中科院计算所沈华伟:图神经网络表达能力的回顾和前沿
2020-06-26 02:19:04

作者 | 蒋宝尚
编辑 | 丛末
6月23日,中科院计算所的研究员、智源研究院的智源青年科学家沈华伟老师在第二届北京智源大会上做了《图神经网络的表达能力》的报告。
在报告中,沈华伟老师提到:这几年,虽然图神经网络在其他领域大量应用,但“内核”仍然停滞不前,目前设计新图神经网络(GNN)的两种常用方式都在面临理论上的瓶颈。
沈华伟老师还对近几年图神经网络表达能力的相关研究进行了梳理,他说:“GNN出现的早期,大家对它表达能力的认识是基于其在半监督学习,尤其是节点分类任务上的优秀表现,一些应用向的研究也只是对图神经网络表达能力经验上的证明”。
基于这个认知,在介绍完图神经网络的基本知识之后,沈华伟老师对图神经网络的表达能力给予了理论上的介绍。
以下是演讲全文,AI科技评论做了不改变原意的整理。 此文经过沈老师修改。

图神经网络过去几年炙手可热,也取得了一系列的突破,但是这两年发展进入了相对停滞的状态。
当前更多的研究员是把图神经网络当做一个工具,也即把图神经网络泛化到其他领域进行应用方向的研究。例如早期图神经网络在节点分类、链路预测以及图分类上取得了一些进展之后,很快就用在了其他领域,包括推荐领域、自然语言处理领域等等。
其实,图神经网络“内核”仍然停滞不前。为什么呢?因为在设计新GNN的时候通常有两种方式:一是经验性的直觉,二是试错。而这两种方式都会面临理论上的瓶颈。
另外,如果只靠试错,那么GNN和深度学习就会同样存在是否“炼金术”的质疑。那么GNN带来的提升究竟来自哪?2019年时,ICLR发表了题为《How powerful are graph neural networks》的文章,掀起了对GNN表达能力的讨论。
1
GNN表达能力的经验性证明
我们今天报告的主题也是讨论GNN的表达能力,看看它到底有什么特色以及限制。
在GNN出现的早期,大家的认识是基于其在半监督学习,尤其是节点分类任务上优秀的性能表现,其中以GCN(图卷积网络 )为代表。
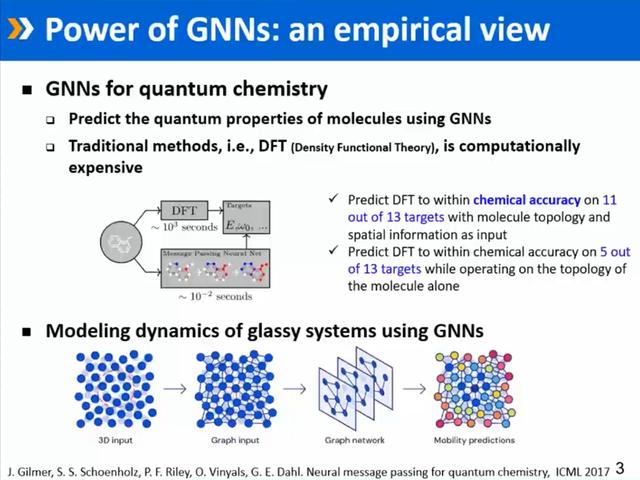
随后,就有研究员将GNN强大的表达能力用在了推理、认知等领域,更有研究员用在了量子化学领域。
例如一个水分子式H2O,它能告诉我们水分子里面有两个氢,一个氧,此表达方式和自然语言处理里面的TF-IDF是一样的,能够看出“词”出现的频次,但没有包含结构信息。
而化学分子式另一种表达,画出结构图的模式相当于把分子结构给理清了,于是,研究员开始思考,这“结构图”是否比原来“频次”方式有更好的表达能力,如果有了表达能力,那能否用包含结构、包含节点的方式对分子式的化学特性进行预测。如果能,表达能力自然得到了证明。
GNN方法对比传统密度泛函的分析方法,在算力方面有大幅度的节省。毕竟,密度泛函的分析用模拟的方式进行计算,通常需要高性能计算机进行操作。在现实情况中,GNN确实做到了化学精度以内的预测,用的就是message passing GNN的方式。
所以,如果能用GNN直接拟合一个模型,从而对任意一个新的分子进行性能预测,自然就体现出来了GNN的表达能力,但这只是经验性表达能力的认识。
另外,在《自然》子刊上,也有一些用GNN建模预测的文章发表,例如预测玻璃的动力学特点、预测地震等等。这些案例也都是对GNN表达能力提供了经验性的认知,我们接下来想从理论的角度讨论GNN的表达能力。
2
GNN基本知识

