用户流失预测分析与应用
1 导入库
import pandas as pd
from sklearn.model_selection import train_test_split # 数据分区库
import xgboost as xgb
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score,precision_score, recall_score, roc_curve # 导入指标库
from imblearn.over_sampling import SMOTE # 过抽样处理库SMOTE
import matplotlib.pyplot as plt
import prettytable # 导入表格库
2 读取准备
raw_data = pd.read_csv('classification.csv', delimiter=',') # 读取数据文件
X,y = raw_data.iloc[:, :-1],raw_data.iloc[:, -1] # 分割X,y
3 数据基本审查
n_samples, n_features = X.shape # 总样本量,总特征数
print('samples: {0}| features: {1} | na count: {2}'.format(n_samples, n_features,raw_data.isnull().any().count()))
4 数据预处理
# 填充缺失值
X = X.fillna(X.mean())
# 样本均衡处理
#'''
model_smote = SMOTE() # 建立SMOTE模型对象
X, y = model_smote.fit_sample(X,y) # 输入数据并作过抽样处理
#'''
可以把上面样本均衡的过程注释掉看下样本均衡对结果的巨大影响!
5 拆分数据集
X = pd.DataFrame(X,columns=raw_data.columns[:-1])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=.3, random_state=0) # 将数据分为训练集和测试集
6 XGB分类模型训练
param_dist = {'objective': 'binary:logistic', 'n_estimators': 10,
'subsample': 0.8, 'max_depth': 10, 'n_jobs': -1}
model_xgb = xgb.XGBClassifier(**param_dist)
model_xgb.fit(X_train, y_train)
pre_y = model_xgb.predict(X_test)
7 混淆矩阵
tn, fp, fn, tp = confusion_matrix(y_test, pre_y).ravel() # 获得混淆矩阵
confusion_matrix_table = prettytable.PrettyTable(['','prediction-0','prediction-1']) # 创建表格实例
confusion_matrix_table.add_row(['actual-0',tp,fn]) # 增加第一行数据
confusion_matrix_table.add_row(['actual-1',fp,tn]) # 增加第二行数据
print('confusion matrix \n',confusion_matrix_table)

8 核心评估指标
y_score = model_xgb.predict_proba(X_test) # 获得决策树的预测概率
fpr, tpr, _ = roc_curve(y_test, y_score[:, 1]) # ROC
auc_s = auc(fpr, tpr) # AUC
scores = [round(i(y_test, pre_y),3 )for i in (accuracy_score,precision_score,\
recall_score,f1_score)]
scores.insert(0,auc_s)
core_metrics = prettytable.PrettyTable() # 创建表格实例
core_metrics.field_names = ['auc', 'accuracy', 'precision', 'recall', 'f1'] # 定义表格列名
core_metrics.add_row(scores) # 增加数据
print('core metrics\n',core_metrics)

9 输出特征重要性
xgb.plot_importance(model_xgb,
height=0.5,
importance_type='gain',
max_num_features=10,
xlabel='Gain Split',
grid=False)

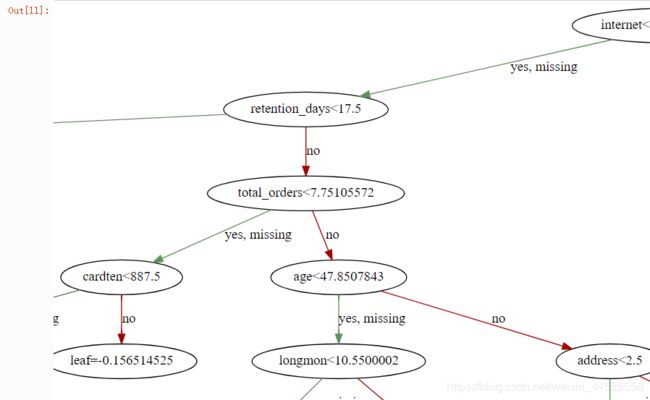
10 输出树形规则图
# ! pip install graphviz 还需要安装graphviz-2.38.msi文件
xgb.to_graphviz(model_xgb, num_trees=1, yes_color='#638e5e', no_color='#a40000')