现类似Google Cloud-ML的基础架构了。
架构上进行了分层抽象,实现上也只需要三步。
第一步是创建一个Docker镜像,下面的Dockerfile例子是从TensorFlow项目中截取出来的,官方已经提供了一个可以运行的Docker镜像,通过加入定制的启动脚本就可以实现开发环境、模型训练以及模型服务等功能。
第二步是实现一个标准的API服务,下面是一个Python实现的实例,用户发送一个启动训练任务的请求,服务端可以解析请求的参数和内容,并将任务提交到Kubernetes等后端集群中。
第三步是生成Kubernetes所需的文件格式,下面的JSON文件大家也可以在GitHub中找到,实现了将分布式TensorFlow任务提交到Kubernetes集群中运行。
我们通过简单的三个配置就可以完成机器学习任务从本地到云端的迁移过程,也就是实现了Cloud Machine Learning服务。前面提到云深度学习平台需要支持资源隔离和资源共享,这是如何实现的呢,其实Kubernetes本身就有这个抽象,用户可以在请求时申明需要的CPU、内存、甚至是GPU资源,通过cgroups、namespace等容器技术来实现资源隔离,而kube-scheduler实现了资源调度和资源共享等功能。实现自研或者公有云的Cloud Machine Learning平台,开发者可以很容易提交训练任务、创建模型服务等,但在一个真实的机器学习场景中,只解决计算资源的隔离和调度是远远不够的,我们还需要重新思考如何集成数据处理、特征工程等问题。

重新定义云深度学习平台TensorFlow是一个可用于深度学习的数值计算库,基于TensorFlow可以实现MLP、CNN、RNN等机器学习模型,但有了它是不是就不需要Spark呢?他们的关系是什么?
在生产环境中,我们发现TensorFlow并没有完全取代已有的大数据处理工具,我们需要用Spark做数据分析和特征工程,还需要数据仓库等服务去存储和查询结构化数据。TensorFlow是一个非常优秀的深度学习框架,但在真实场景中用户还需要一些PowerGraph处理的图关系特征作为输入,这都是单独一个框架无法解决的。对于用户的建模流程如何组织、如何做数据清洗、如何做特征抽取、如何上线训练好的模型、如何预估模型效果,这些可以使用Azure ML Studio工具去完成,而且是TensorFlow所缺乏的。
前面我们介绍了Cloud Machine Learning,可以实现一个类似Google的分布式、高可用、带集群编排的计算平台,但这远远不够,因为我们还需要使用大数据处理的框架,包括MapReduce、流式处理、图计算等框架。TensorFlow只是整个机器学习流程里面做模型训练其中一部分,我们可能还需要Kubernetes做CPU、GPU的管理和调度。如果我们要完成一个机器学习的业务,就需要同时掌握TensorFlow、Spark、Hadoop、Hive、Kubernetes等框架的原理和应用,而不只是提供一个Google Cloud-ML或者AWS服务就够了,这也是我们要重新定义Cloud Machine Learning的原因。
前面在客观上我们需要这么多知识,但主观上我们希望有什么呢?我们更希望有一个从数据处理到模型训练再到模型上线的一个全闭环服务,而不仅仅是机器学习框架或者通用计算平台,我们希望不写代码就可以做特征抽取的工作,我们希望机器学习的工作流是很容易描述的,而不需要通过编写代码的方式来实现,我们需要一个很灵活的基础架构可以支持各种异构的计算资源,我们希望平台是可拓展的可以实现自动Failover和Scaling。 除了前面提到的Google、微软、亚马逊做的云机器学习平台,我们还需要从IaaS、PaaS、SaaS多维度上提供使用接口,满足不同层次用户的使用需求,另一方面这应该是低门槛的产品服务,让任意的领域专家都可以轻易使用。
后面我们会介绍在真实场景下如何改造Cloud Machine Learning平台,并且介绍第四范式对外提供的低门槛、分布式、高可用的先知机器学习平台。