介绍一下基本的知识,GNN的输入是一张图,图中有节点集合,参数包括V、E、W、X等。GNN早期典型的两类任务是节点分类和图分类,在节点分类任务中,GNN的目的是训练得出网络当中节点的表达,然后根据节点的表达进行下游的任务;在图分类任务中,GNN的目的是要训练得到图的表达,有了图表达之后再对图做分类。在这两个典型的任务中,目前80%、90%的工作都倾向于节点分类,只有少数是图分类。

关于GNN的标准框架,目前用得比较多的是Aggregate+Combine,此框架比较灵活,图分类任务和节点分类任务都适用,其策略方式是通过迭代,用邻居的表示迭代更新自己的表示。策略一共分两步,第一步是聚合邻居信息;第二步是把邻居信息和自己上一轮的信息进行耦合。
下面举几个这种框架的例子,第一个是2017年提出的GraphSAGE,其操作是把邻居的表达进行变换之后,取里面最大的一个赋给自己,然后再把学到的表达和自己上一轮的表达做整合,随后得到新的表达。值得一提的是,GraphSAGE用了Max-pooling的方式,此方式限制了他的表达能力,是导致表达能力丧失关键的一步。
GCN的表达方式直接,将邻居进行特征变换,然后按照矩阵规划进行传递,它的特点是把AGGREGATE和COMBINE两个操作进行了整合。值得注意的是,GCN采用了Mean-pooling的方式,此方式也限制了它的表达能力。另外,GCN的改进版是GAT,其采用的方式是weighted mean pooling。
3
图神经网络的表达能力如何
前面是关于图神经网络基本介绍,现在回到今天的主题:图神经网络的表达能力。我们先讨论2019年发表在ICLR上的《How powerful are graph neural networks》。

首先明确什么是表达能力,所谓表达能力一般有两个方面,第一个方面是表示的空间大小,例如,一个N位的二进制能表达N的二次方个数。这种表达能力旨在表示多少不同的东西,不同的结果。
第二个方面是关于近似能力。例如设计一个神经网络能够近似什么样的函数。值得一提的是,在1989年的时候就有了证明:神经网络的层次只要足够深,就可以逼近任意连续函数。这个“万能近似定理”也解释了为什么深度学习从来不担心表达能力的原因。
但是GNN提出之后,深度学习表达能力的话题又被提起,2017年有研究员发现深度学习的表达能力和深度神经网络的层次是指数关系,假如网络有D层,那么表达能力与“某个数”的D次方成正比,大家感兴趣可以看相关的论文。

GNN引进之后,对于表达能力有什么样的启示呢?如上述左图所示,如果不看结构,节点的标号标1还是标2是区分不开。如果想区分这个不同的“标号1”,需要观察标号的邻居,可以通过邻居信息进行区分。GCN可以把邻居信息进行聚合,提升区分节点的能力。如上图左下所示,在一层GCN操作完成之后,已经可以区分一些标号,但左下图四个“标3”的点还是区分不出来。
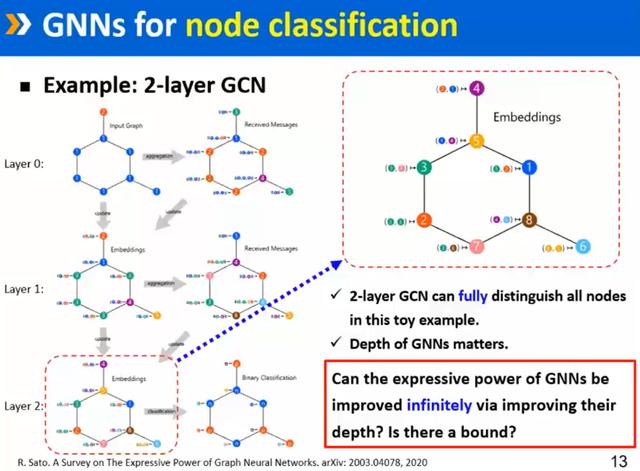
所以,一层GCN区分能力并不够,那能否通过加深层次解决表达能力呢?两层GNN之后,如上图所示,变成了八个点,并可以完全区分开。
所以,如果用两层GCN对上述节点进行分类,无论Label标记成何种方式,GCN的表达能力都能满足分类要求。
上面是两层GCN完全可以区分的例子。回到刚才的问题,把GNN加深就一定能把表达能力做上去吗?也就是说,我们能不能通过深度实现无穷大的表达能力?2019年那篇ICLR文章回答:不可以!
上面是节点的角度,下面从图的角度进行讨论,也即如果把不同的图做成一个表示,GNN表示图的方面表达能力如何。这里有两个关键因素,一个是节点的特征,一个是图的结构,节点的特征刚才已经讲过了,如果把节点做深度神经网络,已经可以帮我们解决掉表达能力问题。

