客户流失预测--基于R语言C5.0
对于中国各大电信运营商而言,在整体市场规模相对稳定的情况下,能否维护好现有的客户是保证其收益的重中之重。因此,预测客户流失的可能性与否,直接关系到运营商的客户维护的重点正确与否。本文将基于”狗熊会“基础案例:收集客户流失,来演示基于C5.0算法的客户流失预测,数据下载 点击打开链接。
一、数据结构查看与初步分析
读入并查看数据(见下图),一共包含10个变量,其中ID为每个用户的唯一标识,在进行预测分析时需要删除;流失用户为因变量,”0“表示未流失,”1“表示已流失。
>customers<-read.csv("customer.csv",stringsAsFactors= FALSE)

查看整体的用户流失情况(见下图),可以发现流失用户数较未流失用户数多

除此之外,我们还可以通过交叉表的形式查看各变量与用户流失与否的关系(见下多图)


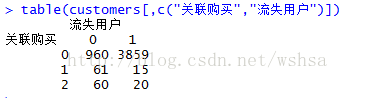


由上图不难发现,签订过服务合约、改变过行为、有过关联购买、集团用户、套餐金额较高的用户有更高的概率不流失;反之,用户流失的概率就相对较高。
同时,我们也可以查看下用户的使用行为,包括使用月数、额外流量和额外通话时长,的分布情况,见下图
>par(mfrow=c(1,3)) ##将画板变为1行3列的样式,让三张图在同一行分布
> hist(customers$使用月数,main = '使用月数分布',xlab = "使用月数",ylab = "频次")
> hist(customers$额外通话时长,main="额外通话时长分布",xlab="额外通话时长",ylab="频次")
> hist(customers$额外流量,main="额外流量分布",xlab="额外流量",ylab="频次")

可见,使用月数以12-14月居多,额外通话时长与额外流量较集中分布。
二、流失预测与模型评价
首先,需要将原始数据随机划分为训练集和测试集
> set.seed(11) ##设置随机可重复
> t_sample<-sample(4975,4000) ##设置训练集抽取随机因子,训练集包含4000条记录
> c_train<-customers[t_sample,] ##抽取训练集
> c_test<-customers[-t_sample,] ##以提出训练集的形式,抽取测试集
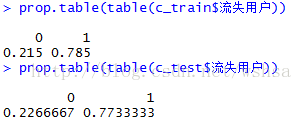
查看训练集和测试集中的记录是否符合随机分布要求,见下图,基本符合随机分布要求
> prop.table(table(c_train$流失用户))
> prop.table(table(c_test$流失用户))
接着,利用C5.0决策树算法进行训练
> c_train<-c_train[-1]
> c_test<-c_test[-1]##去掉id
library(C50)
> c_model<-C5.0(c_train[-9],c_train$流失用户) ##c_train 要剔除类变量“流失用户”
> summary(c_model) ##查看树

由上图可知,该树共有7各分支,并且准确划分了当中的3965条记录,错误率仅是0.9%。
下面用测试集对模型 c_model 进行评估
> c_t_model<-predict(c_model,c_test)
> table(c_test$流失用户,c_t_model) ##利用交叉表查看预测的准确率情况

可见,该模型的预测准确率在98.15%以上,仅18个预测出错,其中是流失用户的被预测为非流失的有4个,非流失用户被预测为流失用户的有14。
再接下来,尝试下优化模型(见 点击打开链接 ,内有两种优化模型的方法)
自适应增强算法是通过将很多能力较弱的学习算法组合在一起,使得这样的组合算法比任何单独的算法都强很多。在C5.0算法中,可以通过参数 trials,引入boosting算法,表示在模型中使用的独立决策树的数量。
> c_model_boost10<-C5.0(c_train[-9],c_train$流失用户,trials = 10) ##trials=10 已经成为一个事实标准的数字
> c_t_model_b<-predict(c_model_boost10,c_test)
> table(c_test$流失用户,c_t_model_b)

预测准确率上升到98.46%,上述幅度不明显。但流失用户的被预测为非流失的有6个,比原来的模型多了2个,而将流失用户的被预测为非流失的代价更大(可通过添加代价矩阵解决,见 点击打开链接),故该优化效果不明显。