第四范式的云深度学习实践经验第四范式先知平台是一个基于Cloud的全流程机器学习产品,用户通过Web登陆到先知平台就可以使用模型调研、预估服务的功能,并且可以通过拖拽的方式来描述机器学习的工作流 。
它的使用步骤如下,第一步是数据预处理,用户不需要写Spark代码而只需要拖拽出一个图标,我们称之为一个算子,然后就可以提交数据清洗等数据预处理任务了。通过拖拽数据拆分算子,可以将数据集拆分为训练集和测试集两部分,其中一部分留在左边用于特征抽取。一般来说,用Spark、Mapreduce等开源工具也可以做特征抽取,但对编程技能和工程能力有一定的要求,我们通过定义特征抽取的配置或者脚本,让用户可以不写代码也可以实现对原始数据集的特征工程。然后,连接我们自主研发的高维逻辑回归、高维GBDT等模型训练算子,也可以连接基于开源的TensorFlow或者MXNet等框架实现的算法。最后,经过模型训练得到模型文件后,用刚刚拆分出来的测试集进行模型预测,还可以使用通用的模型评估算子进行AUC、ROC、Logloss等指标的可视化展示。
在先知平台上,用户只需要通过构建流程图的方式,就可以实现数据处理、模型训练等功能,真正解决真实场景下机器学习业务的问题。在先知平台的最新版本中,提供了以极高的效率生成特征工程配置脚本,获取自主研发的LR、GBDT算法的最佳参数等AutoML特性。这些特性能够大幅降低在获取一个有效建模方案过程中的重复性劳动,也可以有效辅助数据科学家获得对数据的初步理解。在一些场景下,能够获得媲美甚至超越专家建模的效果。
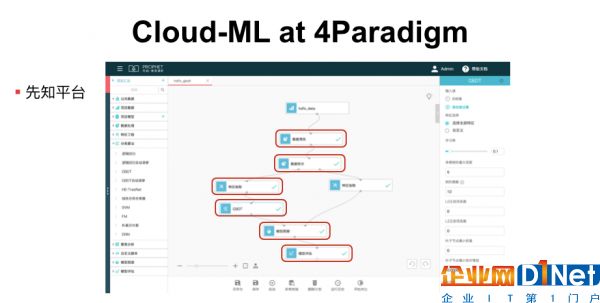
目前先知平台主要解决以下几个目标场景:
1. 简化数据引入,平台不要求数据必须使用分布式存储,也可以直接从RDBMS这类的SQL数据库中导入训练样本数据。
2. 简化数据拆分,用户不需要写Spark代码,只需要提供数据拆分后的存储路径,并且支持按比例拆分或者按规则拆分两种模式。
3. 简化特征抽取,平台支持连续特征、离散特征的抽取和组合,对于连续特征支持自动化的多分桶算法,我们也会归纳常用的特征抽取方法并且封装成脚本或者配置,用户只需了解对应的配置而不需要自己编码实现具体的逻辑。平台还可以根据已有的特征配置自动进行特征组合拓展,提升模型效果。
4. 简化模型训练,平台可以支持开源的机器学习算法实现和第四范式自主研发的超高维度LR算法,这个LR算法实现了Parameter server可以解决几十亿、上百亿特征维度的高速分布式训练问题。对于学习率、正则化参数等可以做到自动调优。另外,平台还提供了线性分形分类器等扩展算法,可以无须人为干预的更加有效利用数值类特征。
5. 简化模型评估,得到模型预估结果后,我们可以计算模型的ROC、Logloss、K-S等指标,不同模型计算指标的方式是类似的,用户就不需要重复编写实现代码,直接通过拖拽算子调用即可,以上都是先知平台所解决的问题。
6. 简化模型上线,对于常见的高维LR/GBDT模型,可以一键发布为线上服务实例,不仅简化了模型的部署和运维,而且上线实例还包括大部分的特征工程逻辑,无须手动再次开发特征处理逻辑的线上版本。

目前,先知平台已经成功应用于银行、金融和互联网等各行各业,基于“先知平台”的反欺诈模型能够帮助银行在毫秒级识别可疑交易,同时在新闻、视频、音频等内容推荐场景下,“先知平台”也成功大幅度提升关键业务指标。此外,在赋能企业利用机器学习升级运营效率的同时,更有意义的是,“先知平台”也极大地降低了机器学习的使用门槛。
作为一个针对全流程机器学习业务的人工智能平台,先知封装了从数据处理、模型训练到模型上线和反馈更新的系统闭环,用户不再需要很强的编程技术和工程能力,领域专家和业务人员都可以通过推拽方式进行建模和上线,帮助企业快速实现从数据收集到业务价值提升的终极目标。

随着专利算法的不断更新,更加实时高效的极致工程优化,未来先知平台将进一步降低人工智能工业应用的门槛,帮助越来越多的企业享受人工智能服务。
本文转自d1net(转载)