所以,另外一个表达能力的限制就来自于图的结构。
下面看两个简单的例子,左上角的图都是24个碳原子,有两个有机化学的分子式:左边的结构是两层,一层12个碳,24个碳分成平行的两层,都和自己的邻居相连。右边图是24个碳结构变成一个正球体,每个面都由五个碳构成。这两个结构,人一眼就能看出它俩的不同,但是GCN无法区分,即使把层次加深到无穷多层也区分不了它俩。
即使简化成左下角两个更加简单的图,GCN也区分不出来。所以,这给出的启示是:通过提升GCN的深度来提升图的表达能力,是无法做到的。

那么它的表达能力受限在哪儿?既然是图的结构相关,那我们就想到可以采用WL-test,对两个图是否同构进行测试。
WL test 的主要是通过聚合节点邻居的 label,然后通过 hash 函数得到节点新的 label,不断重复知道每个节点的 label 稳定不变。稳定后,统计两张图的label的分布,如果分布相同,则一般认为两张图时同构的。
所以,WL test递归聚合邻居的方式和GNN类似,都是一个递归地来更新自己的特征,只不过更新的方式,WL test做了一个单射函数,但是GNN用的聚合函数,无论是Max、Mean还是Sum,大部分情况下都不是单射的。也就是说GNN非单射的聚合方式,把原本不一样的东西聚合后变得一样了,这让GNN丧失了表达能力。
更直白一些,WL Test是一个单射函数,GNN不是单射函数,于是WL Test为GNN的表达能力提供了一个理论上的上界。(注:这里GNN说的是通过邻居聚合,如果别的聚合方式,性能可能超过WL test的)

为什么当前流行的GNN,例如GCN、GraphSAGE为什么不是单射呢?原因有两个,一个是每层做特征变换做得不够;另一个是,这些图神经网络用的聚合函数天然具有单射属性。
所以,在论文《How Powerful are Graph Neural Networks》中,作者提出来了新的图模型GIN(Graph Isomorphism Network),其中I表示图同构,关键思想是构建了一个单射函数。有了单射函数,GIN也达到了和W L test类似的表达能力,达到了图神经网络表达能力的上界。
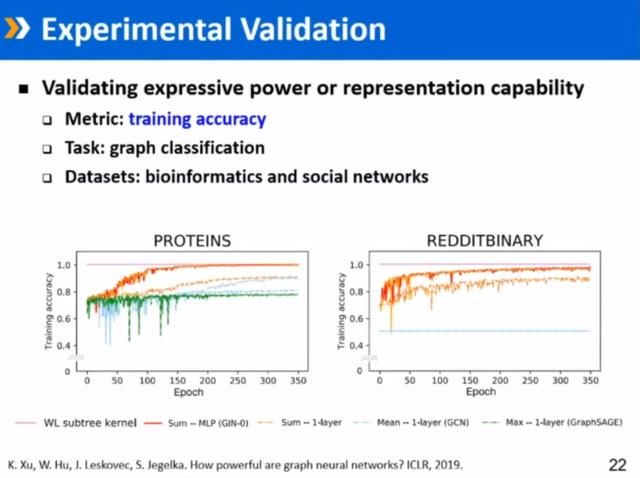
后来作者对GIN模型的表达能力进行了验证,具体是用数据的拟合能力进行测评,验证思想是:如果表达能力足够强,那么数据集上的每个数据都能精确拟合。验证结果确实符合作者的预期,通过构造一个单设的聚合函数,能够实现和WL Test一样的表达能力。

那么,泛化能力如何呢?也即在Test Loss 表现如何呢?这里有一个直观上的事实是,如果Training Loss做得不好,那么Test Loss表现也不会好,毕竟Train是Test的基准,另外,如果训练集上表现非常好,而在测试集上表现非常差,那么就出现过拟合现象,没有泛化能力了。
提出GIN的作者也在论文中证实了,GIN在表达能力上很强,但是在其他任务上,泛化能力还不如表达能力差的模型,如上图GIN在几个数据集上的表现。
所以,这给图神经网络带来的启示是:高的表达能力,并不总意味着对下游任务友好,但是低表达能力总是不好的。综上,我们还是希望构造出一个强表达能力的图神经网络,这是当前学界研究员的共识。
总结一下ICLR 2019那篇论文的工作:首先GNN在理论上有一个表达能力的上界,这个上界是WL Test;为什么是WL Test?因为它的聚合函数是单射;同时这篇论文又提出了GIN这一有着单射聚合函数的图神经网络,并对其表达能力进行了验证。
4
待讨论问题:图神经网络的前沿

那篇文章在2019发表之后,引起了很大的关注,其实后来有很多人进行了讨论,我把这些问题抛在这里,大家讨论一下。
第一个问题,高的表达能力,到底是不是必要的,我们有没有必要构造出这么高表达能力的图神经网络?我们能否做出一个通用的极强表达能力GNN,然后再也不用考虑表达能力这个问题了?
我们现在并没有得到这个问题的答案。对于节点分类,基本上可以提供universal approximitor,对于图分类无法做到,不仅做不到,而且有些场景下表现还特别差。
那么,对于特殊的任务,我们有没有必要构造出高表达能力的东西呢?前面提到,如果表达能力很差,泛化能力肯定不好,表达能力好的,泛化能力也未必好。这在一定程度上也解释了为什么GNN和GraphSAGE聚合函数不是单射,表达能力有限的情况下,为什么还能在一些任务上表现非常棒。
在一些场景下,GNN的大部分表达能力其实用不上。我们真正需要什么呢?我们需要的是它可以把相似的对象,例如相似的节点和图映射成相近的表达。
那么问题又来了,用什么衡量是否相似?所以就有很多度量两个图是否相似的工作。另外,判断一个复杂对象,能不能分解成简单对象进行表达这也是个值得探讨的问题。

第二个问题,关于结构。其实我们都希望GNN学到结构,大家研究GNN这几年,也都明白了GNN在结构上无能为力,只是用结构进行了约束,做了平滑。
举例而言,什么是一个好的图表达?假设一个分子结构图里面有一个苯环,能不能把这个分子式分成苯,还是说分子式中有很多苯环的情况下,才能分成苯。
这个问题的本质,其实在回答我们做的是信息抽取还是相似性度量。如果想做信息抽取,也就是想识别出分子式里面有没有苯结构,现在的GNN做不到这一点,或者必须再设计一些别的方式才能达到。
所以,这两年大家一直在思考,GNN研究的是模式识别,还是说只是图相似性的度量方式。

第三个问题,能不能构造一个更强大的GNN呢?也即表达能力更强大的GNN?关于表达能力,一阶WL Test已经在理论限制突破能力。这两年大家更多的研究方式是把常用的1阶WL Test拓展成K阶,所以就有了KGN的方式。在这样K阶的WL Test方式下,表达方式已经突破1阶的能力,但是成本也比较大,因为需要处理的对象增加了很多。
这种方式给大家起了抛转引玉的作用,给提升GNN表达能力提供了一种思路。但是这种把所有可能都列出来的方式并不是我们所需要的,我们想要的是一个layer-by-layer的网络,也即如果网络每一层非常简单,层次的堆叠是逐渐提升的,然后获得一个更强大的表达能力。
所以,layer-by-layer网络也是未来几年大家应该去探索的一个问题。所以现在我把这个问题抛出来了,你能设计一个这样layer-by-layer的网络,从而获得一个比GNN更强大的表达能力吗?